







文章目录
1.编写计算偏斜度和峭度的函数。并用自己编写的函数计算课本23页的习题1.5数据的偏斜度和峭度。
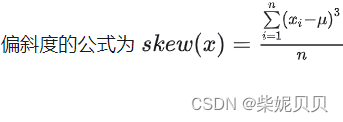
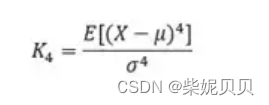
方法一:(套公式)
import random
import numpy as np
import pandas as pd
data = pd.read_excel("E:\习题1.5数据.xlsx")
data = np.array(data)
data_var = np.var(data) # 计算方差
data_mean = np.mean(data) # 计算均值
data_skewness = np.mean((data-data_mean)**3) # 计算偏斜度
data_kurtosis = np.mean((data-data_mean)**4)/pow(data_var,2) - 3 # 计算峭度
print('偏斜度和峭度:')
print(data_skewness,data_kurtosis,sep='\n')
方式二:(直接函数调用)
import scipy.stats as stats
data_skewness = stats.skew(data)
data_kurtosis = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 904
904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











