







Attention网络的整体结构:
encoder +decoder
encoder是N=6个相同层按照堆栈的形式构成,每层encoder包括两个子层
decoder同样是6个堆栈构成,有三个子层。
该网络中,使用的最重要的两部分为:muti-head Attention 和 Feed Forward
Attention Function 看看作是:query,key-value --> output(查询,键值对 映射到输出)
查询和键使用兼容性函数计算值的权重,值的加权和构成输出。
具体计算公式如下所示: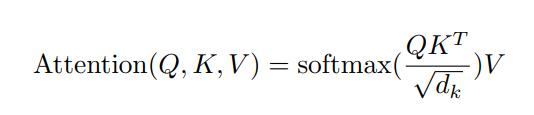
Q,K,V分别为query,key,value的矩阵。本算法与Dot-product相似,不同之处在于使用了。因为当d_k 增大时,Q*K增大,使得softmax的梯度逐渐变小,因此使用
增大梯度。
softmax函数如下所示:

第一部分:Muti-head Attention
本论文设计的特殊的Attention全称为 Scaled Dot-Product Attention,以下是网络结构:
Muti-Head Attention:
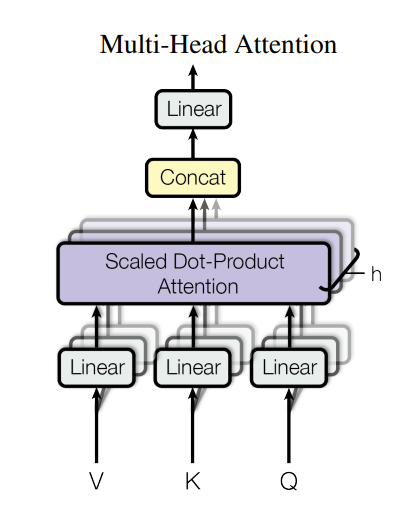
相较于单次使用model维度的参数query,key,value输入到attention function中,使用h次不同的,学习过的线性计算query,value,key到d_k,d_k,d_v维度,更加有效。这些计算最终被连接和计算, 并输出最终的结果。
作用:Multi-head attention 允许模型关注来自不同位置的表示不同子空间的信息。
第二部分:Position-wise Feed-Forward Networks
虽然在不同的位置使用相同的线性变换,但是层到层之间的参数不同,Feed Forward的函数如下:
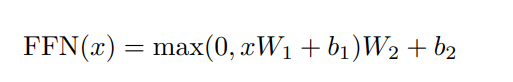
embedding and softmax:在输入和输出中使用相同参数的embedding和pre-softmax线性转换
Positional encoding:由于本论文未使用任何卷积网络,为了利用序列间的顺序关系,在encoder和decoder的栈底部加入了positional encodings,本文使用的是如下关系:
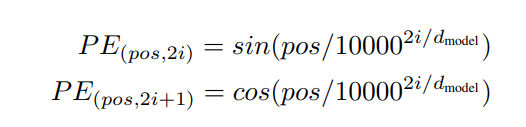
pos是位置,i是维度。















 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









