







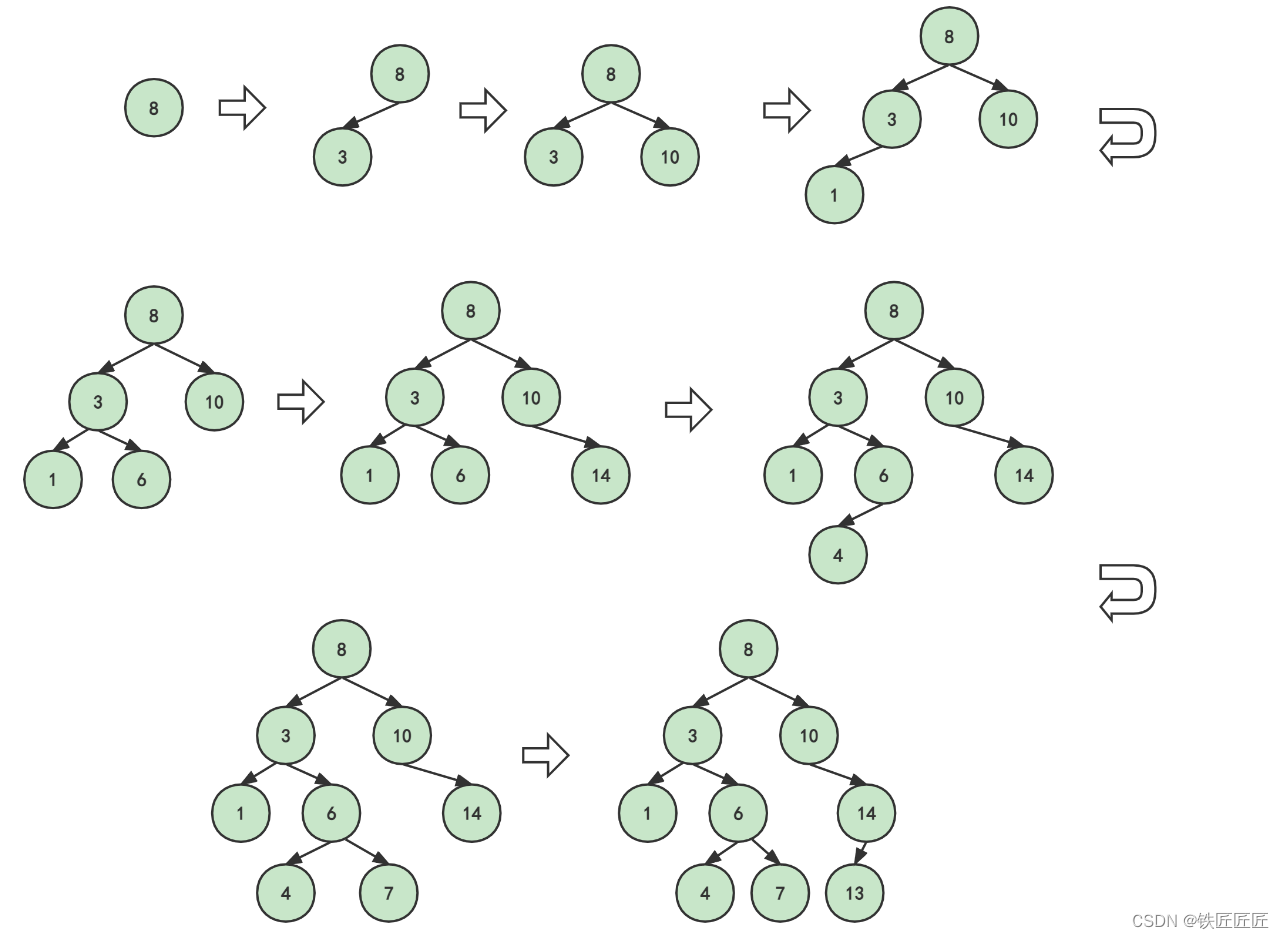
回顾构建二叉排序树

- 首先,将8作为根节点
- 插入3,由于3小于8,作为8的左子树
- 插入10,由于10大于8,作为8的右子树
- 插入1,由于1小于8,进入左子树3,1又小于3,则1为3的左子树
- 插入6,由于6小于8,进入左子树3,6又大于3,则6为3的右子树
- 插入14,由于14大于8,进入右子树10,14又大于10,则14为10的右子树
- 插入4,由于4小于8,进入左子树3,4又大于3,进入右子树6,4还小于6,则4为6的左子树
- 插入7,由于7小于8,进入左子树3,7又大于3,进入右子树6,7还大于于6,则7为6的右子树
- 插入13,由于13大于8,进入右子树10,又13大于10,进入右子树14,13小于14,则13为14的左子树
经过以上的逻辑,这棵二叉排序树构建完成。
我们可以看出:
- 只要左子树为空,就把小于父节点的数插入作为左子树
- 只要右子树为空,就把大于父节点的数插入作为右子树
- 如果不为空,就一直往下去搜索,直到找到合适的插入位置
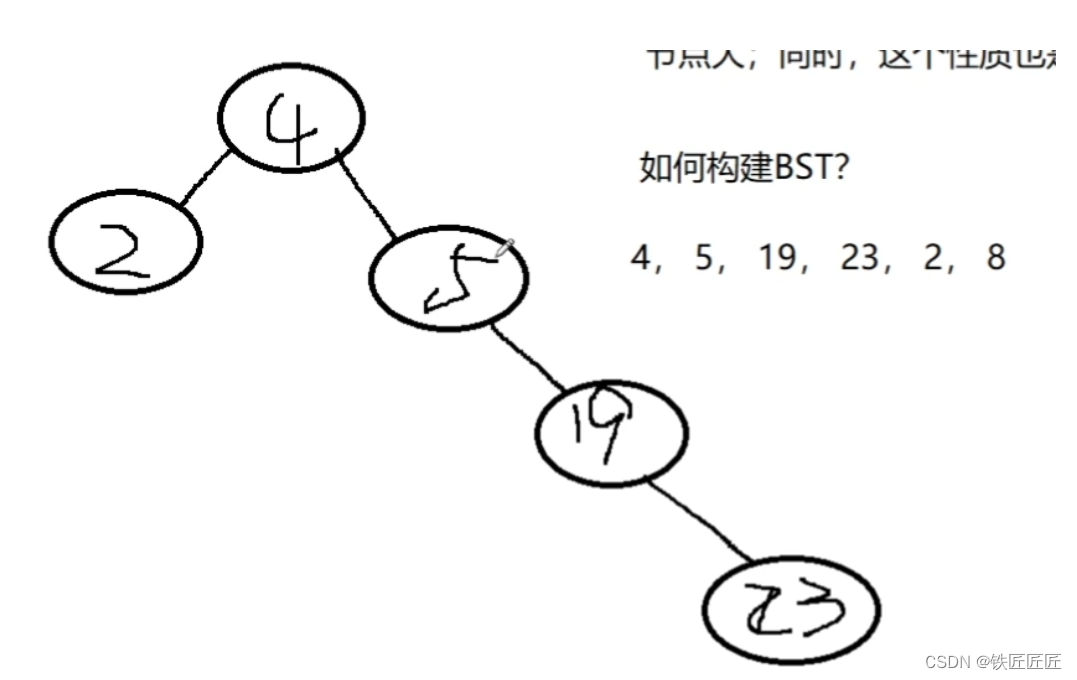
了解了如何构建后,我们不禁要问,这有啥用呀?感觉没啥特别的地方呢?别急!我们马上揭晓!
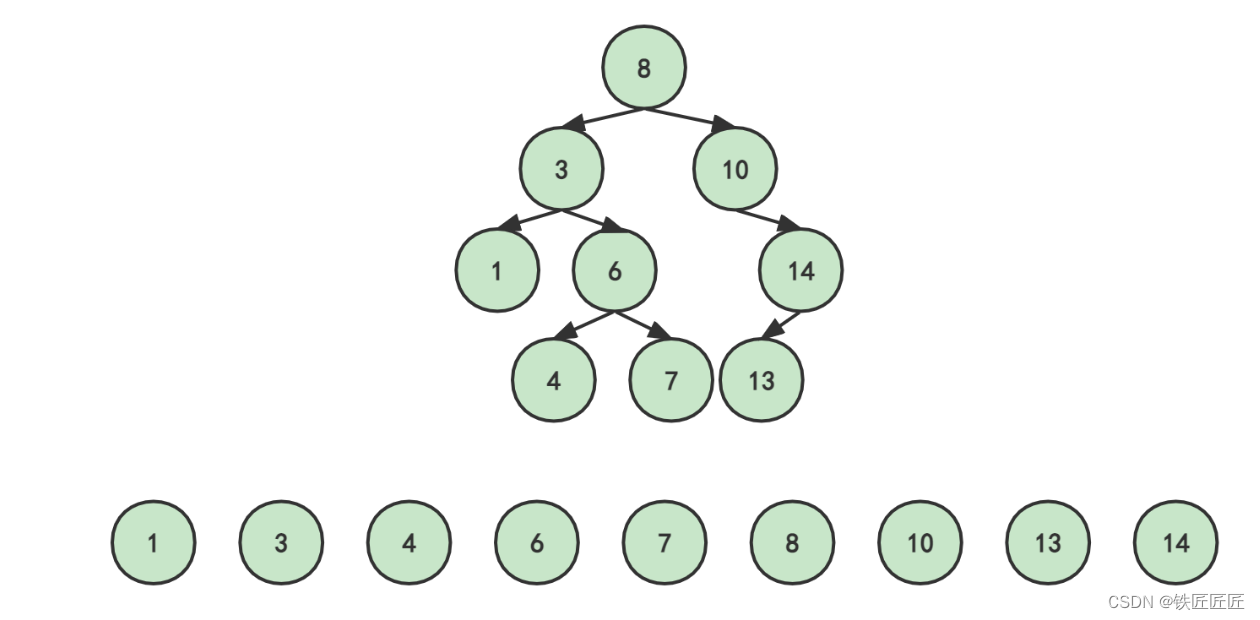
我们对这棵二叉树进行中序遍历,看看会发生什么?你自己试一试!
没错,这棵二叉树中序遍历结果为:
根据以上思路,我们其实就可以写出代码了,构建的过程其实就是插入的过程:
void bstInsert(TreeNode** T, int data)
{
if(*T == NULL)
{
*T = (TreeNode*)malloc(sizeof(TreeNode));
(*T)->data=data;
(*T)->lchild=NULL;
(*T)->rchild=NULL;
}
else if((*T)->data > data)
bstInsert(&((*T)->lchild),data);
else if((*T)->data == data)
return;
else
bstInsert(&((*T)->rchild),data);
}
二叉排序树的查找操作
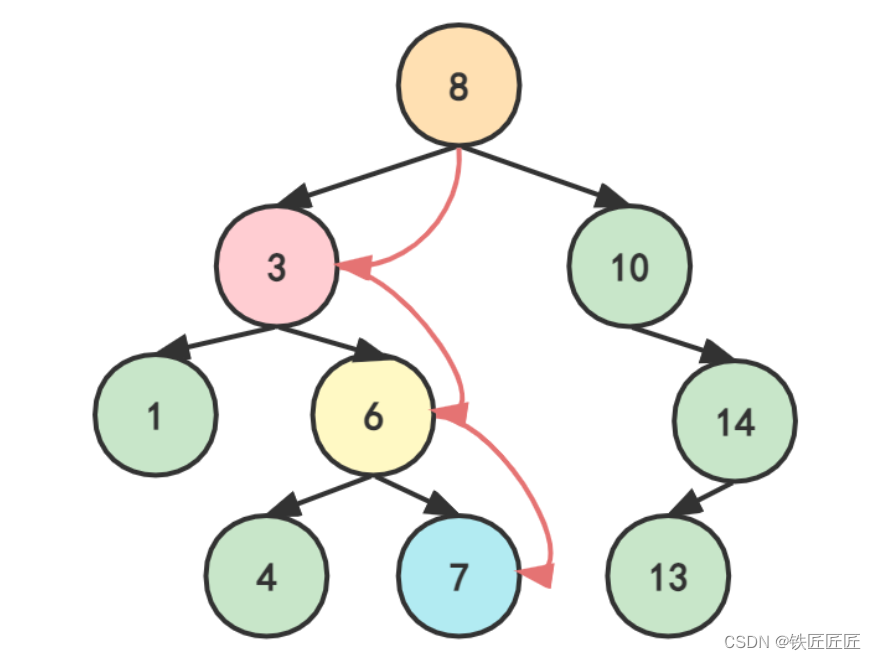
它既然也叫二叉查找树,那想必会非常方便我们查找吧!它的操作并不是把中序遍历的结果存入数组,然后在有序数组里查找,而是直接在树上查找。其操作与二分查找非常相似,我们来查找7试一试?(这里要说明以下:在正常的数据结构中,由于数据量很大,所以我们也不知道我们想要的元素在不在里面;同时也不知道每个元素具体是多少,只知道他们的大小关系。我们是在此基础上进行查找)
- 首先,访问根节点8
- 根据性质,7比8小,所以如果7存在,那应该在8的左子树那边,访问8的左子树
- 访问到了3,根据第2步的思想,访问3的右子树
- 访问到了6,继续访问6的右子树
- 访问到了7,刚好找到啦!
TreeNode* bstSearch(TreeNode* T, int data)
{
if (T) {
if (T -> data == data) {
return T;
}
else if (data < T -> data) {
return bstSearch(T -> lchild, data);
}
else {
return bstSearch(T -> rchild, data);
}
}
else {
return NULL;
}
}
总代码
#include <stdio.h>
#include <stdlib.h>
typedef struct TreeNode {
int data;
struct TreeNode* lchild;
struct TreeNode* rchild;
}TreeNode;
TreeNode* bstSearch(TreeNode* T, int data)
{
if (T) {
if (T -> data == data) {
return T;
}
else if (data < T -> data) {
return bstSearch(T -> lchild, data);
}
else {
return bstSearch(T -> rchild, data);
}
}
else {
return NULL;
}
}
void bstInsert(TreeNode** T, int data)
{
if(*T == NULL)
{
*T = (TreeNode*)malloc(sizeof(TreeNode));
(*T)->data=data;
(*T)->lchild=NULL;
(*T)->rchild=NULL;
}
else if((*T)->data > data)
bstInsert(&((*T)->lchild),data);
else if((*T)->data == data)
return;
else
bstInsert(&((*T)->rchild),data);
}
void preOrder(TreeNode* T)
{
if (T)
{
printf("%d ", T -> data);
preOrder(T -> lchild);
preOrder(T -> rchild);
}
}
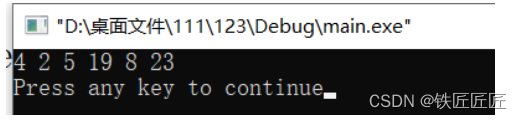
int main()
{
int i = 0;
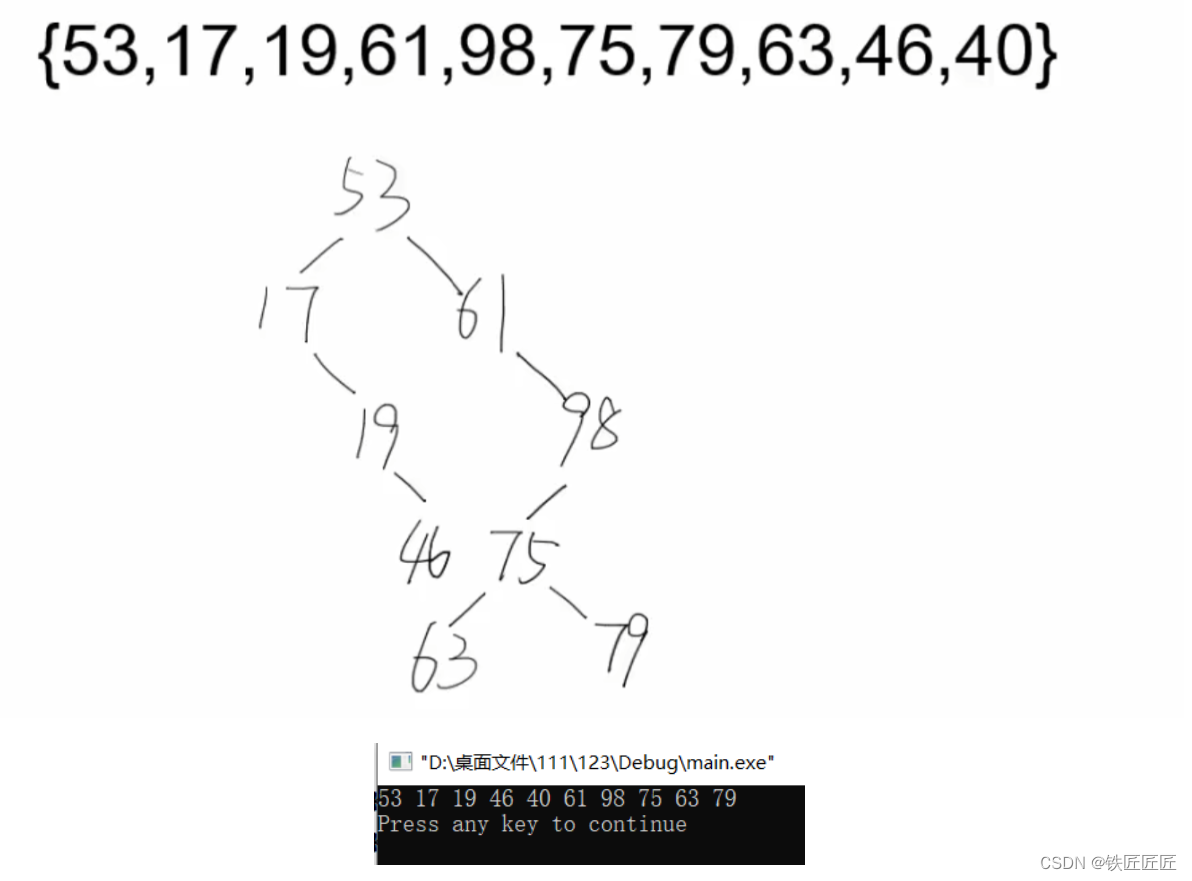
int nums[] = {53,17,19,61,98,75,79,63,46,40};
TreeNode* T = NULL;
for (; i < (sizeof(nums)/sizeof(int)); i++)
{
bstInsert(&T, nums[i]);
}
preOrder(T);
printf("\n");
}
往期回顾
1.【第一章】《线性表与顺序表》
2.【第一章】《单链表》
3.【第一章】《单链表的介绍》
4.【第一章】《单链表的基本操作》
5.【第一章】《单链表循环》
6.【第一章】《双链表》
7.【第一章】《双链表循环》
8.【第二章】《栈》
9.【第二章】《队》
10.【第二章】《字符串暴力匹配》
11.【第二章】《字符串kmp匹配》
12.【第三章】《树的基础概念》
13.【第三章】《二叉树的存储结构》
14.【第三章】《二叉树链式结构及实现1》
15.【第三章】《二叉树链式结构及实现2》
16.【第三章】《二叉树链式结构及实现3》
17.【第三章】《二叉树链式结构及实现4》
18.【第三章】《二叉树链式结构及实现5》
19.【第三章】《中序线索二叉树理论部分》
20.【第三章】《中序线索二叉树代码初始化及创树》
21.【第三章】《中序线索二叉树线索化及总代码》
22【第三章】《先序线索二叉树理论及线索化》
23【第三章】《先序线索二叉树查找及总代码》
24【第三章】《后续线索二叉树线索化理论》
25【第三章】《后续线索二叉树总代码部分》
26【第三章】《二叉排序树基础了解》















 1353
1353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









