






目录
概述
在扎进GCN的前,我们先搞清楚这个玩意儿是做什么的,有什么用。
深度学习一直都是被几大经典模型给统治着,如CNN、RNN等等,它们无论再CV还是NLP领域都取得了优异的效果,那这个GCN是怎么跑出来的?是因为我们发现了很多CNN、RNN无法解决或者效果不好的问题——图结构的数据(看下图)。

- 图像的特征之所以能被CNN提取出来,是因为一切二维图像都具有平移不变性,也就是说当物体在图像中移动时,模型的输出应该仍然能够准确地识别和定位物体。而图结构(或者说树结构)是不具备这种平移不变性的
- 从另一方面来说,考虑到现实世界中存在很多不规则的空间结构,不似欧氏空间那样结构规则,具有维度的概念。对于不规则的结构,像最典型的树结构,图结构,甚至可以看作无限维的数据,显然我们就需要一种能从复杂结构中提取特征的网络
因此对于这种结构我们需要一种不同以往的特征提取器—GCN
GCN图卷积神经网络,实际上跟卷积神经网络CNN的作用一样,就是一个特征提取器,只不过它的对象是图数据。GCN精妙地设计了一种从图数据中提取特征的方法,从而让我们可以使用这些特征去对上图那样的数据进行节点分类(node classification)、图分类(graph classification)、边预测(link prediction),还可以顺便得到图的嵌入表示(graph embedding),可见用途广泛。
流程
- 聚合
- 更新
- 循环
会发现其实和GNN是完全一样的,实际上GCN就是对GNN的优化(在聚合那一步)
于是我们从GNN开始引入
GNN
GNN的聚合
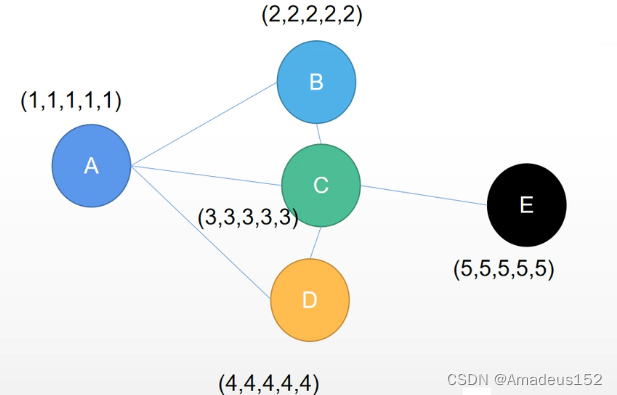
一个图由各个节点构成,各个节点有自己的特征,我们这里用一串数字序列代表每个节点的特征
例如,A(1,1,1,1,1)

既然有特征,我们就需要对特征进行识别并提取(深度学习所做的工作很多都是在做特征提取,像cv提取的是图像特征,nlp提取文本特征),总的来说,不论是为了分类,要么是为了做回归,特征提取都是必要的工作
这里以对节点做分类为例
一个节点本身就具备充足特征的话,自然就很容易提取出充分的特征来用于分类,但实际工作中这样理想的情形不会一直存在,那么为了方便分类,既然直接找特征找不到,我们就需要通过联系与这个节点所连接的其他节点,来间接地提取出这个节点的特征
例如上图中,通过A所连接的B,C,D来提取A的信息,这就是聚合
怎么聚合
换句话来说,就是把他邻居的信息贴到他的身上,那么该怎么去贴呢
我们先做出假设,这里A有三个邻居BCD,A具有的特征包括自己的特征n, 可以从邻居身上获取的特征m
m聚合了BCD对于A关联性的特征,
我们从简单的线性表达式入手,其中B,C,D有自己的特征(2,2,2,2,2),(3…), (4…)
m = p* (2,…) + q* (3,…) + w* (4,…)
上式中,p,q,w可以理解为BCD三者分别用于描述对于A的相似性的一个常数,假设B与A很相似,那么对应的常数p就大一些
更新
既然得到了邻居的关联信息,你下一步必然就是将得到的聚合特征m加和到A自己本身的信息n上
简单来说就是要通过一个数学公式整合m与n,这样得到的就是做一层GNN操作后得到的特征
循环
既然我们是要对全图的节点进行分类,那么B,C,D也要做类似的操作,他们也要与自己对应的邻居信息整合
当图中所有节点都做了一次聚合更新之后,
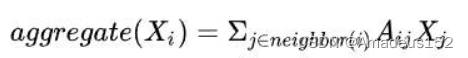

什么是循环呢,就是再做几次聚合更新
我们可以发现只做一次聚合更新,E对于A是起不到任何作用的,但可能E中包含了A中极有价值的特征,那我们为了使分类更精细,就需要把E中的特征也整合到A中,我们发现C中是包含了E的特征信息的,而且C做了一次聚合后C本身也聚合了E的特征,那么我如果对A再做一次聚合与更新,A不就有E的特征信息了吗
这就是循环的意义
GNN到GCN
就像前文在聚合那一步中说到的,我们聚合邻居特征信息时是要乘上各自的权重参数(p,q,w)的,对于如何确定权重参数,前人曾做过相当多的研究,其中就演化出了GCN-----图卷积神经网络算法
简而言之,GCN就是GNN的一种变式,他在聚合这一步上,对权重参数做出了数学上的约束,使GNN更进一步的具体
GCN的数学原理
如果你理解了GNN的三个流程,让我们来深入一下
我们说GCN是在聚合上的进一步具体,那么我知道聚合是为了提取邻居特征
GCN在聚合时则使用了平均的思想,具体是什么样的呢?
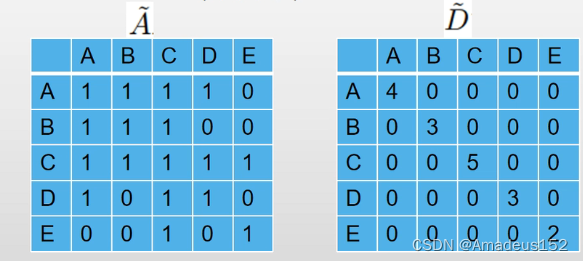
大家如果学过数据结构,一定接触过邻接矩阵这个概念,如果两个节点相连,那么在邻接矩阵上的对应位置的矩阵元素就为1,否则为0
我们假设图结构中有一个节点A,他的邻接矩阵A,他的每一个邻居都以一个自己的特征矩阵X,我们的想法是要通过算出A邻居的平均特征来间接表示A的特征,那么为了算出平均值,我们先考虑对A所有邻居的特征进行加和,那么由公式表示为
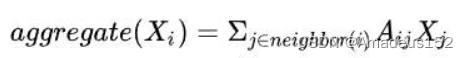
当然,权重只能作为一种参考,就像我和学霸坐同桌并不意味着我就是学霸了(除非知识自动从高浓度的地方向低浓度的地方传递)
因此,除了聚合,我们还要整合自己的特征,那么在数学上表达就是加上一个单位矩阵啦,为什么呢?看一眼下面的公式就明白了

这样,通过增加闭环,我们就得到了总的特征,接下来就是求平均:
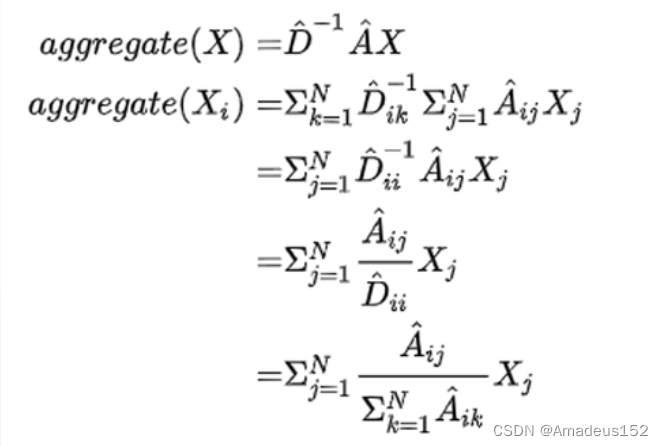
其中运用到了度矩阵(度矩阵是一个方阵,对角线上为全1,代表每个顶点有几条边)
分母是节点个数,分子就是节点特征,然后进行求和。
以上就是平均法,但是敏锐的小伙伴肯定能意识到,用平均法去代表一个指标肯定误差是很大的(想想全国平均工资)
那么GCN是怎么解决这个问题的呢?
答案就是GCN层之间的传播方式:
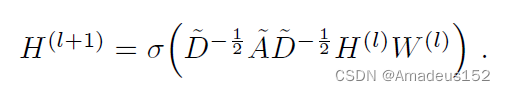
这个公式怎么理解呢?为避免意思偏移,我贴一段论文原文

- A波浪是A的邻接矩阵与单位阵的求和(也就是前面说的A加上它自己)
- D波浪是A波浪的度矩阵
- H是每一层的特征,对于输入层的话,H就是X
- 最后将这一层的处过后的特征数据通过一个非线性激活函数σ
- 这连贯起来的这个式子所展现的就是整个propagaton的过程了
例如下图的结构中,A波浪与D波浪的表示如下
我们将代入激活函数的处理过程拿出来

可以发现这一整个推导还是挺繁琐的,我们重在理解,借用一下原作者的思路:由浅入深
首先,我们作出假设:
我们每一层GCN的输入都是邻接矩阵A和节点特征H,而且还有当前L层的参数矩阵W,最后在该层激活一下,这样就作为一个简单的神经网络层来处理
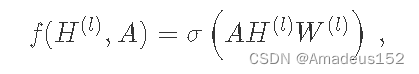
这样看来,一个简单的model就构建好了,然而,对于整个model,我们还需要处理两个问题
1. 上面的A是不包含自己的信息的,但是在传递过程中当然要加上自己的信息啊,如果A的对角线上都是0,在和特征矩阵H相乘的时候,只会计算一个节点的所有邻居的特征的加权和,该节点自己的特征却被忽略了,这就是为什么我们前面说要加上一个单位矩阵啦
2. 我们在作卷积之类的工作往往会遇到内协变量移位问题或者梯度爆炸梯度消失的问题,作图卷积的时候也是一样,为了缓解这样的问题,我们需要对节点邻接矩阵A进行归一化
首先让A的每一行加起来为1,我们可以乘以一个D的逆,D就是度矩阵。我们可以进一步把D的拆开与A相乘,得到一个对称且归一化的矩阵
于是乎,我们就构建出了上面model的propagation rule
原博客如下:

Specially,公式中的与对称归一化拉普拉斯矩阵十分类似,而在谱图卷积的核心就是使用对称归一化拉普拉斯矩阵,这也是GCN的卷积叫法的来历。
总结
GCN就是在平均法的基础上,加入了针对每个节点度的归一化。
GCN的每一层通过邻接矩阵A和特征矩阵H(l)相乘得到每个顶点邻居特征的汇总,然后再乘上一个参数矩阵W(l),加上激活函数σ做一次非线性变换得到聚合邻接顶点特征的矩阵H(l+1)。
之所以邻接矩阵A要加上一个单位矩阵I,是因为我们希望在进行信息传播的时候顶点自身的特征信息也得到保留。 而对邻居矩阵A波浪进行归一化操作D^(-1/2)A*D是为了信息传递的过程中保持特征矩阵H的原有分布,防止一些度数高的顶点和度数低的顶点在特征分布上产生较大的差异。
这样设计出来的层间传播公式就可以很好地提取图数据的特征,且提取出来的特征就可以用于节点分类,节点关系预测等工作。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









