






1.安装vscode配置c/c++环境
参考教程:Visual Studio Code安装配置C/C++教程,VSCode调试教程,VSCode安装使用教程,VSCode配置c/c++_哔哩哔哩_bilibili
两个相关json文件:
launch.json:
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "(gdb) 启动",
"type": "cppdbg",
"request": "launch",
"program": "${fileDirname}\\${fileBasenameNoExtension}.exe",
"args": [],
"stopAtEntry": false,
"cwd": "${fileDirname}",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"miDebuggerPath": "E:\\mingw64\\bin\\gdb.exe",
"setupCommands": [
{
"description": "为 gdb 启用整齐打印",
"text": "-enable-pretty-printing",
"ignoreFailures": true
},
{
"description": "将反汇编风格设置为 Intel",
"text": "-gdb-set disassembly-flavor intel",
"ignoreFailures": true
}
],
"preLaunchTask": "C/C++: gcc.exe 生成活动文件"
}
]
}tasks.json:
{
"tasks": [
{
"type": "cppbuild",
"label": "C/C++: gcc.exe 生成活动文件",
"command": "E:\\mingw64\\bin\\gcc.exe",
"args": [
"-fdiagnostics-color=always",
"-g",
"${fileDirname}\\*.c",
"-o",
"${fileDirname}\\${fileBasenameNoExtension}.exe"
],
"options": {
"cwd": "${fileDirname}"
},
"problemMatcher": [
"$gcc"
],
"group": {
"kind": "build",
"isDefault": true
},
"detail": "调试器生成的任务。"
}
],
"version": "2.0.0"
}2.在WSL中安装cuda
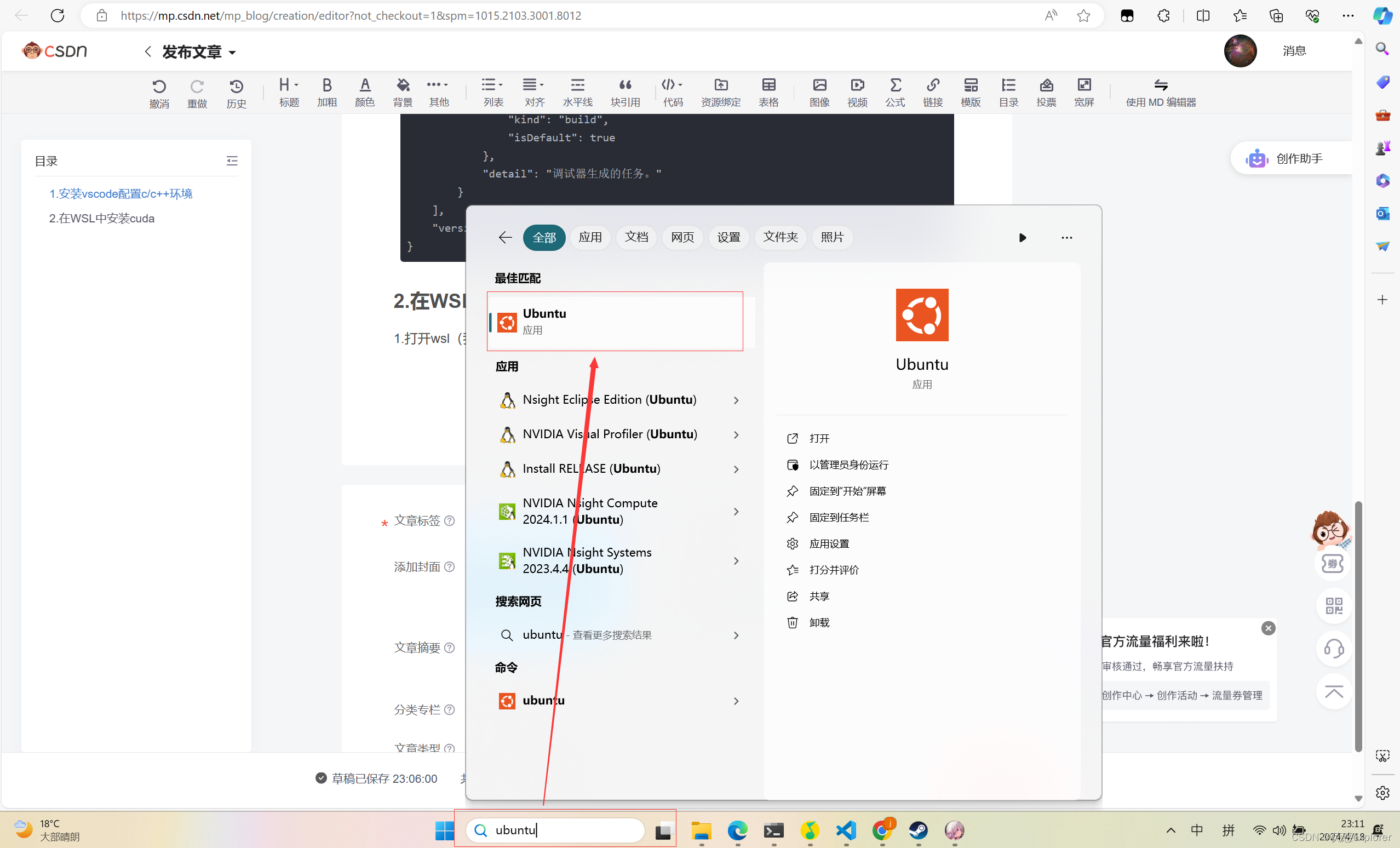
1.打开wsl(我这里的是ubuntu),在底部搜索栏搜索ubuntu,单击打开
2.进入cuda官网,找到要安装的cuda版本
CUDA Toolkit 12.4 Update 1 Downloads | NVIDIA Developer
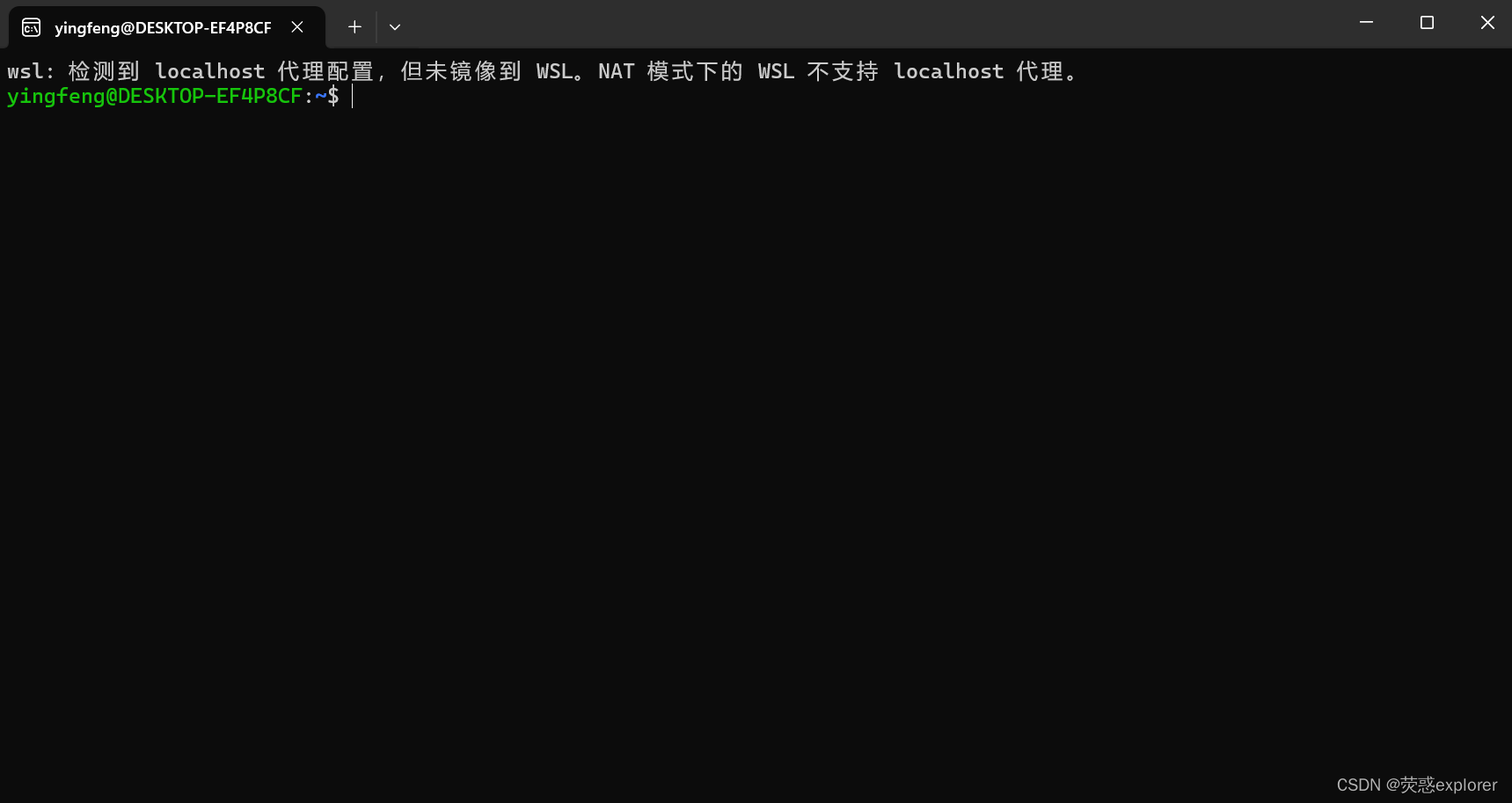
3.按照如下设置,并依次执行红框中的指令

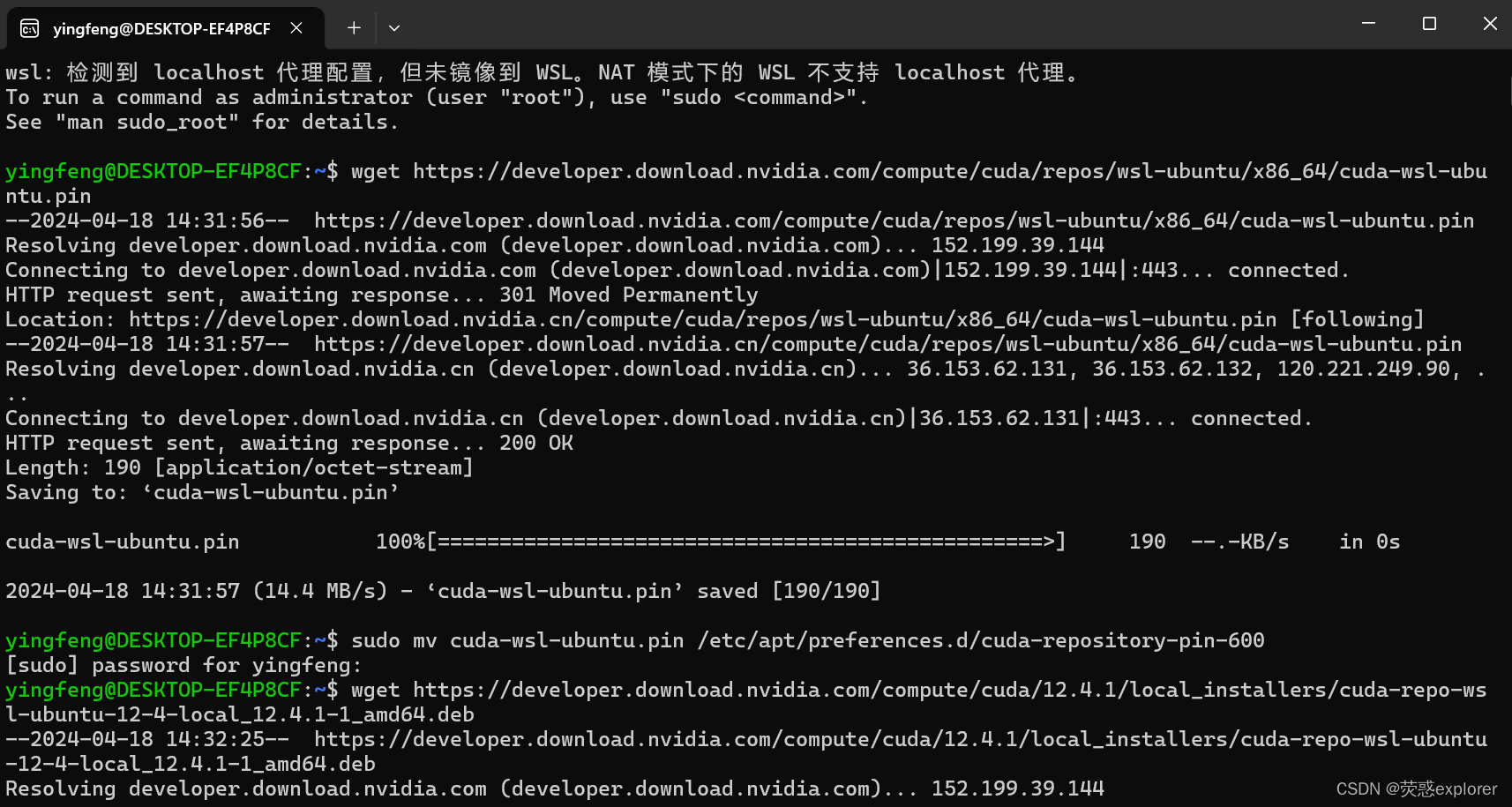
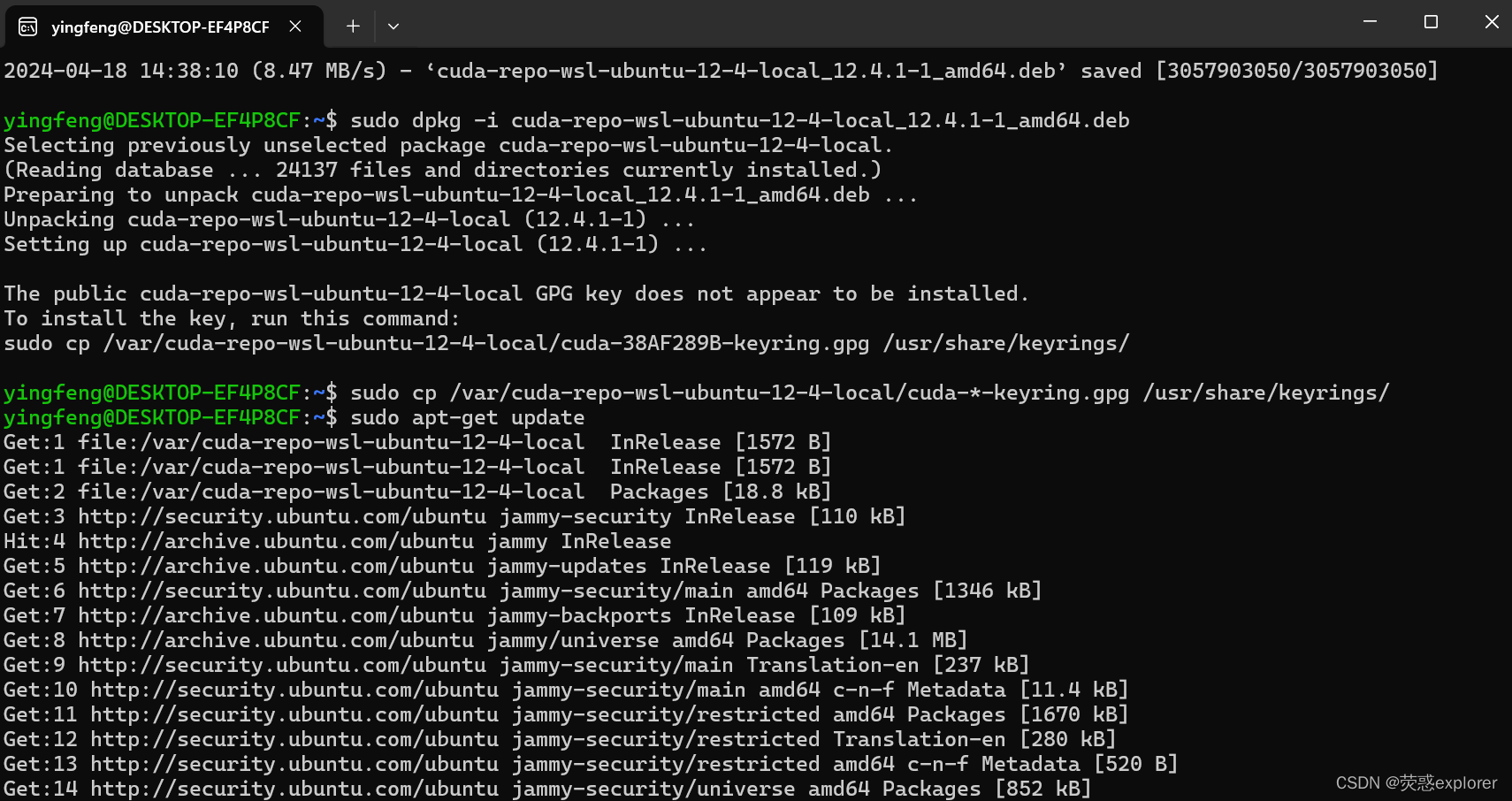

4.安装nano编辑器
sudo apt-get install nano 5.输入如下指令进入环境配置界面
5.输入如下指令进入环境配置界面
nano .bashrc 

6.按下箭头到最底,添加下述代码,版本根据你安装的版本进行修改,然后CTRL+X退出,按Y保存,默认名称,回车
# config cuda
export LD_LABRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-12.4/lib64
export PATH=$PATH:/usr/local/cuda-12.4/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-12.4
export PATH=/usr/local/cuda/bin:$PATH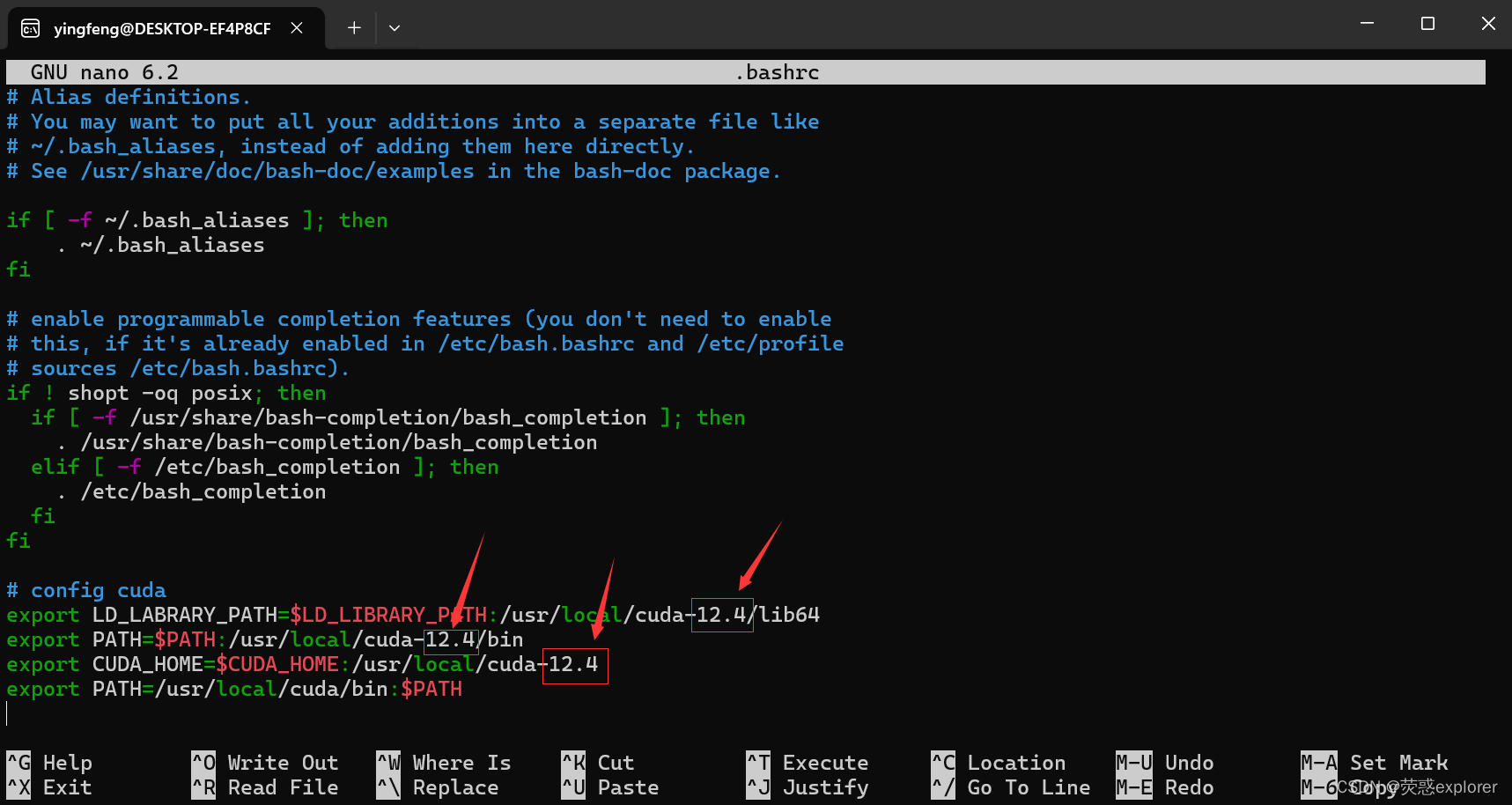
7.然后输入下述指令,执行修改
source ~/.bashrc8.输入nvcc -V或者nvidia-smi,检查是否配置完成,若出现如下返回,则成功
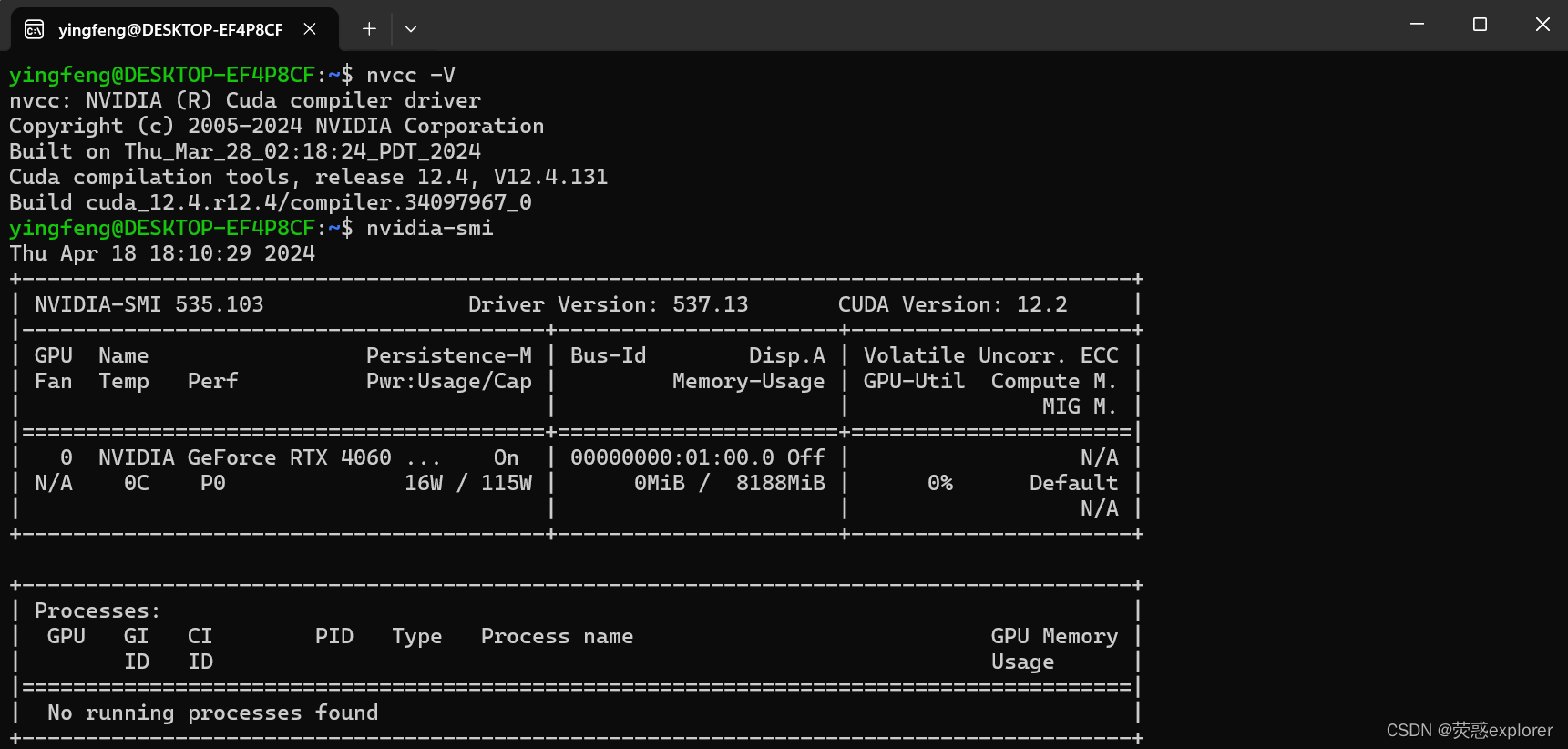
3.打开vscode创建并运行程序
1.在你的linux子系统下的用户主文件夹中创建一个code文件夹用于存放你的代码
2.在你的ubuntu终端输入code打开vscode

3.将文件夹添加到工作区


4.打开文件夹,创建新文件matrix_multi.cu并粘贴如下代码
#include <stdio.h>
#include <cuda_runtime.h>
#include <cublas_v2.h>
#define N 10240 // 矩阵大小
int main() {
cublasHandle_t handle;
float *a, *b, *c; // 声明设备上的矩阵指针
float *a_host, *b_host, *c_host; // 声明主机上的矩阵指针
int i, j;
size_t size = N * N * sizeof(float);
// 分配主机和设备内存
a_host = (float*)malloc(size);
b_host = (float*)malloc(size);
c_host = (float*)malloc(size);
cudaMalloc((void**)&a, size);
cudaMalloc((void**)&b, size);
cudaMalloc((void**)&c, size);
// 初始化矩阵数据
for(i = 0; i < N; i++) {
for(j = 0; j < N; j++) {
a_host[i*N + j] = 0.01f * j;
b_host[i*N + j] = 0.02f * j;
}
}
// 将数据从主机复制到设备
cudaMemcpy(a, a_host, size, cudaMemcpyHostToDevice);
cudaMemcpy(b, b_host, size, cudaMemcpyHostToDevice);
// 初始化 cuBLAS 上下文
cublasCreate(&handle);
float alpha = 1.0f;
float beta = 0.0f;
// 创建事件以记录时间
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
// 开始计时
cudaEventRecord(start, 0);
// 执行矩阵乘法
cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, N, N, N, &alpha, a, N, b, N, &beta, c, N);
// 停止计时
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float milliseconds = 0;
cudaEventElapsedTime(&milliseconds, start, stop);
printf("Time used: %f milliseconds\n", milliseconds);
// 清理
cudaFree(a);
cudaFree(b);
cudaFree(c);
free(a_host);
free(b_host);
free(c_host);
cublasDestroy(handle);
return 0;
}
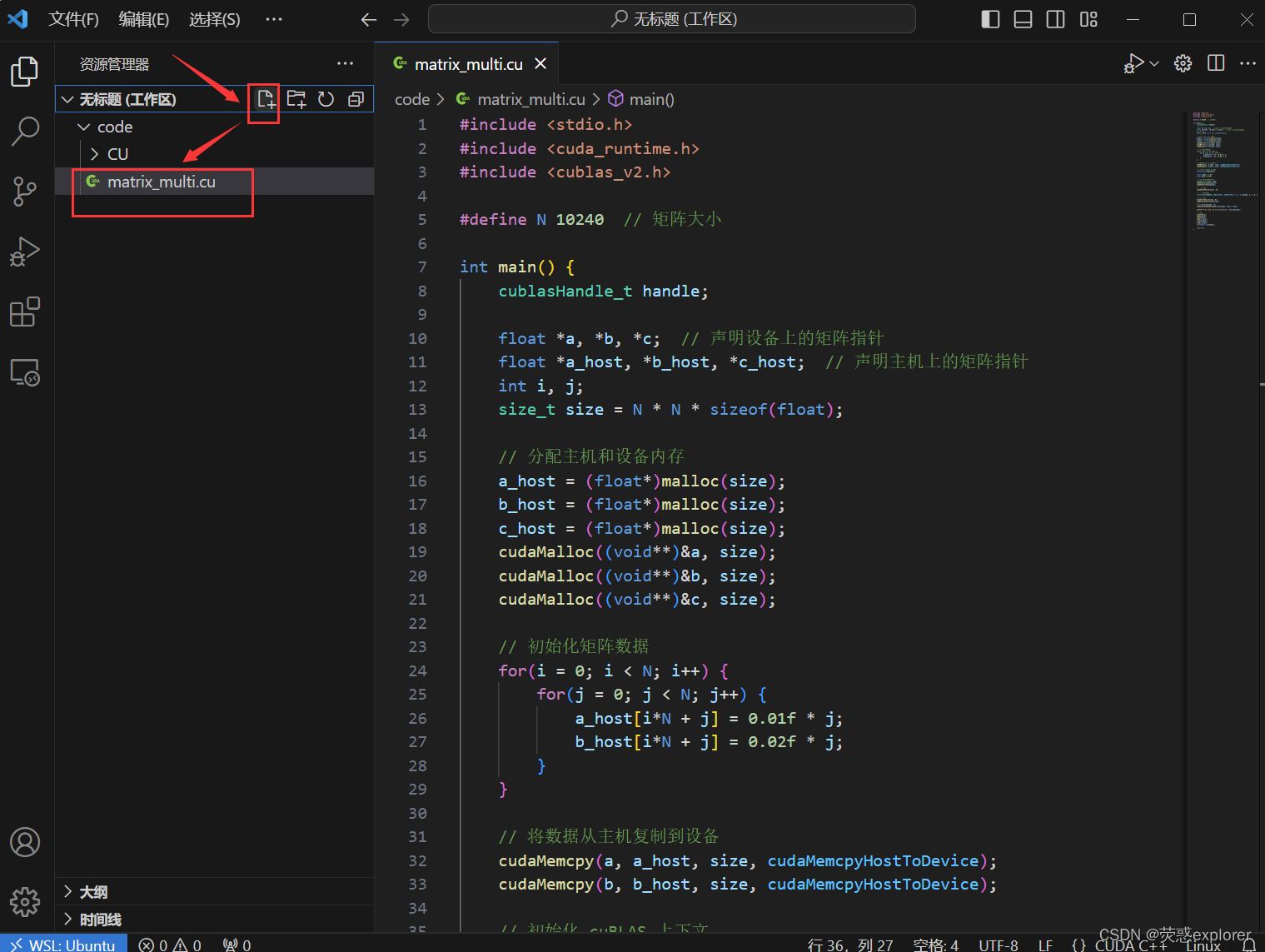
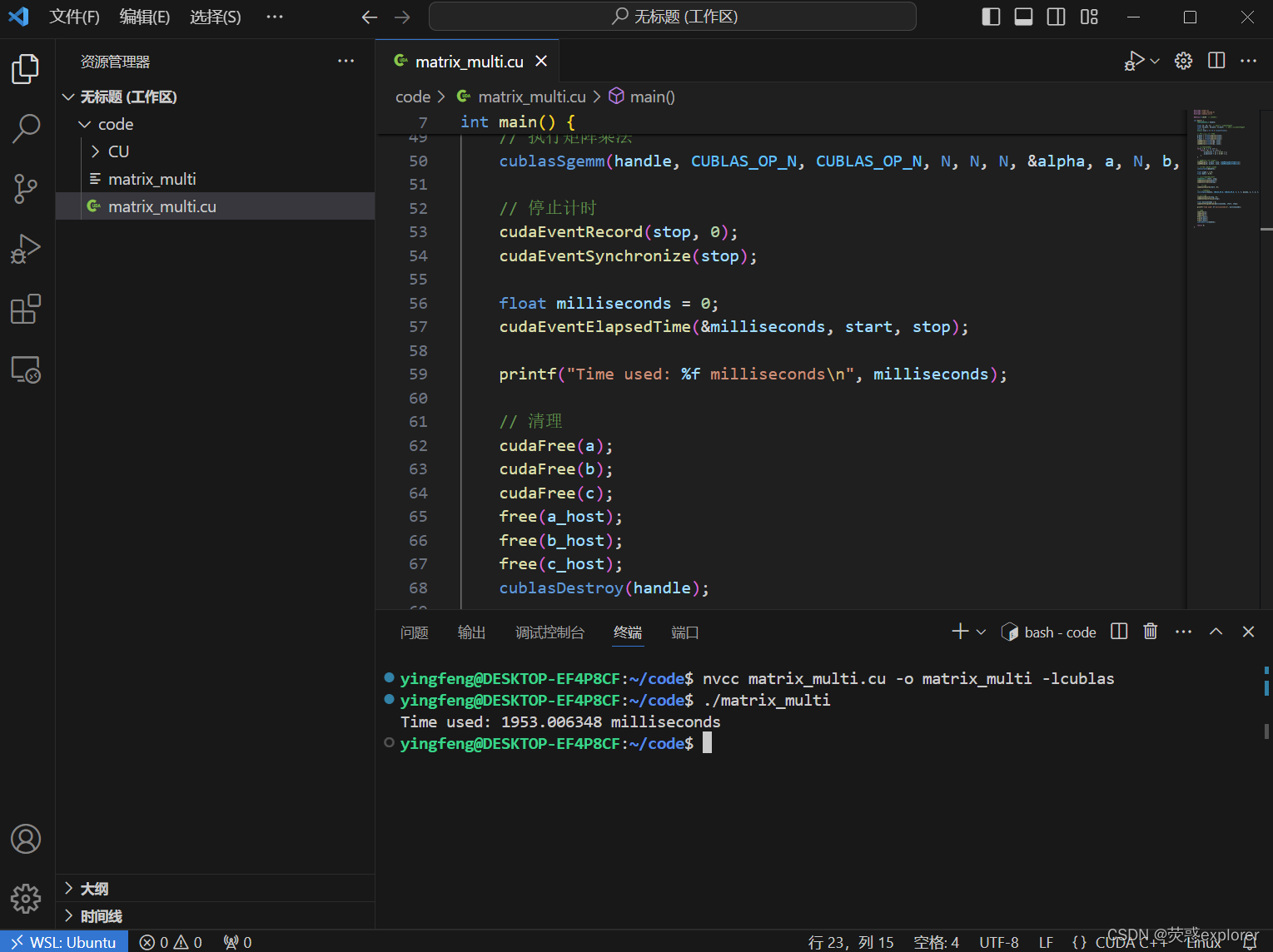
5.输入如下指令编译并运行,即可得到结果(实现两个10240x10240的浮点数矩阵相乘所需的时间)
nvcc matrix_multi.cu -o matrix_multi -lcublas./matrix_multi















 3419
3419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









