







本文目标
对于猫12目标检测部分的数据集,采用网络爬虫来制作数据集。
在网络爬虫中,经常需要下载大量的图片。为了提高下载效率,可以使用多线程来并发地下载图片。本文将介绍如何使用Python编写一个多线程爬虫程序,用于爬取图片并进行下载。
程序讲解
首先,我们需要导入所需的库,包括requests、PIL、lxml、numpy和threading。其中,requests库用于发送HTTP请求,PIL库用于处理图片,lxml库用于解析HTML,numpy库用于处理数组,threading库用于实现多线程。
import time
import requests
from lxml import etree
import numpy as np
import threading接下来,我们定义了一个函数searchImageurls,用于从指定网站上搜索图片的URL。在这个例子中,我们以https://www.hippopx.com/zh 为例。函数中,我们使用requests库发送HTTP请求,获取网页内容,并使用lxml库解析HTML,提取图片的URL。最后,我们将URL存储在一个数组中,并返回该数组。
def searchImageurls():
ImageUrls = []
for i in range(1, 6):
url = f"https://www.hippopx.com/zh/query?q=cat&page={i}"
response = requests.get(url, headers=headers)
html = response.content.decode('utf-8')
tree = etree.HTML(html)
# print(tree)
image_url = tree.xpath('//*[@id="mainlist"]/li/figure/a/img/@src')
ImageUrls.append(image_url)
ImageUrls = np.array(ImageUrls)
ImageUrls = ImageUrls.flatten()
return ImageUrls然后,我们定义了一个函数download_image,用于下载图片。在这个函数中,我们使用requests库发送HTTP请求,获取图片的内容,并使用PIL库将内容保存为图片文件。如果下载失败,我们会进行最大重试次数的重试。
def download_image(url, filename):
max_retries = 3 # 最大重试次数
retries = 0
while retries < max_retries:
try:
response = requests.get(url)
with open(filename, 'wb') as f:
f.write(response.content)
print(f"Downloaded {filename}")
break # 下载成功,跳出循环
except requests.exceptions.ConnectionError as e:
print(f"Connection error: {e}")
retries += 1
time.sleep(1) # 等待1秒后重试
if retries == max_retries:
print(f"Failed to download {filename}")在主函数中,我们首先调用searchImageurls函数获取图片的URL数组。然后,我们创建多个线程,并将每个线程分配一个URL进行下载。最后,我们等待所有线程完成下载。
最后,我们输出下载完成的消息。
if __name__ == '__main__':
ImageUrls = searchImageurls()
threads = []
print("开始下载")
for i, url in enumerate(ImageUrls):
filename = f'./images/cat{i + 1}.jpg'
thread = threading.Thread(target=download_image, args=(url, filename))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
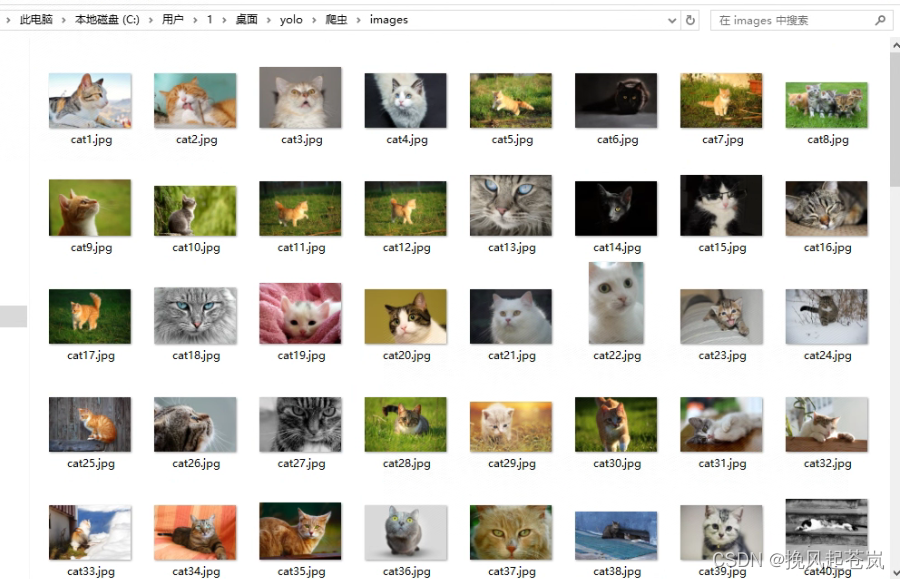
print("全部下载完毕")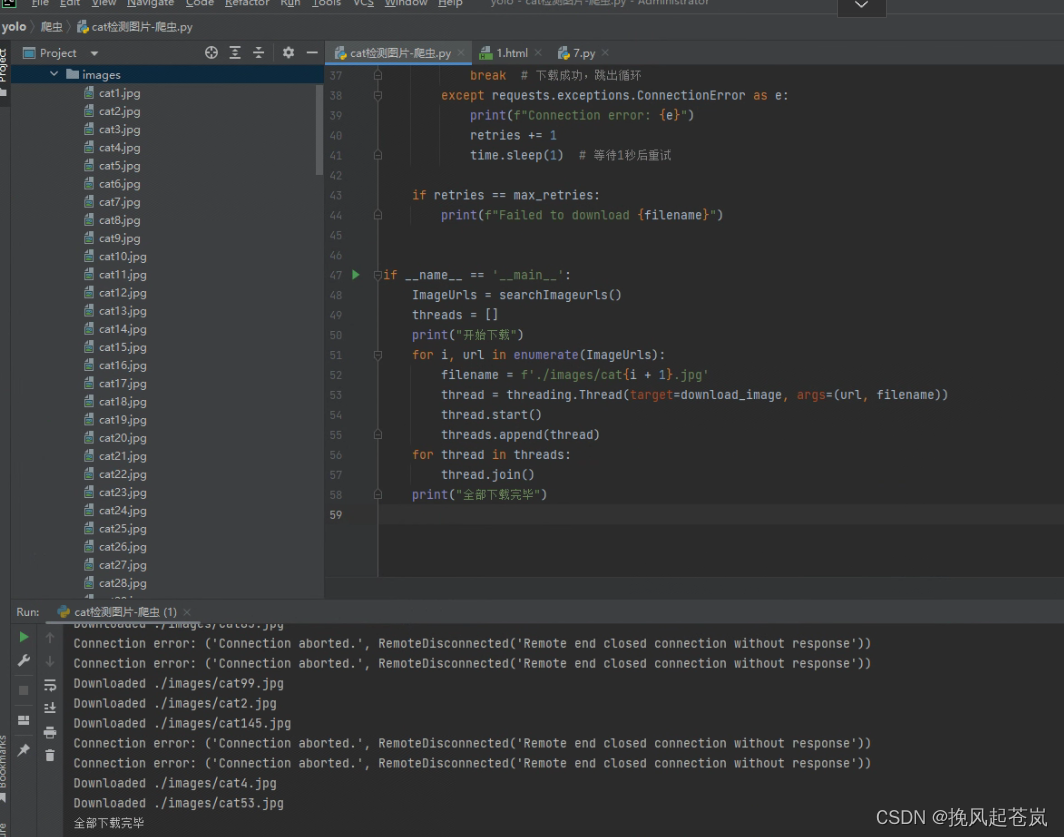
注:Connection error: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) -- 这是由于错误的url导致的
完整代码
import time
import requests
from lxml import etree
import numpy as np
import threading
# 爬取的图片网站 https://www.hippopx.com/zh
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"}
def searchImageurls():
ImageUrls = []
for i in range(1, 6):
url = f"https://www.hippopx.com/zh/query?q=cat&page={i}"
response = requests.get(url, headers=headers)
html = response.content.decode('utf-8')
tree = etree.HTML(html)
# print(tree)
image_url = tree.xpath('//*[@id="mainlist"]/li/figure/a/img/@src')
ImageUrls.append(image_url)
ImageUrls = np.array(ImageUrls)
ImageUrls = ImageUrls.flatten()
return ImageUrls
# 图片下载
def download_image(url, filename):
max_retries = 3 # 最大重试次数
retries = 0
while retries < max_retries:
try:
response = requests.get(url)
with open(filename, 'wb') as f:
f.write(response.content)
print(f"Downloaded {filename}")
break # 下载成功,跳出循环
except requests.exceptions.ConnectionError as e:
print(f"Connection error: {e}")
retries += 1
time.sleep(1) # 等待1秒后重试
if retries == max_retries:
print(f"Failed to download {filename}")
if __name__ == '__main__':
ImageUrls = searchImageurls()
threads = []
print("开始下载")
for i, url in enumerate(ImageUrls):
filename = f'./images/cat{i + 1}.jpg'
thread = threading.Thread(target=download_image, args=(url, filename))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
print("全部下载完毕")
















 3074
3074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











