






 本文详细介绍了如何使用Yolov5深度学习框架对舌象进行目标分类。从背景和目的出发,阐述了数据集准备、数据预处理、模型训练和预测的过程,包括XML转TXT、编写yaml配置文件以及训练和预测的命令行操作。文章以TCMID-Tongue数据集为例,展示了如何进行五分类任务,以提升中医诊断的效率和准确性。
本文详细介绍了如何使用Yolov5深度学习框架对舌象进行目标分类。从背景和目的出发,阐述了数据集准备、数据预处理、模型训练和预测的过程,包括XML转TXT、编写yaml配置文件以及训练和预测的命令行操作。文章以TCMID-Tongue数据集为例,展示了如何进行五分类任务,以提升中医诊断的效率和准确性。
目录
4 .1 、 xml文件转txt文件(编写一个xml转txt脚本 xml2txt.py)
4.3.1 、编写 yaml文件1(里面存放训练、测试、预测路径 、分类的数量、分类的目标标签)
4.3.2 、编写 .yaml 文件二, 在models 目录下 复制(使用什么模型就复制哪个)一份 模型yaml文件(记录一些权重参数)
一、 使用yolov5 进行舌象目标分类的背景和目的
背景:舌象是中医诊断学的一项重要内容,也是应用传统经验、辅助医生指导医治疾病的方法之一。随着计算机视觉技术的发展,将舌象数字化并进行自动化分析已成为研究热点。其中,舌象目标分类任务是舌诊图像处理的一个重要步骤。
目的:深度学习技术在舌象分类任务上表现优异。其中,YoloV5 是一种基于 PyTorch 实现的深度学习目标检测框架。相比其他目标检测框架,YoloV5 具有模型轻量、速度快、检测精度高等优点。因此,使用 YoloV5 进行舌象目标分类任务,可以帮助中医医生快速准确地进行舌象诊断,提高中医诊断的精度和效率。
二、 任务步骤:
Yolov5作为目标检测框架,首先需要进行训练。下面是使用yolov5进行舌象目标分类任务的流程:
1. 数据集准备:收集标注好的舌诊图像数据集,并将其制作成 Yolov5 能够处理的格式,比如 COCO 格式。
2. 模型选择:根据数据集情况和任务需求,选择合适的 Yolov5 模型进行训练,例如 Yolov5s、Yolov5m、Yolov5l 等不同规模的模型。
3. 模型训练:利用所选模型对准备好的舌象图像数据集进行训练,训练过程需要注意合适的超参数设置(如学习率等)以及数据增强手段的运用(如随机裁剪、旋转等)。
4. 模型验证:使用测试集验证模型的准确率、召回率等指标,并根据评估结果反复调整模型参数。
5. 模型部署:在实际应用中,把训练好的模型部署到相应的平台上面,这需要对框架进行适当的修改来保证其与部署环境完全兼容。
值得注意的是,在进行舌象目标分类任务时,需要特别关注模型的分类结果是否符合中医常识。因为在现实舌诊中,不同类型的舌象可能存在相互重叠、混杂等情况,所以模型的设计和训练需要考虑到这方面特殊性。
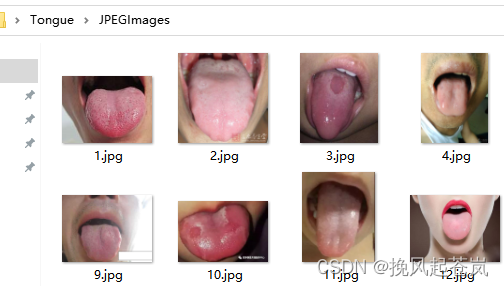
三 、数据集的准备(TCMID-Tongue):
TCMID-Tongue(中医药信息数据库-舌象数据集)是由中国中医科学院中药研究所提供的,是一个主要用于中医诊断的公开舌象图像分类数据集。该数据集收集了1040张高分辨率的舌象图像,并涵盖了17种不同类型的舌象,包括苔质、暗红、淡红等。每张图片都配有对应的文字描述以及标签。
此次数据集(Tongue.zip)收集了1472张高分辨率的舌象图像以及对应的标签。

目标:利用yolov5 进行五分类任务、训练出一个模型测试数据。
分类目标:Mirror-Approximated、Thin-white、White-Greasy、Yellow-Greasy、Grey-Black (镜像近似,薄白,白油腻,黄油腻,灰黑 )
四 、数据预处理:
4 .1 、 xml文件转txt文件(编写一个xml转txt脚本 xml2txt.py)
代码如下:
import os
import xml.etree.ElementTree as ET
ANNOTATIONS_DIR = 'C:\\Users\\Administrator\\Desktop\\Annotations' # xml标签目录路径
# CLASSES_FILE = "path_to_classes_file"
YOLO_OUTPUT_DIR = 'C:\\Users\\Administrator\\Desktop\\labels' # 生成的txt标签目录路径
classes = ['Mirror-Approximated', 'Thin-White', 'White-Greasy', 'Yellow-Greasy', 'Grey-Black']
# with open(CLASSES_FILE, "r") as f:
# classes = [line.strip() for line in f.readlines()]
if not os.path.exists(YOLO_OUTPUT_DIR):
os.makedirs(YOLO_OUTPUT_DIR)
for filename in os.listdir(ANNOTATIONS_DIR):
if not filename.endswith(".xml"):
continue
xml_file_path = os.path.join(ANNOTATIONS_DIR, filename)
tree = ET.parse(xml_file_path)
root = tree.getroot()
size = root.find("size")
if size is None:
print(f"Annotation file {filename} has missing size information. Skipping...")
continue
width = int(size.find("width").text)
height = int(size.find("height").text)
if width <= 0 or height <= 0:
print(f"Image in {filename} have invalid size ({width}*{height}). Skipping...")
continue
output_filename = os.path.splitext(filename)[0] + ".txt"
output_file_path = os.path.join(YOLO_OUTPUT_DIR, output_filename)
with open(output_file_path, "w") as out_file:
for obj in root.iter("object"):
class_name = obj.find("name").text
if class_name is None or class_name not in classes:
print(f"Object {obj} in {filename} has invalid category name {class_name}. Skipping...")
continue
class_index = classes.index(class_name)
bndbox = obj.find("bndbox")
if bndbox is None:
print(f"Object {obj} in {filename} has missing bounding box information. Skipping...")
continue
x_min = int(bndbox.find("xmin").text)
y_min = int(bndbox.find("ymin").text)
x_max = int(bndbox.find("xmax").text)
y_max = int(bndbox.find("ymax").text)
if x_min >= x_max or y_min >= y_max or x_min < 0 or y_min < 0 or x_max > width or y_max > height:
print(
f"Object {obj} in {filename} has invalid bounding box coordinates ({x_min},{y_min})-({x_max},{y_max}). Skipping...")
continue
x_center = (x_min + x_max) / 2 / width
y_center = (y_min + y_max) / 2 / height
w = (x_max - x_min) / width
h = (y_max - y_min) / height
out_file.write("{} {:.6f} {:.6f} {:.6f} {:.6f}\n".format(class_index, x_center, y_center, w, h))
运行后的效果:
4.2 生成数据集数据的图片路径
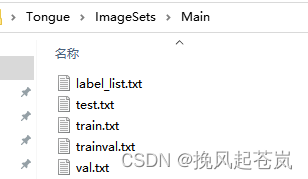
查看该目录发现,这里记录了一些,需要分类的标签和训练、测试、预测的目标。
但是训练、测试、预测所加载的txt文件记录的不是图片的路径,因此,需要手动去编写 图片的路径。
如: 
编写一个python脚本去自动生成路径
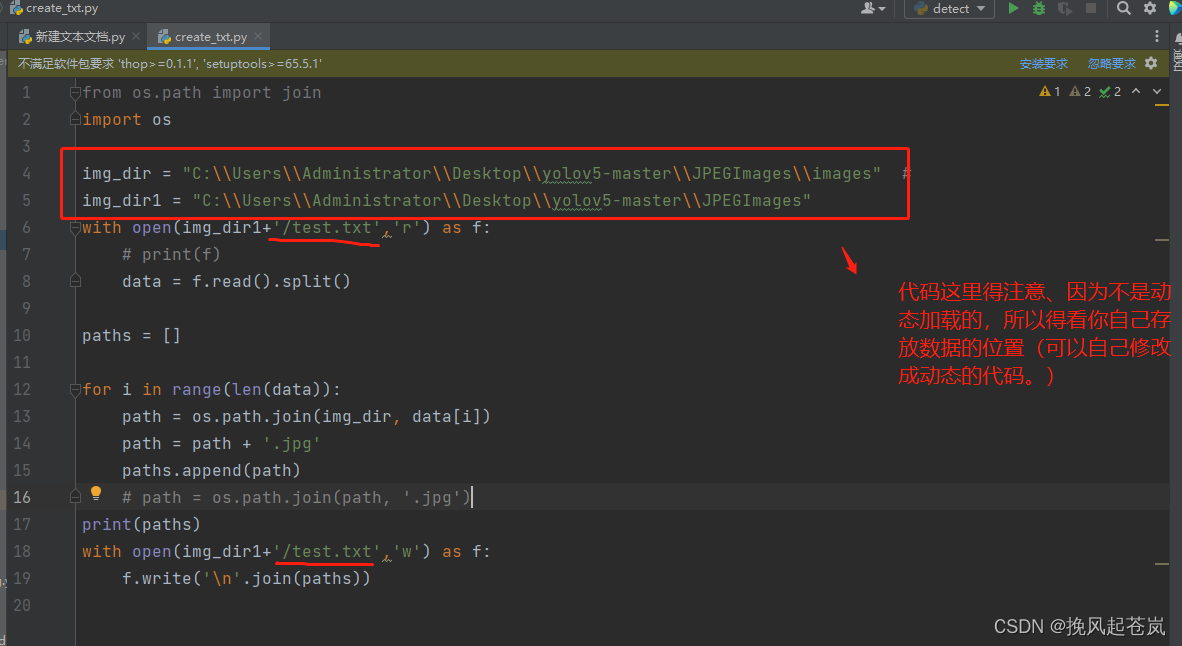
代码如下:
import os
img_dir = "C:\\Users\\Administrator\\Desktop\\yolov5-master\\JPEGImages\\images" #
img_dir1 = "C:\\Users\\Administrator\\Desktop\\yolov5-master\\JPEGImages"
with open(img_dir1+'/test.txt','r') as f:
# print(f)
data = f.read().split()
paths = []
for i in range(len(data)):
path = os.path.join(img_dir, data[i])
path = path + '.jpg'
paths.append(path)
# path = os.path.join(path, '.jpg')
print(paths)
with open(img_dir1+'/test.txt','w') as f:
f.write('\n'.join(paths))
运行后的效果: 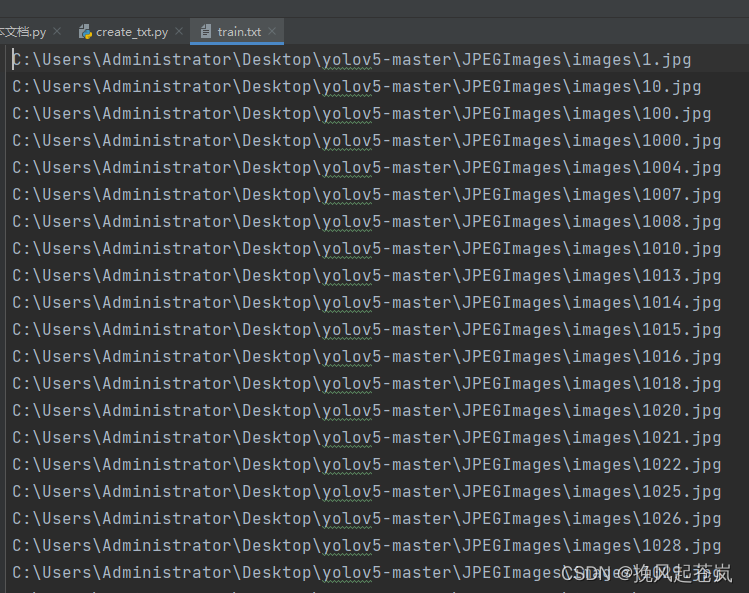
4.3 、编写yaml 文件
4.3.1 、编写 yaml文件1(里面存放训练、测试、预测路径 、分类的数量、分类的目标标签)
一般放在data目录(也可以自定义)下
示例如下:
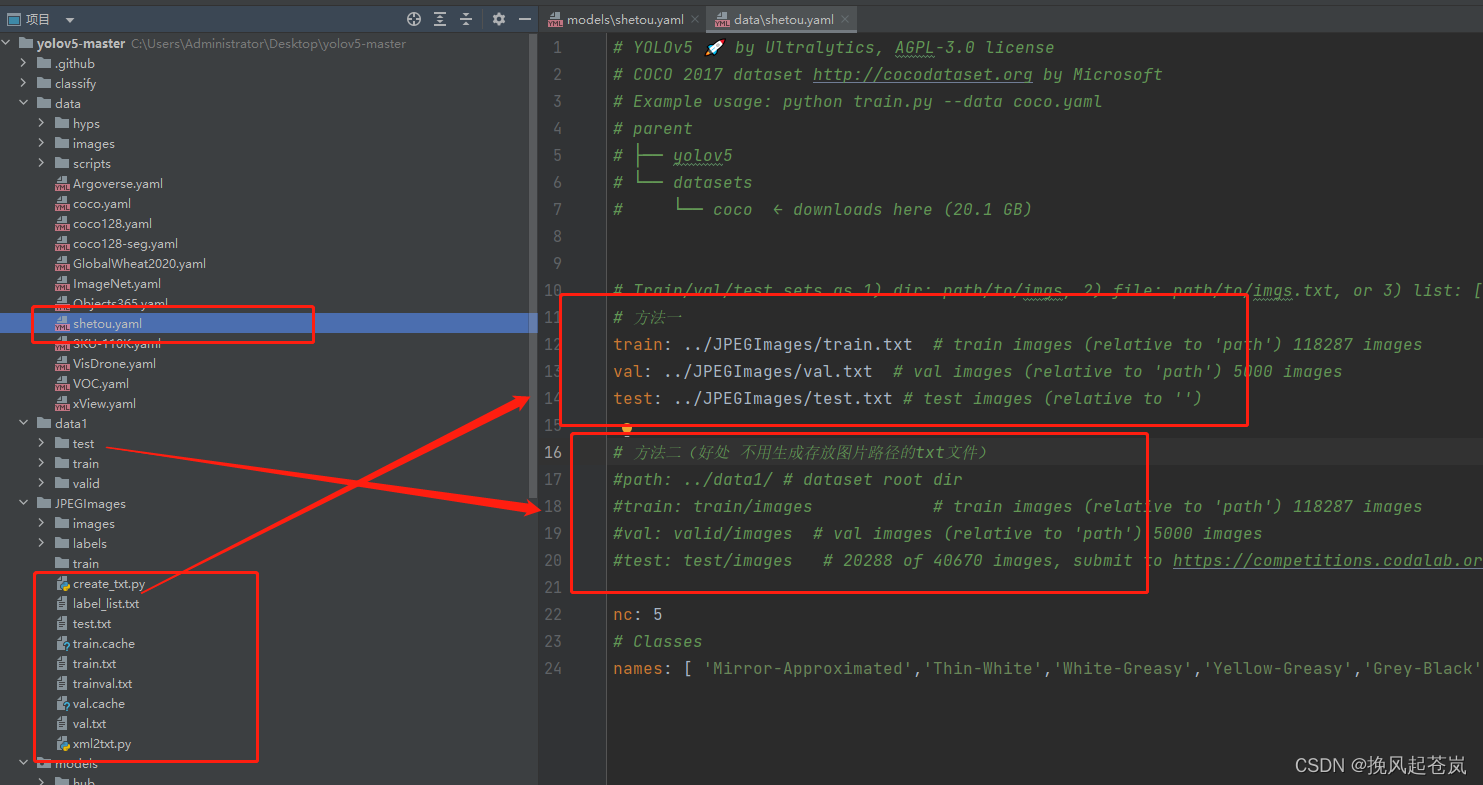
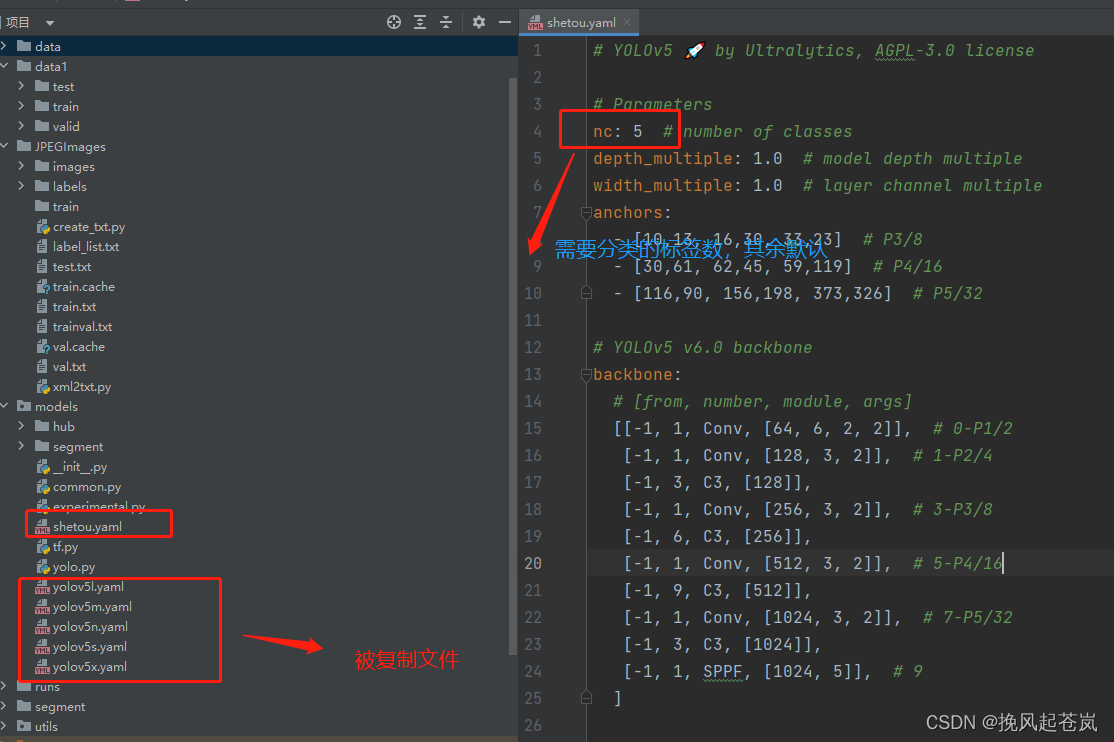
4.3.2 、编写 .yaml 文件二, 在models 目录下 复制(使用什么模型就复制哪个)一份 模型yaml文件(记录一些权重参数)
将复制的模型yaml放到指定目录(一般还是放在models下面)
示例如下:
五 、训练和预测:
5.1 、开始训练(train.py)
5.1.1 、方法一:命令行方式
python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml --batch-size 128
yolov5s 64
yolov5m 40
yolov5l 24
yolov5x 5.1.2 、方式二:修改train.py 一键运行

运行如下:
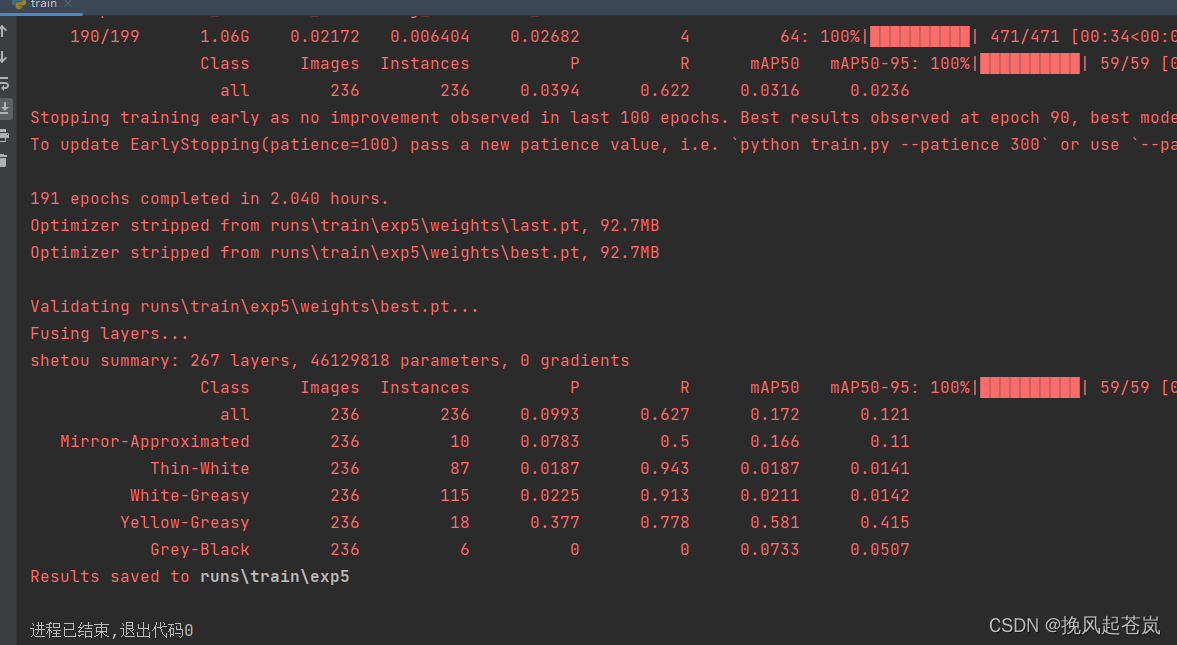

查看结果图、和训练过程分析文件。(runs目录下)
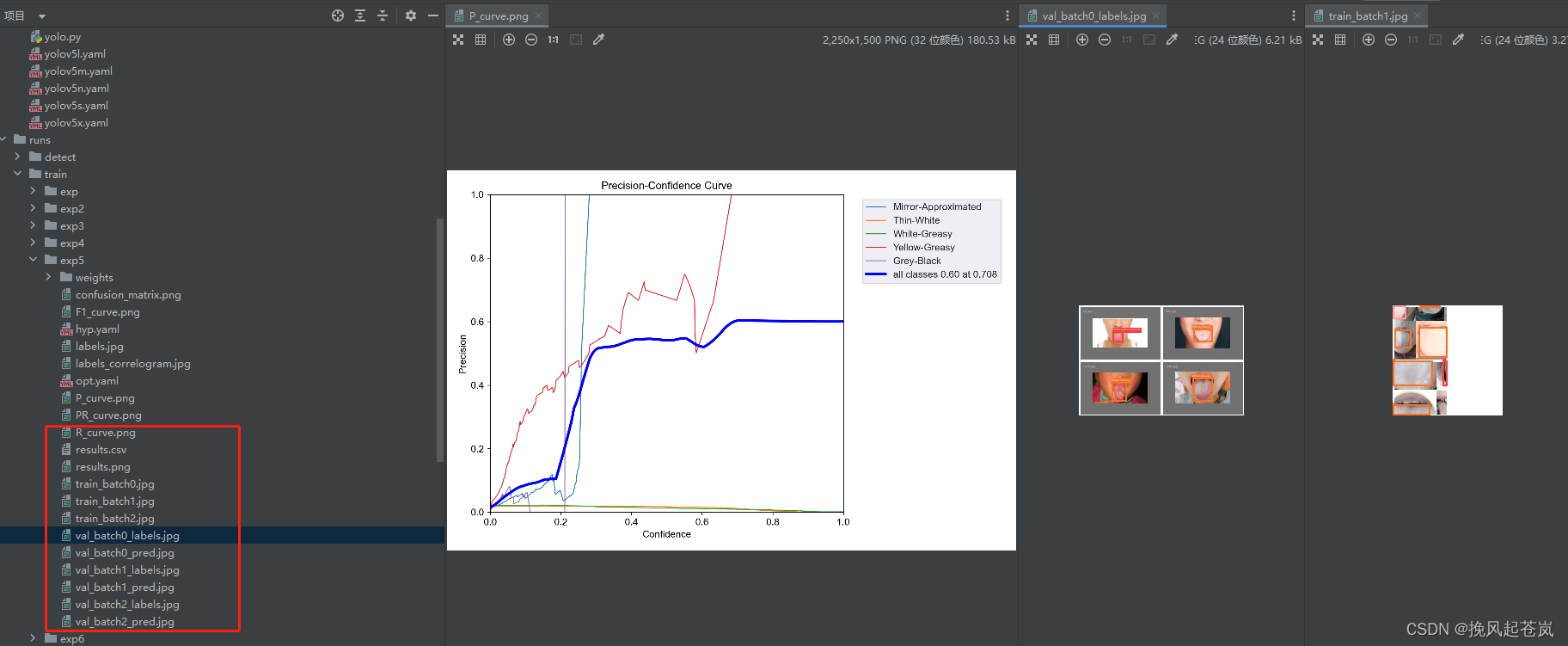
5.2 、开始预测(detect.py):
5.2.1 方式一:命令行启动
python detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
screen # screenshot
path/ # directory
list.txt # list of images
list.streams # list of streams
'path/*.jpg' # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream5.2.2 、方式二:修改detect.py一键运行
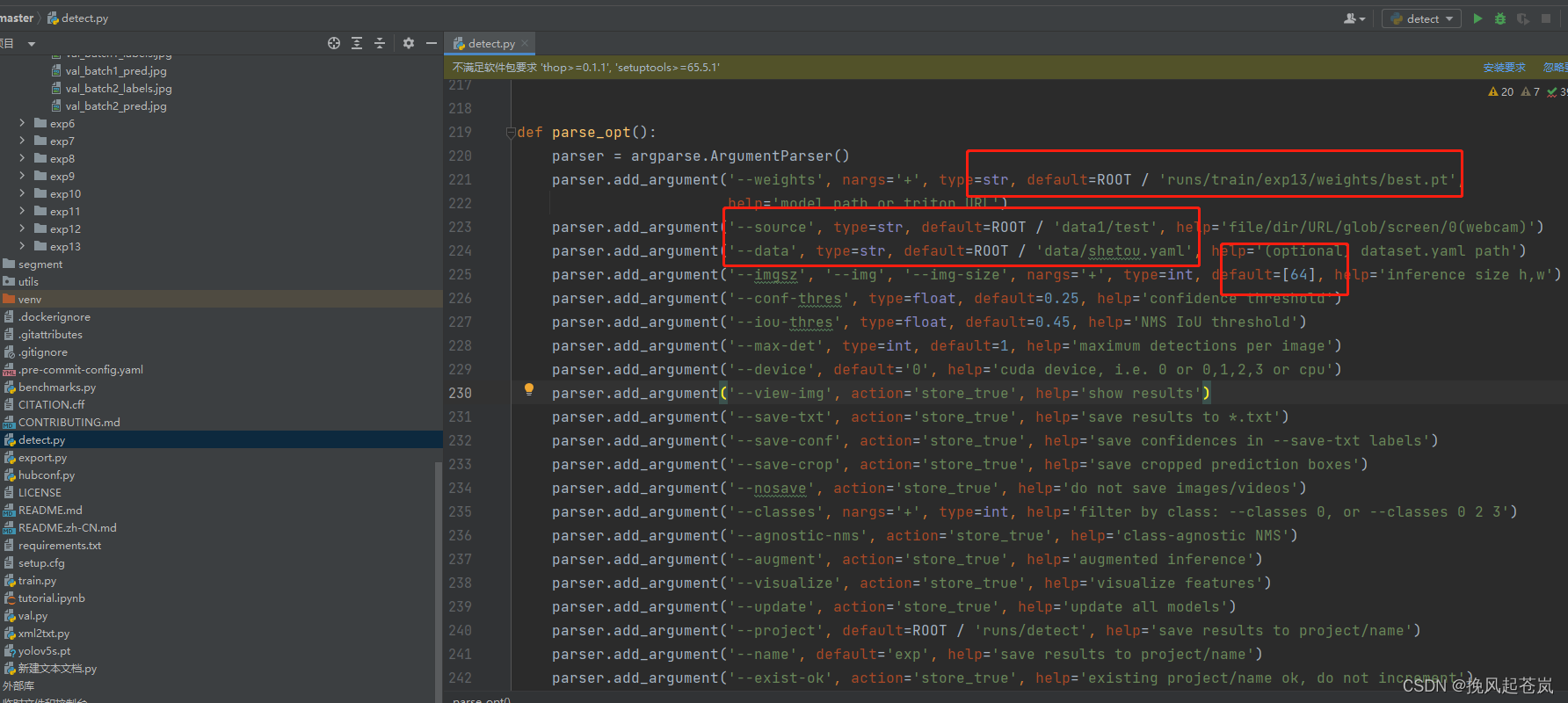
查看预测结果图。(runs目录下)
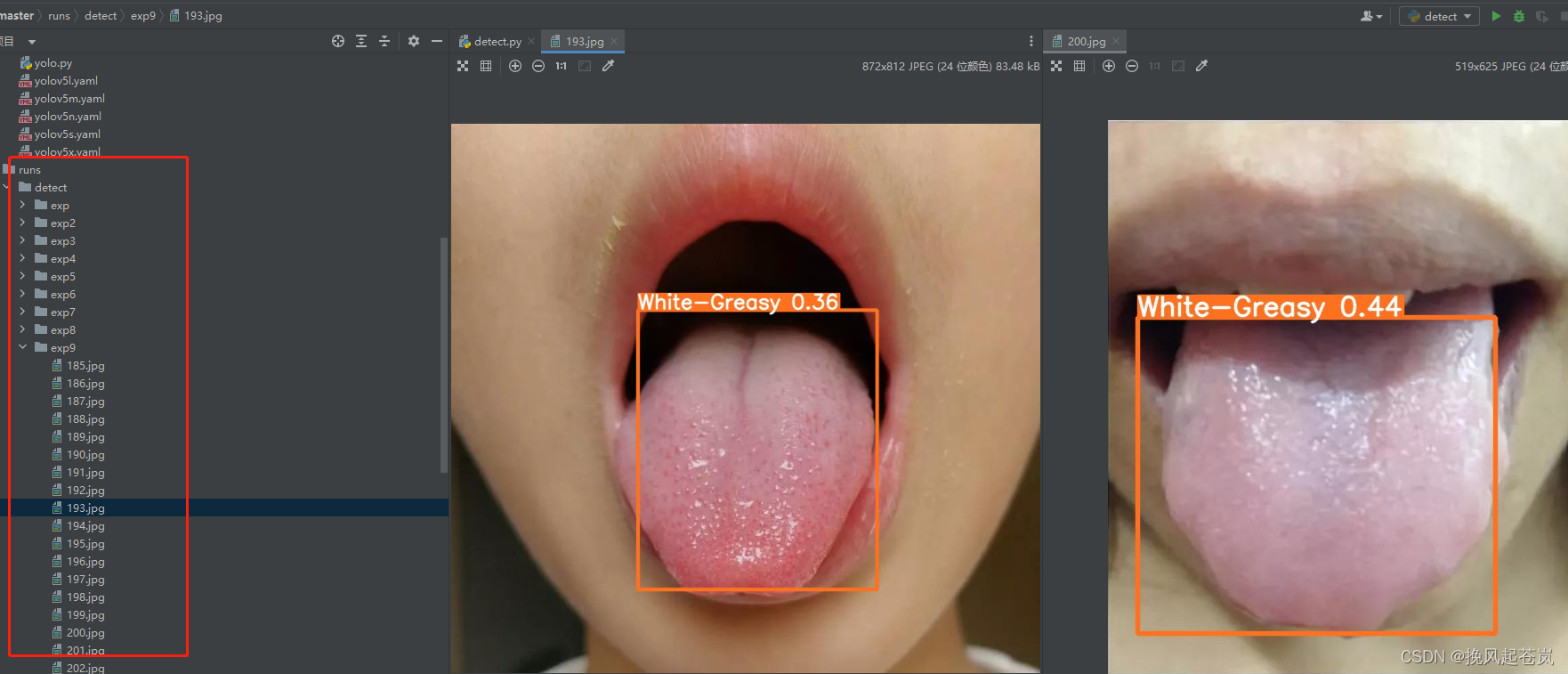
ok,整个训练过程和预测过程完毕。


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











