







目录
特征提取 sklearn.feature_extraction
概念:
从数据中自动分析获得模型,并利用模型对未知数据进行分析
所需的算法:
监督学习 回归问题:线性回归,岭回归 分类问题:分类k-近邻算法,贝叶斯分类,决策树与随机森林,逻辑回归 无监督学习:输入数据是由输入特征值所组成 聚类k-means算法
鸢尾花数据集 load_iris
from sklearn.datasets import load_iris
iris=load_iris()
print("鸢尾花数据集:\n",iris)
print("查看数据集描述:\n",iris["DESCR"])
print("查看数据集的名字:\n",iris.feature_names)
print("查看特征值:\n",iris.data,iris.data.shape)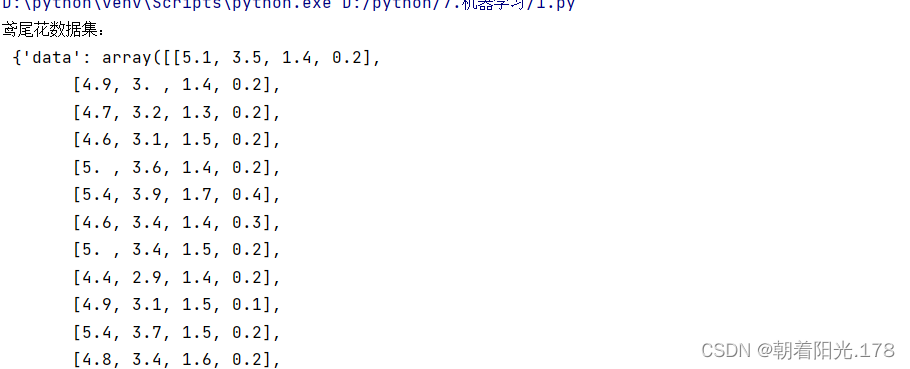


数据集的划分 train_test_split
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.2,random_state=22)
print("训练值的特征值:\n",x_train,x_train.shape)
print(x_test,x_test.shape)
print(y_train,y_train.shape)


特征提取 sklearn.feature_extraction
概念:将任意数据转化为可用于机器学习的数字特征
字典特征提取 DictVectorizer:
概念:把类别转换成one-hot编码
应用场景:类别场景非常多的时候,本身拿到的数据就是字典形式
data=[{'city':'北京','temperature':40},{'city':'上海','temperature':35},{'city':'深圳','temperature':30}]
#实例化一个转换器类
transfer=DictVectorizer() #转化为sparse矩阵:将非零值表现出来,提高加载效率
#调用fit_transform
data1=transfer.fit_transform(data)
print(data1)
print('特征名字:',transfer.get_feature_names_out())
transfer1=DictVectorizer(sparse=False) #不转化为sparse矩阵
data2=transfer1.fit_transform(data)
print(data2)

文本特征提取 CountVectorizer
概念:将单词进行特征划分,统计出现的次数
data=['Life is a fuking movie','I am chengguanxi']
transfer=CountVectorizer()
#调用fit_transform
data_new=transfer.fit_transform(data)
print(data_new.toarray())
print("特征名字:",transfer.get_feature_names_out())
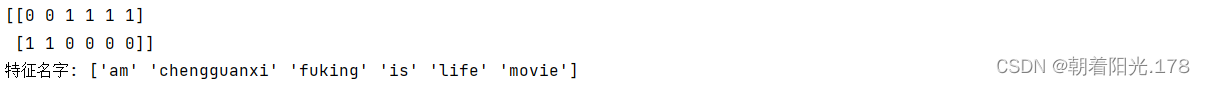
中文文本特征抽取:jieba断字
def cut_words(text):
return " ".join(list(jieba.cut(text)))
print(cut_words('我是中国人'))
![]()
data3=['我是陈冠希,我现在遇到了一帮很坏很坏的人。','我需要你们转帐300块,不,是300亿啊!']
data_newnew=[]
for sent in data3:
data_newnew.append(cut_words(sent))
data_final=transfer.fit_transform(data_newnew)
print(data_final.toarray())
print("特征名字:",transfer.get_feature_names_out()) 















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









