






数据清洗
通常我们得到的数据都是一些脏数据(这里是指对数据分析没有意义,格式非法的数据),我们需要将这些数据进行过滤得到我们想要的数据,这就是所谓的数据清洗
空值和缺失值的处理
一般来说空值我们用 none表示,缺失值我们用nan表示,Pandas中提供了一些我们处理空值和缺失值的方法
isnull(obj)//如果数据当中存在none和nan,isnull()会返回布尔类型
notnull()函数//功能上与isnull一样的,isnull是遇见缺失值返回false,notnull遇见缺失值返回true
//dropna()方法的作用是删除含有空值或缺失值的行或列
//axis:确定过滤行或列,默认是0,按行过滤
dropna(axis=0, how='any', thresh=None)
//Pandas中的fillna()方法可以实现填充空值或缺失值
fillna(value=None, method=None, axis=None, inplace=False,limit=None)
//value:用于填充的数值。
//method:表示填充方式,默认值为None。ffill向前填充,bffill向后填充
//limit: 可以连续填充的最大数量,默认None
重复值的处理
//duplicated()方法用于标记是否有重复值。
duplicated(subset=none,keep='first')
//subset:用于识别重复的列标签或列标签序列,默认识别所有的列标签。
//keep:删除重复项并保留第一次出现的项,取值可以为first、last或False。
//drop_duplicates()方法用于删除重复值
drop_duplicates(subset=None, keep='first', inplace=False)
//inplace参数接收一个布尔类型的值,表示是否替换原来的数据,默认为False。

异常值处理
检测出异常值后,通常会采用如下四种方式处理这些异常值:
直接将含有异常值的记录删除。
用具体的值来进行替换,可用前后两个观测值的平均值修正该异常值。replace()
不处理,直接在具有异常值的数据集上进行统计分析。
视为缺失值,利用缺失值的处理方法修正该异常值
数据合并

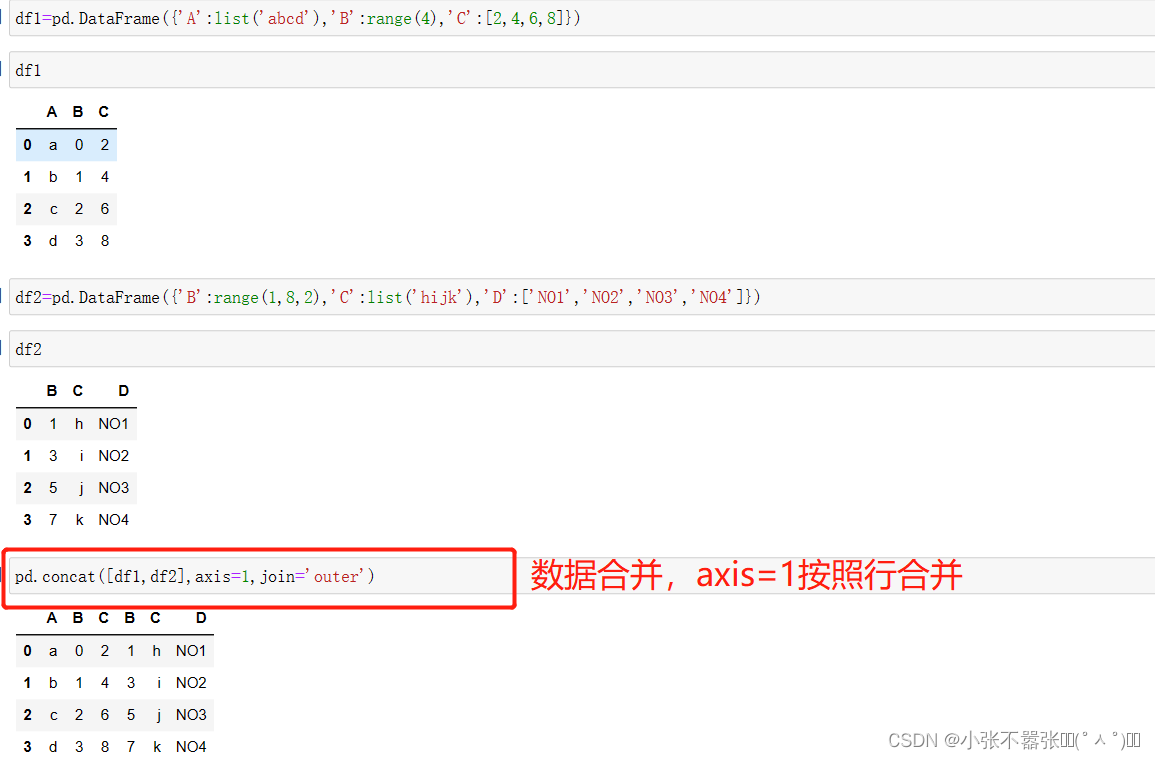
内外连接区别
在堆叠数据时,默认采用的是外连接(join参数设为outer)的方式进行合并,当然也可以通过join=inner设置为内连接的方式
主键合并类似于关系型数据库的连接方式,它是指根据一个或多个键将不同的DatFrame对象连接起来,大多数是将两个DatFrame对象中重叠的列作为合并的键。


在使用merge()函数进行合并时,默认会使用重叠的列索引做为合并键,并采用内连接方式合并数据,即取行索引重叠的部分。
数据重塑
Pandas中重塑层次化索引的操作主要是stack()方法和unstack()方法,前者是将数据的列“旋转”为行,后者是将数据的行“旋转”为列
df.stack(level=-1,drop=True)
//level:表示操作内层索引。若设为0,表示操作外层索引,默认为-1。
//dropna:表示是否将旋转后的缺失值删除,若设为True,则表示自动过滤缺失值,设置为False则相反。
unstack()# 方法可以将数据的行索引转换为列索引
数据转换
rename(mapper = None,index = None,columns = None,axis = None,copy = True,inplace = False,level = None)
cut ()#函数能够实现离散化操作,左闭右开
get_dummies()#对哑变量进行处理
离散化数据
简单来说就是将数据分成几个区间

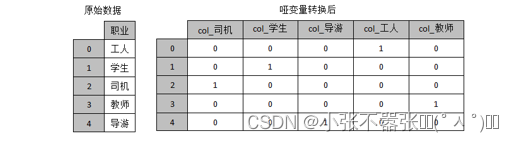
哑变量
哑变量又称虚拟变量、名义变量,从名称上看就知道,它是人为虚设的变量,用来反映某个变量的不同类别。使用哑变量处理类别转换,事实上就是将分类变量转换为哑变量矩阵或指标矩阵,矩阵的值通常用“0”或“1”表示














 1230
1230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









