






KMP这个算法是用来在一个长的字符串中查找一段子串,首先先来讲一下朴素做法吧。
朴素做法
比如说在字符串“abcabcabcdabc”这一段字符串中查找“abcd”,如下图所示,在长字符串中先查找到第一个字符相同的位置,然后让两个指针同时向后走,直到短字符串走到了尽头,说明找到了匹配的子串,或者在查找的过程中有一个字符不相同,此时短字符串的指针重置到开头,而长字符串向后移一位。重复上面这个过程,直到查询到结果或者不存在。
这个做法是可以,但是时间复杂度太大。

使用KMP算法
KMP算法的想法是这样的,在长字符串和短字符串已经有一部分相同后,如果下一个字符不相同,此时不要直接把短字符串的指针重置到开头,长字符串也不要向后移一位,而是要发掘在这一小段相同的字符串中的信息。
比如说下面这个例子:

上面这个做法就是KMP算法的核心了,但是为了做到这一点还需要其他步骤,下面通过一道题来讲解。
题目
给定一个字符串 S,以及一个模式串 PP,所有字符串中只包含大小写英文字母以及阿拉伯数字。
模式串 P 在字符串 SS 中多次作为子串出现。
求出模式串 PP 在字符串 SS 中所有出现的位置的起始下标。
输入格式
第一行输入整数 N,表示字符串 P 的长度。
第二行输入字符串 P。
第三行输入整数 M,表示字符串 S 的长度。
第四行输入字符串 S。
输出格式
共一行,输出所有出现位置的起始下标(下标从 0 开始计数),整数之间用空格隔开。
数据范围
1≤N≤10^5 1≤M≤10^6
输入样例:
3 aba 5 ababa
输出样例:
0 2
要实现kmp算法,我们需要把短字符串每一个长度的前缀和后缀相同最长的长度求出来,用一个数组保存,比如说字符串“abababc”,具体见下图。
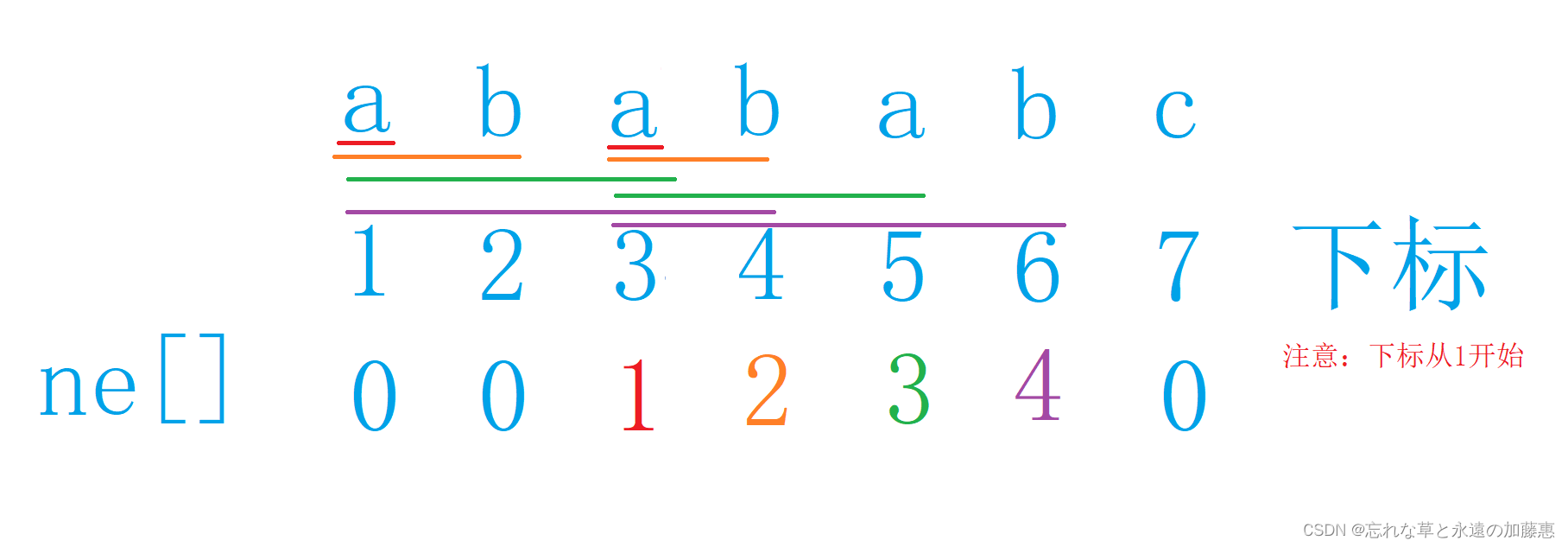
由上面这幅图我们可以获得了每个长度的子字符串的最长前缀和后缀的长度,注意,当字符串长度只有一的时候,最长前缀和后缀的长度都是0。那么我们怎么通过代码来获取呢?
拿两个指针分别指向下标为0和2,用 j 和 i 保存,每次比较p[j + 1] 和 p[i] 是否相同,如果相同就让j和i都后移一位,否则就让j移动到ne[j]这个位置上,因为此时区间[ 1 ~ ne[ j ] ]和[ j - ne[j] + 1, j ]的字符串是相同的这是根据前面的循环判断出来的。而在判断p[j + 1] != p[i]的时候要循环判断,理由是比如说上面这幅图,当指针移到最后一位c的时候,此时我们可以看出它的最长前缀和后缀的长度是0,但要通过代码来判断是0需要一步一步来,第一次, j = 5, j = ne[j] = 3;第二次 j = 3, j = ne[j] = 1; 第三次, j = 1,j = ne[j] = 0,判断出来长度是0了。
说到这里肯定还是有点蒙圈的,所以最好还是边看代码调试一遍最好,有助于理解。
for(int i = 2, j = 0; i <= n; i++){ // i从2开始,是因为只有一个字符的时候ne[1]=0,这是个特殊情况
while(j && p[j + 1] != p[i]) j = ne[j]; // 如果p[j + 1]与p[i]不匹配,就找前缀
if(p[j + 1] == p[i]) j++; // 如果p[j + 1] == p[i],就往后一位,然后继续匹配
ne[i] = j; // 保存当前的前缀和后缀最长的相同字符串长度
}然后下一步就要开始匹配了,其实kmp匹配与上面那个构造ne数组做法是很相似的,只不过原来是在一个字符串上下功夫,而这次是在两个字符串上做文章。
长字符串从开头开始匹配,先找到第一个与短字符串第一个字符相同的地方,然后往后遍历,使 i 和 j 都向后移动,如果找到一个字符不匹配,就循环使得 j = ne[j],直到找到相同的子串,如果j变成了0就说明不存在前缀和后缀相同的字符串。如果j == n就表示找到了相同的字符串,然后输出开头的下标,因为保存数据是从下标1开始的,所以输出 i - n。
for(int i = 1, j = 0; i <= m; i++){
while(j && p[j + 1] != s[i]) j = ne[j]; // 如果p[j + 1]与s[i]不匹配,就找前缀
if(p[j + 1] == s[i]) j++; // 如果p[j + 1] == s[i],就往后一位,然后继续匹配
if(j == n){ // 此时说明子串已经匹配到最后一个字符了,输出
printf("%d ", i - n);
j = ne[j]; // 此时直接移到它的前缀
}
}上面代码中在查询到相同的字符串后执行的 j = ne[j]是什么意思呢?看下面这幅图。
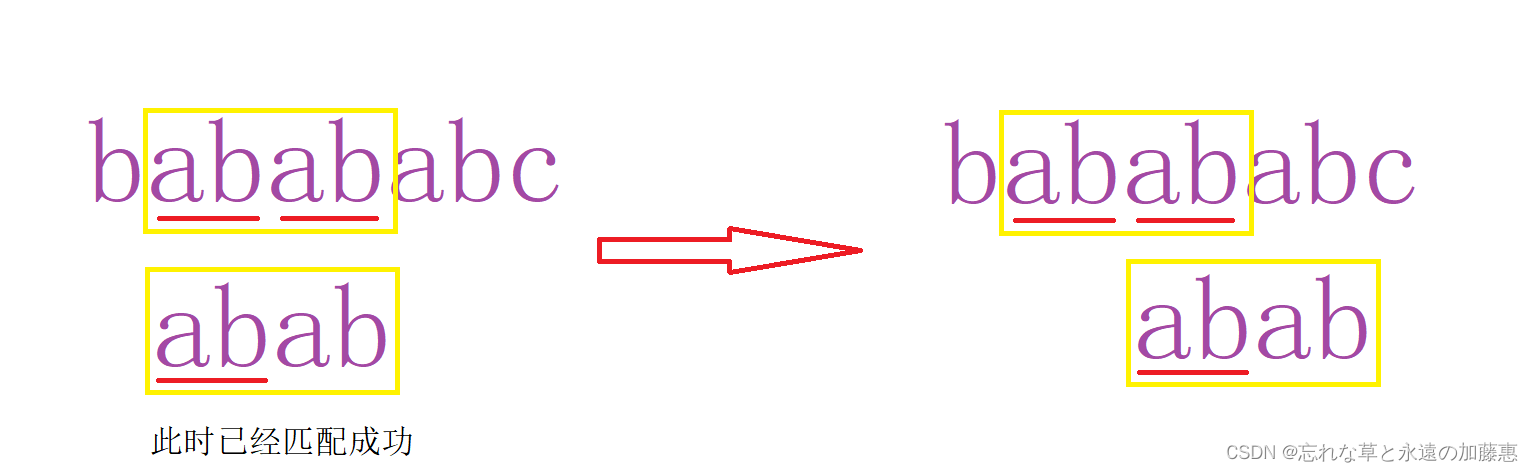
此时字符串“abab”已经匹配成功了,但是前缀和后缀有相同的字符串“ab”,所以需要执行j = ne[j]来继续匹配后面。
下面是完整的代码:
#include<iostream>
using namespace std;
const int N = 100010, M = 1000010;
char p[N], s[M]; // p是短的字符串,s是长的字符串
int ne[N]; // 保存前缀和后缀最长的相同字符串长度
int main(){
int n, m;
cin >> n >> p + 1 >> m >> s + 1; // 两个数组下标都从1开始
// 更新ne数组
for(int i = 2, j = 0; i <= n; i++){ // i从2开始,是因为只有一个字符的时候ne[1]=0,这是个特殊情况
while(j && p[j + 1] != p[i]) j = ne[j]; // 如果p[j + 1]与p[i]不匹配,就找前缀
if(p[j + 1] == p[i]) j++; // 如果p[j + 1] == p[i],就往后一位,然后继续匹配
ne[i] = j; // 保存当前的前缀和后缀最长的相同字符串长度
}
// kmp匹配
for(int i = 1, j = 0; i <= m; i++){
while(j && p[j + 1] != s[i]) j = ne[j]; // 如果p[j + 1]与s[i]不匹配,就找前缀
if(p[j + 1] == s[i]) j++; // 如果p[j + 1] == s[i],就往后一位,然后继续匹配
if(j == n){ // 此时说明子串已经匹配到最后一个字符了,输出
printf("%d ", i - n);
j = ne[j]; // 此时直接移到它的前缀
}
}
return 0;
}以上就是本次KMP算法的全部,如果有什么错误或者不足欢迎指出。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









