







一.机械学习
1.机械学习
(1)通过设计一种算法提取数据中的规律,从而训练出一种模型。计算机可以通过训练出来的模型对任务进行预测。
(2)如果输入机器的数据带有标签,则称为有监督学习。
(3)如果输入的数据没有标签,则称为无监督学习。

2.回归问题
(1)回归,我第一次看到回归的时候,想的就是回归是什么意思?后来看了一个答案解释很有意思,回归这个词来自于生物学,在调查父母与子代身高问题的时候,发现父母如果过高的话,子女就会比父母矮一点,如果父母矮的话,子女又会比父母高,这使得身高不会向高矮俩个极端发展,而是趋于回到中心,后来做统计的时候引入统计学,回归就是数据会向平均值靠拢,更确切地说,数据的分布遵循着某种规律,数据都会向这个规律靠近,就好比我们做事都有一个原则,我们每做一件事的时候,都会想想这个原则,做出的事尽量不会偏离这个原则。而我们要做的就是找出这些数据的规律,并用数学表示出这个规律。
回归具体表现在数据中会是什么样的呢?我们来看分类的数据都是什么样,分类数据的类别必然是离散的,因为分类本质上就是找出决策边界,这个边界可能是线性的(这个边界是个直线),也有可能是非线性的(这个边界是弯弯曲曲的),有边界的前提就是类别一定是有限的,比如测身高,有监督(分类)模型可以找出决策边界告诉我们这个人是高还是矮,但是它一定得不到这个人的具体身高是多少,具体身高是一个连续值,不再被边界所束缚了(具体身高也就不再是离散的了,属于回归性的问题),但是之前也说过身高不会随便乱发展,它也遵循着一种规律,那么找出回归规律,对身高规律进行建模,之后计算就能得到身高,这就是回归问题了。
简单来说的话,回归数据的类别都是连续的,分类数据的类别都是离散的。
我们可以用回归模型来得到具体身高,在现代很高女生认为180以上就是高,以下就是矮,我们就可以使用得到的具体身高来按照这个标准判断这个人是高还是矮,那么也就是说给一个阈值的话,就可以将回归应用到分类中。
那么现在的问题就是怎样找出这个规律?在生活中,规律是说大部分人的行为是符合一种特定的行为,那么我们只要让大部分数据符合我们建立的模型就行,但是我们知道数据不可能百分之一百符合,只能说是一种拟合,拟合就会有误差,很自然就可以想到当所有数据误差最小时的模型就是我们想要的模型,这也是一种权衡,选择出距离所有的点之和最短的那条线。那么问题就变成了模型如何表示?用数学上的线性和非线性函数来建立,而其中线性回归就是用线性函数来解决回归问题。
(2)线性回归
线性函数来解决回归问题,说白了就是用一条直线来拟合所有数据,并且使整体拟合误差最小。图1就是一个线性回归图示,用整体误差最小的直线作为回归方程,而这种选择出距离所有的点之和最短的那条线也被称为最小二乘法。

(3)个人的理解
回归问题就是定量问题。定量输出称为回归或者说是对连续变量的一个预测。
比如身高,在一个范围内(如0-200cm)身高是连续的,我们利用训练出来的模型进行预测,如一个函数,输入数据X0,输出一个身高,而身高就是一个具体的值。这个值是满足我们所发现的规律的(也就是我们通过机械学习找到的规律)(也就是我们函数的映射关系),而输出的值就是一个回归值,平均值。
假设一个X0,在这个X0上分布着很多身高,但是这些身高总是会稳定在我们的模型周边,而我们的模型输出的F(X0)就是这些数据的平均值。(由于数据的多少,平均值存在差异,也就是存在误差。所以,随着数据的增加,平均值会更加准确,我们得到的回归值也就更加合理,因此,我们需要不断对我们的模型进行优化,这就是为什么需要学习。)
3.分类问题
(1)机器学习中另一个重要的任务——分类(classification),即找一个函数判断输入数据所属的类别,可以是二类别问题(是/不是),也可以是多类别问题(在多个类别中判断输入数据具体属于哪一个类别)。与回归问题(regression)相比,分类问题的输出不再是连续值,而是离散值,用来指定其属于哪个类别。分类问题在现实中应用非常广泛,比如垃圾邮件识别,手写数字识别,人脸识别,语音识别等。
————————————————
原文链接:https://blog.csdn.net/hohaizx/article/details/81835381
(2)分类是监督学习的一个核心问题,在机器学习中,最常见的问题就是分类(classification)问题。
在机器学习中,分类问题是基础,其它很多的应用都可以从分类的问题演变而来,同时很多问题也可以转化为分类的问题,比如图像中的图像分割,最简单的实现方法就是对每一个像素进行分类,在自然场景的分割中,我们判断这个像素点是不是房子的一部分,如果是的话,那么其标签就是房子。
(3)在机器学习中,我们把能完成分类任务的算法称之为分类器(classifier)。评价一个分类器的好坏,最常见的指标就是准确率(accuracy),准确率是指被分类器分类数据正确占所有分类数据的百分比。
(4)个人总结
分类问题是定性问题,是对离散变量的预测。
分类问题可以是二分类,也可以是多分类的问题。
对于分类问题的解决,我们通常通过函数来实现分类,但对于复杂的分类问题,函数结果往往会有错误,这时我们可以定义一个损失函数来评估我们的模型。接着找出使损失函数最小的最优函数以使得我们的误差降到最低。
(5)解决分类问题的基本步骤
1、确定一个模型f ( x ) f(x)f(x),输入样本数据x xx,输出其类别;
2、定义损失函数L ( f ) L(f)L(f),一个最简单的想法是计数分类错误的次数;
3、找出使损失函数最小的那个最优函数。
————————————————
版权声明:本文为CSDN博主「zxhohai」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hohaizx/article/details/81835381

4.深度学习中的超参数
(1)参数与超参数的区别
参数是在机械学习中,有数据进行调控的参数,如卷积核的核参数。
(参数:就是模型可以根据数据可以自动学习出的变量,应该就是参数。比如,深度学习的权重,偏差等。)
超参数是在机械学习之前,人为调控的参数,超参数不由数据进行调控,如卷积核的尺寸,数量。
(超参数:就是用来确定模型的一些参数,超参数不同,模型是不同的(比如说:假设都是CNN模型,如果层数不同,模型不一样,虽然都是CNN模型。),超参数一般就是根据经验确定的变量。在深度学习中,超参数有:学习速率,迭代次数,层数,每层神经元的个数等等。)
(2)超参数的类别
网络参数:可指网络层与层之间的交互方式(相加、相乘或者串接等)、卷积核数量和卷积核尺寸、网络层数(也称深度)和激活函数等。
优化参数:一般指学习率(learning rate)、批样本数量(batch size)、不同优化器的参数以及部分损失函数的可调参数。
正则化:权重衰减系数,丢弃法比率(dropout)。
5.网络搭建
(1)构成
①全连接层

全连接层的每层神经元都与上一层的所有神经元进行全连接。
全连接层可以整合卷积层或者池化层中具有类别区分性的局部信息。
②卷积层

对于2维数据(具有长与高的属性)的卷积运算。
它们由输入数据,滤波器,(偏置) ,输出数据组成。
卷积运算:以一定间隔滑动滤波器的窗口并应用,将各个位置上滤波器的元素和输入数据的对应元素相乘,再求和。将结果保存到输出的对应位置,再将这个过程在所有位置都进行一遍,就可以得到卷积运算的结果。
步幅(步长):步幅指滤波器窗口在输入数据上的移动距离,当步幅为1时,窗口向左右或者上下移动一格的距离,并进行卷积运算,直到走遍输入数据的所有位置。
填充:由于步幅的不同,可能会造成滤波器窗口一部分超出输入数据的窗口,此时,我们就需要进行填充。在输入数据的窗口周围填充几层0,以弥补滤波器的超出部位。(其余步骤不变,依旧进行卷积运算。)
对于3维数据(具有长,高与通道数的属性)的卷积运算

需要注意:滤波器的通道数应与输入数据的通道数一致。
运算:当通道方向上有多个特征图时,如下图

我们只需将特征图与对应滤波器的通道进行2维卷积运算,最后将输出进行对应位置的求和就可以。
对于多滤波器

滤波器变为4维数据(长,高,通道数,个数) 。
运算:由图可知,N个滤波器分别与输入进行运算,得到的输出的通道数就为N。
批处理
就是对N个数据的处理

数据作为4维的形状在各层间传递。这里需要注意的是,网络间传递的是4维数据,对这N个数据进行了卷积运算。也就是说,批处理将N次的处理汇总成了1次进行。
③池化层
池化层是当前卷积神经网络中常用组件之一,它最早见于LeNet一文,称之为Subsample。自AlexNet之后采用Pooling命名。池化层是模仿人的视觉系统对数据进行降维,用更高层次的特征表示图像。
实施池化的目的:(1) 降低信息冗余;(2) 提升模型的尺度不变性、旋转不变性;(3) 防止过拟合
除了卷积层,卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性。
举例:
池化层的常见操作包含以下几种:最大值池化,均值池化,随机池化,中值池化,组合池化等。
最大值池化
最大值池化是最常见、也是用的最多的池化操作。最大值池化的核心代码可以描述为:
(图片来源:深度学习入门之池化层 - 知乎 (zhihu.com))
// 摘选自caffe并稍加修改. top_data = -FLT_MAX; for (int h = hstart; h < hend; ++h) { for (int w = wstart; w < wend; ++w) { const int index = h * width_ + w; if (bottom_data[index] > top_data[pool_index]) { top_data = bottom_data[index]; } } }
计算:
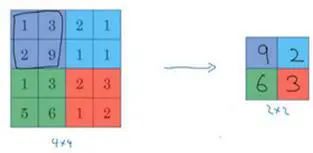
输入为4X4的矩阵,执行最大池化的树池是2X2的矩阵 。
把4X4矩阵拆分,提取区块中的最大值,对于2X2的输出,对应颜色的输出值都是对应区域的最大值(如上图)。(图片来源:吴恩达深度学习笔记(79)-池化层讲解(Pooling layers) - 简书 (jianshu.com))
这就像是应用了一个规模为2的过滤器,因为我们选用的是2×2区域,步幅是2,这些就是最大池化的超参数。
④激活函数
什么是激活函数?
如图1,在神经元中,输入的 inputs 通过加权,求和后,还被作用了一个函数,这个函数就是激活函数。引入激活函数是为了增加神经网络模型的非线性。如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,这种情况就是最原始的感知机(Perceptron)。激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。

















 2979
2979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











