







文章目录
C++函数
1、 sort 排序函数
1.1 头文件:algorithm
1.2 语法:
1.2.1 语法1:sort(数组的起始地址,数组的结束地址)
(默认升序排列) sort(a,a+5,lessr());
int a[5]={1,4,2,6,9,3};
sort(a,a+3); //将数组a的前三个元素排序
1.2.2 语法2:sort(数组的起始地址,数组的结束地址,比较函数)
(默认升序排列)
#include<iostream>
#include<algorithm>
using namespace std;
bool complare(int a,int b)
{
return a>b;
}
int main()
{
int a[10]={9,6,3,8,5,2,7,4,1,0};
for(int i=0;i<10;i++)
cout<<a[i]<<endl;
sort(a,a+10,complare);//这里就不需要对complare函数传入参数了
for(int i=0;i<10;i++)
cout<<a[i]<<endl;
return 0;
}
1.2.3语法3:整型降序排列:sort(a,a+10,greater< int >());
另一种降序排列方法:
bool cmp(int i, int j)
{
return i > j;
}
sort(c, c + n, cmp);
1.2.4语法4:字符型降序排列: sort(a,a+10,greater< char >());
#include<iostream>
#include<algorithm>
using namespace std;
int main()
{
char a[11]="asdfghjklk";
for(int i=0;i<10;i++)
cout<<a[i]<<endl;
sort(a,a+10,greater<char>());
for(int i=0;i<10;i++)
cout<<a[i]<<endl;
return 0;
}
2、memset 初始化函数
memset函数为初始化函数,可以将一段连续的内存初始化为某个值。
但它是以字节为单位进行初始化的。
格式:
memset(首地址,值,sizeof(地址总大小));
例:对数组a
memset(a,0,sizeof(a));
例:对char类型的数组a初始化,设置元素全为’1’
int main(){
char a[4];
memset(a,'1',4);
for(int i=0; i<4; i++){
cout<<a[i]<<" ";
}
return 0;
}
例:对int类型的数组a初始化,设置元素值全为1
int main(){
int a[4];
memset(a,1,sizeof(a));
for(int i=0; i<4; i++){
cout<<a[i]<<" ";
}
return 0;
}
3、abs、fabs 绝对值函数
4、getline 函数
5、substr 复制子字符串函数
5.1 语法:语法:substr(str,pos,len)
从 pos起,截取len个字符
5.2、头文件: string
5.3 用法:
5.3.1substr(string,1,3)
取string左边第1个位置起 ,3字节长的字符串
结果为str
5.3.2 substr(-1,3)
取string右边第1个位置起,3字节长的字符串
显然右边第一位置往右不够3字节,结果为g
5.3.3 substr(string,pos):pos
从开始的位置,截取到最后
5.3.4 substr(string,4)
从第4位置起,截取到最后,结果为ing
5.3.5 x[z]=s.substr(i,n);
截取s字符串中第i个元素起,n个字符,到x[z]数组
5.4 例题:
链接:https://ac.nowcoder.com/acm/contest/37344/L
来源:牛客网
题目描述
给定一个字符串,请你判断字符串中"HPU"的数目。
输入描述:
一行,一个字符串 S ,字符串的长度 1e7
输出描述:
一行,输出字符串中"HPU"的数目。
示例1
输入
HHHHHHPU
输出
1
示例2
输入
HPUUUHPU
输出
2
#include<iostream>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=1e7+10;
string a;
int cnt;
int main()
{
//gets(a);
cin>>a;
//int n=strlen(a);
//int n=sizeof(a);
//cout<<sizeof(a)<<endl;
for(int i=0;i<=a.size();i++)//注意怎么计算的字符串长度
{
//cout<<a.substr(i,3)<<endl;
if(a.substr(i,3)=="HPU")
cnt++;
}
cout<<cnt<<endl;
return 0;
}
6、unique去重函数
STL中的函数
注意:
1、这里的删除不是真的delete,而是将重复的元素放到容器末尾
2、 unique函数的返回值是去重之后的尾地址
3、 一定要先对数组进行排序才可以使用unique函数
#include <iostream>
#include <algorithm>
using namespace std;
int main()
{
int arr[10]= {5,8,4,12,6,8,9,5,10,3};
sort(arr,arr+10);//先排序
int len;//用一个len来记录无重复元素的数组的长度
len=unique(arr,arr+10)-arr;
for(int i=0; i<len; i++)
cout<<"arr["<<i<<"]="<<arr[i]<<endl;//输出排序后的数组
return 0;
}
注意:必须是有序数组才能用去重函数
#include<iostream>
#include<algorithm>//头文件
#include<functional>
using namespace std;
int main()
{
int i;
int a[10]={0,1,3,3,4,5,8,8,9,0};
sort(a,a+10,less<int>());//按从小到大的顺序
int n=unique(a,a+10)-a;//7,得到不重复元素的个数;
for(int i=0;i<n;i++)
{
cout<<a[i]<<" ";
}
}
#include <iostream>
#include <algorithm> //sort(), unique()
#include <functional> //less<int>()
#include<string>
using namespace std;
int main()
{
/字符串的去重排序
string str = "sjscncmkzmxkz";
sort(str.begin(), str.end()); //先对字符串排序;
string::iterator itend = unique(str.begin(), str.end()); //返回出现重复元素的首地址;
cout << str << endl;
str.erase(itend, str.end()); //删除重复元素;
cout << str << endl;
数组的去重排序;
int a[10] = { 0, 7, 7, 6, 1, 1, 5, 5, 8, 9 };
sort(a, a + 10, less<int>()); //排序
int n = unique(a, a + 10) - a; //去重
int n1 = distance(a, unique(a, a + n)); //获得不重复元素的个数;
for (int i = 0; i < n1; i++) //注意i < n
cout << a[i] << " "; //0 1 5 6 7 8 9
}
7、求最大公约数gcd
方法一、最简单易懂
#include<iostream>
using namespace std;
int gcd(int a,int b)
{
for(int i=1000;i;i--)
if(a%i==0&&b%i==0)
return i;
return -1;
}
int main()
{
int a,b;
cin>>a>>b;
cout<<gcd(a,b)<<endl;
return 0;
}
方法二、辗转相除法
#include<iostream>
using namespace std;
int gcd(int a,int b)
{
if(a%b==0)
return b;
else
return gcd(b,a%b);
}
int main()
{
int a,b;
cin>>a>>b;
cout<<gcd(a,b);
return 0;
}
7.1 三目运算符(较快)(自定义)
//三目运算符
inline int gcd(int a,int b)
{
return b>0 ? gcd(b,a%b):a;
}
7.2 if+while+位运算(超快)(自定义)
( 此段代码a、b可以为0 )
inline int gcd(int a,int b)
{
if(b) while((a%=b) && (b%=a));
return a+b;
}
7.3 辗转相除法(较快)(自定义)
欧几里得算法:辗转求余
原理: gcd(a,b)=gcd(b,a mod b)
当b为0时,两数的最大公约数即为a
(此段代码a、b不能为0)
inline int gcd(int a,int b)
{
if(a%b==0)
return b;
else
return (gcd(b,a%b));
}
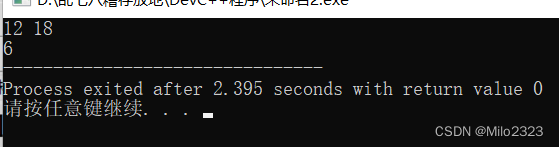
7.4 最大公约数函数:__gcd(n,m)(库函数)
#include<iostream>
#include<algorithm>
using namespace std;
int main()
{
int n,m;
cin>>n>>m;
cout<<__gcd(n,m);//头文件<algorithm>
return 0;
}
运行结果:
自定义函数
1、cmp比较函数
1.1 比较日期A与日期B(日期为年月日形式)
注意输入格式 用const struct Date &A
//int cmp(const struct Date &A,const struct Date &B)
struct Date//先定义一个日期结构体
{
int year;
int month;
int day;
}a[1000];
int cmp(Date A,Date B)
{
if(A.year!=B.year)
return A.year<B.year;
else if(A.month!=B.month)
return A.month<B.month;
else
return A.day<B.day;
}
2、素数判断函数
bool isprime(int n)
{
//特判一下
if (n < 2)
{
return false;
}
//记得不要写成i<n/i;
for (int i = 2; i <= n / i; i++)
{
if (n % i == 0)
{
return false;
}
}
return true;
}
3、回文判断函数
bool huiwen(int x)
{
int y = 0, temp = x;
while (x)
{
y = y * 10 + x % 10;
x /= 10;
}
return temp == y;
}
3.1素数回文(输出a与b之间的素数回文数)
#include<iostream>
#include<cstring>
using namespace std;
int a[1000];
int n;
// 素数判断函数
bool isprime(int n)
{
//特判一下
if (n < 2)
{
return false;
}
//记得不要写成i<n/i;
for (int i = 2; i <= n / i; i++)
{
if (n % i == 0)
{
return false;
}
}
return true;
}
//回文判断函数
bool huiwen(int x)
{
int y = 0, temp = x;
while (x)
{
y = y * 10 + x % 10;
x /= 10;
}
return temp == y;
}
int main()
{
int a, b;
while (~scanf_s("%d%d", &a, &b))
{
for (int i = a; i <= b; i++)
{
if (huiwen(i) && isprime(i))
{
cout << i << endl;
}
}
}
return 0;
}















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









