






使用飞桨模型进行训练的尝试
注意:我们在飞桨使用的是ipynb格式的文档
ipynb格式文件
是 Jupyter Notebook 来编写python程序时的文件。
如果已安装Anaconda,自带jupyter 软件
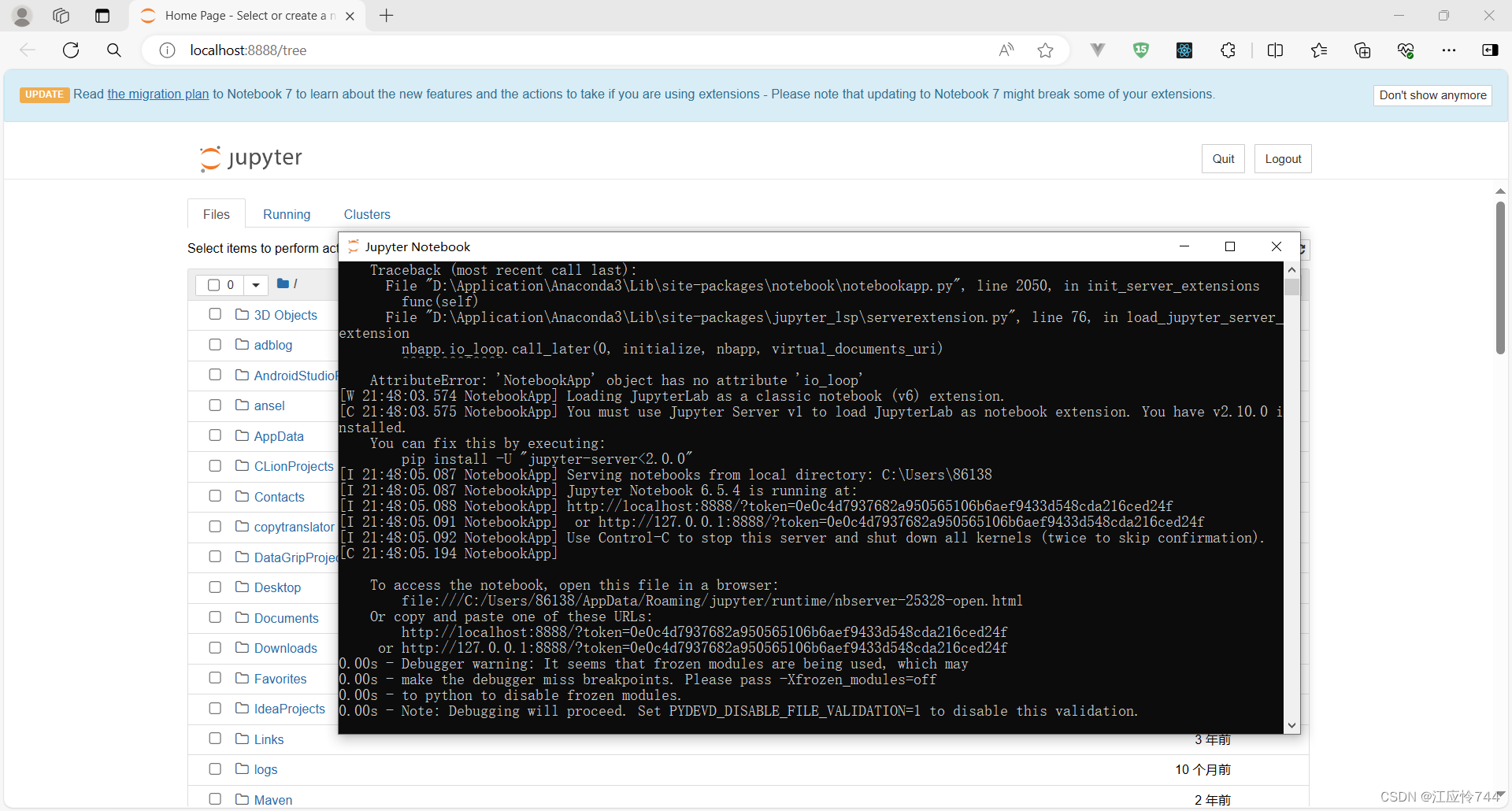
从开始菜单中打开 jupyter notebook 的快捷方式(prompt 中用该命令打开同理),就会自动打开一个http://localhost:8888/的链接。此时web端属于是登录了一个“账号”,你可以根据需要,在线执行代码等操作。通过upload选择电脑本地文件,上传即可打开和运行。
注意终端不可关闭。而在本地终端这里则是一直停留在运行界面,如果你不小心关闭就算注销了。所以你可以在web页面里在线注销,也可以在本地终端里Ctrl+C退出,此时就会显示弹窗服务终止。我们就无法通过web页面来访问本地文件了。
从jupyter notebook里打开的.ipynb文件才是格式正确,层次分明的交互式笔记文件了。很多项目程序里都以这样的文件格式方式来保存的。当然,jupyter notebook其实并不仅仅用于机器学习。
我们之前常用的语法是linux语法 对控制台进行操作
ipynb在这一点上 ! + linux语法 就是使用的 linux语法 所以对我们来说上手还是比较容易的。
OCR任务说明
这一次的智慧交通组的任务由以往的检测分割换成了OCR任务。OCR任务分为两种文字检测和文字识别,检测需要定位文本位置(类似目标检测),而识别就是识别出图像中的文字,我们这次的比赛任务就是文字识别。

数据集准备
在BML CodeLab中 我们
#解压数据集 !unzip -d data/ data/data258841/DataForCompetitor.zip
即可解压我们的数据集
对我们数据集进行查看

下面是标签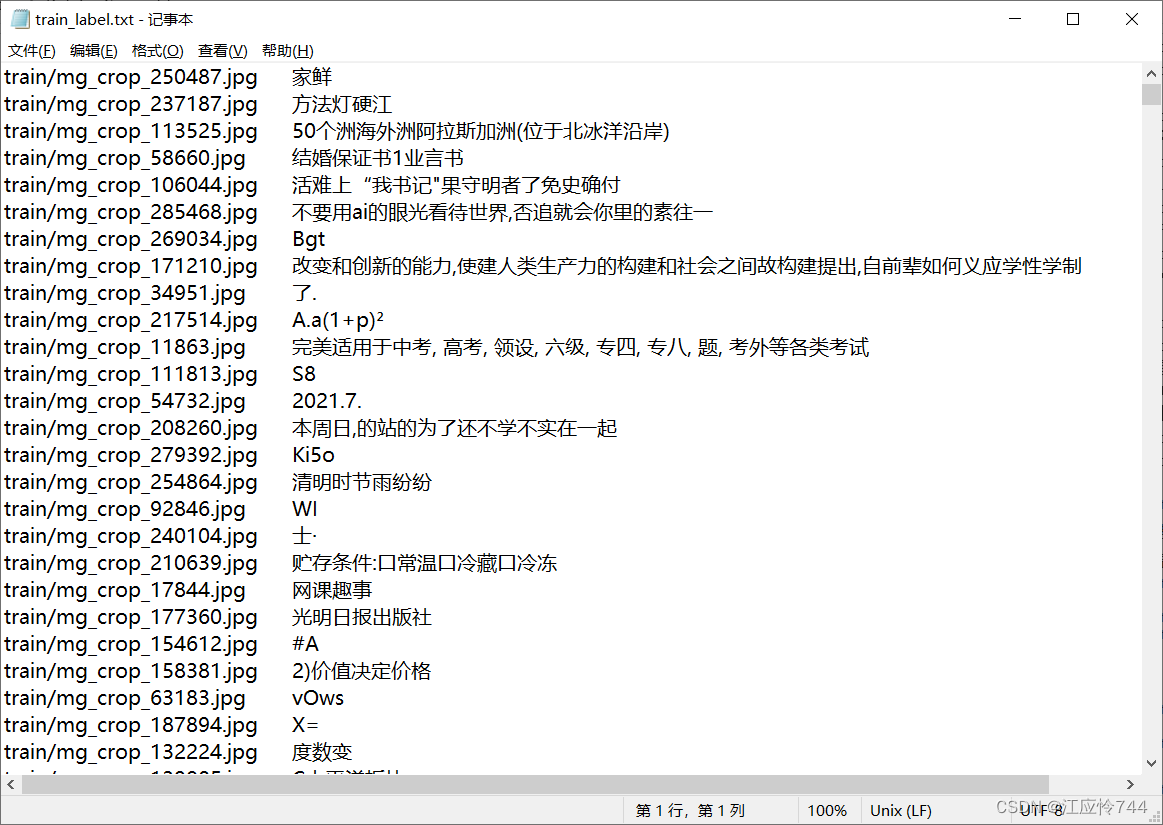
克隆项目仓库
我们克隆对应的项目仓库,注意本项目只能用PaddlerOCR2.7才可以完成
本项目的PaddleOCR进行了清洗,删除了不不要的部分。
#PPOCRv4目前只在github上面,注意不要clone错了 #目前项目里面已经上传最新的PaddleOCR !git config --global http.postBuffer 52428800000 !git clone https://github.com/PaddlePaddle/PaddleOCR
炼丹开始
首先是解压一下预训练权重
# 解压一下预训练权重 !tar -xvf ch_PP-OCRv4_rec_train.tar
进入PaddleOCR目录
#进入PaddleOCR目录 %cd /home/aistudio/PaddleOCR
安装必要的依赖库
#安装必要的依赖库 !pip install -r requirements.txt
开始执行训练
#开始执行训练 !python tools/train.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model=/home/aistudio/ch_PP-OCRv4_rec_train/student.pdparams
PPOCRv4 配置文件内容
Global: debug: false use_gpu: true #是否使用GPU训练 epoch_num: 50 #训练轮数 log_smooth_window: 20 #常规log设置 print_batch_step: 10 #打印训练日志的迭代次数 save_model_dir: ./output/rec_ppocr_v4 #模型保存路径 save_epoch_step: 10 #保存模型的轮数 eval_batch_step: [0, 2000] #进行evaluation的迭代次数 cal_metric_during_train: true #训练过程中是否计算指标 pretrained_model: #预训练模型权重 checkpoints: #恢复训练的权重 save_inference_dir: #保存推理结果的路径 use_visualdl: false #是否可视化训练过程 infer_img: doc/imgs_words/ch/word_1.jpg #推理时候的图片 character_dict_path: ppocr/utils/ppocr_keys_v1.txt max_text_length: &max_text_length 25 infer_mode: false use_space_char: true distributed: true #是否分布式训练 save_res_path: ./output/rec/predicts_ppocrv3.txt #保存预测结果的txt路径 Optimizer: #优化器参数 name: Adam beta1: 0.9 beta2: 0.999 lr: name: Cosine learning_rate: 0.0001 warmup_epoch: 5 regularizer: name: L2 factor: 3.0e-05 Architecture: #模型结构 model_type: rec #文本识别 algorithm: SVTR_LCNet #算法名称 Transform: Backbone: #骨干网络 name: PPLCNetV3 scale: 0.95 Head: #预测头 name: MultiHead head_list: - CTCHead: Neck: name: svtr dims: 120 depth: 2 hidden_dims: 120 kernel_size: [1, 3] use_guide: True Head: fc_decay: 0.00001 - NRTRHead: nrtr_dim: 384 max_text_length: *max_text_length Loss: #损失函数 name: MultiLoss loss_config_list: - CTCLoss: - NRTRLoss: PostProcess: #后处理 name: CTCLabelDecode Metric: #验证时候的指标 name: RecMetric main_indicator: acc Train: #训练过程配置 dataset: #数据集信息 name: MultiScaleDataSet ds_width: false data_dir: /home/aistudio/data/DataForCompetitor/ #数据集根路径 ext_op_transform_idx: 1 label_file_list: #标签路径 - /home/aistudio/data/DataForCompetitor/train_label.txt transforms: #数据增强 - DecodeImage: img_mode: BGR channel_first: false - RecConAug: prob: 0.5 ext_data_num: 2 image_shape: [48, 320, 3] max_text_length: *max_text_length - RecAug: - MultiLabelEncode: gtc_encode: NRTRLabelEncode - KeepKeys: keep_keys: - image - label_ctc - label_gtc - length - valid_ratio sampler: name: MultiScaleSampler scales: [[320, 32], [320, 48], [320, 64]] first_bs: &bs 192 fix_bs: false divided_factor: [8, 16] # w, h is_training: True loader: shuffle: true batch_size_per_card: *bs drop_last: true num_workers: 8 Eval: #验证信息 dataset: name: SimpleDataSet data_dir: /home/aistudio/data/DataForCompetitor/ label_file_list: - /home/aistudio/data/DataForCompetitor/train_label.txt transforms: - DecodeImage: img_mode: BGR channel_first: false - MultiLabelEncode: gtc_encode: NRTRLabelEncode - RecResizeImg: image_shape: [3, 48, 320] - KeepKeys: keep_keys: - image - label_ctc - label_gtc - length - valid_ratio loader: shuffle: false drop_last: false batch_size_per_card: 128 num_workers: 4
导出模型
#注意修改下面的路径 # -c 后面设置训练算法的yml配置文件 # -o 配置可选参数 # Global.pretrained_model 参数设置待转换的训练模型地址,不用添加文件后缀 .pdmodel,.pdopt或.pdparams。 # Global.save_inference_dir参数设置转换的模型将保存的地址 !python tools/export_model.py -c configs/rec/PP-OCRv4/ch_PP-OCRv4_rec.yml -o Global.pretrained_model=/home/aistudio/output/rec_ppocr_v4/best_model/model Global.save_inference_dir=/home/aistudio/infer/















 360
360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









