






ModelScope 魔搭社区部署模型
1. 用户如何在魔搭社区一键部署模型?
魔搭开源社区的模型库中有很多热门开源模型支持一键部署,支持用户在模型库列表页面选择支持快速部署的模型,然后点击进入模型详情页,其中模型详情页的右上角包含有部署按钮,可以进行快速部署。
- 模型列表页:过滤支持模型部署的模型列表
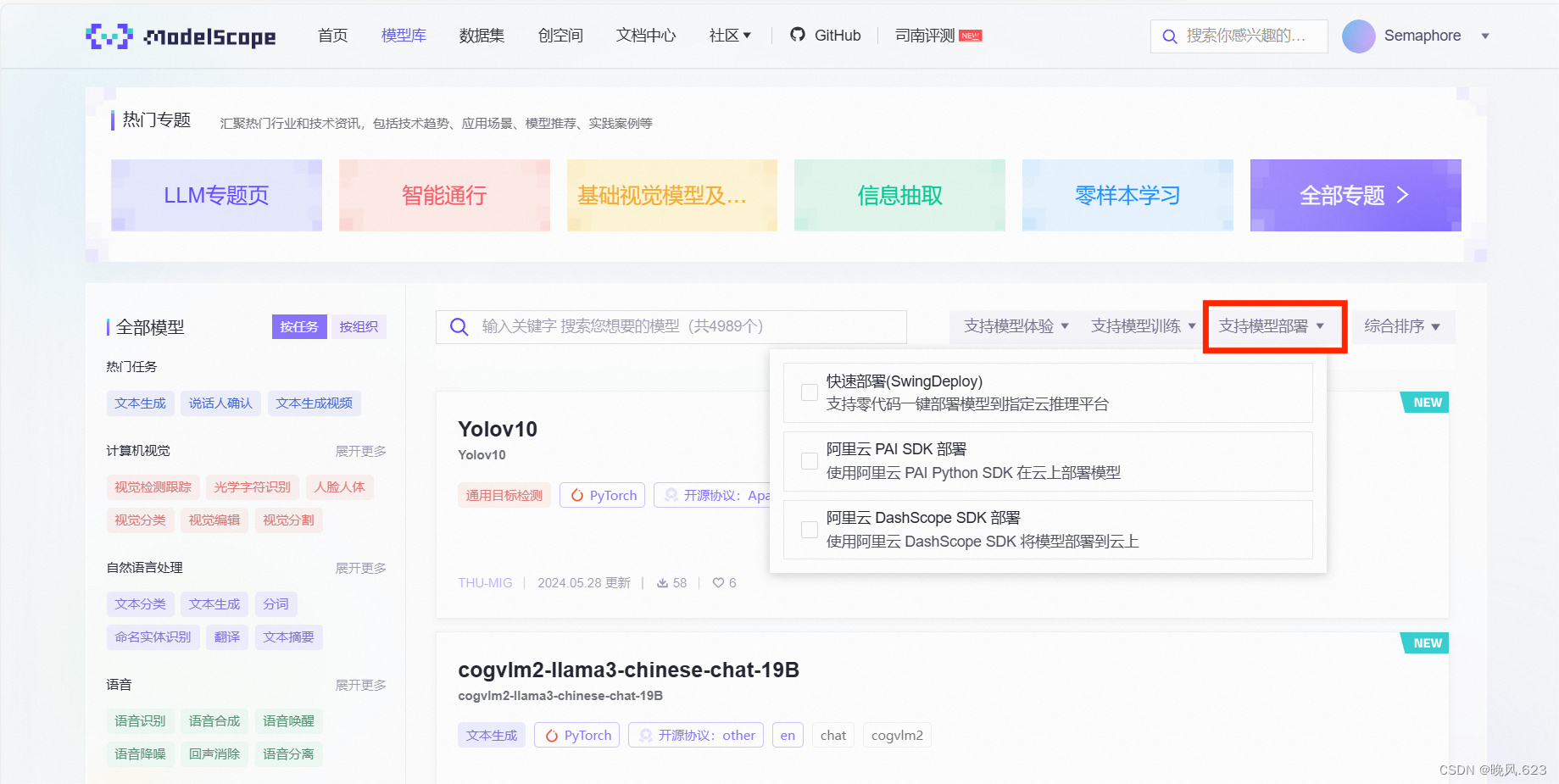
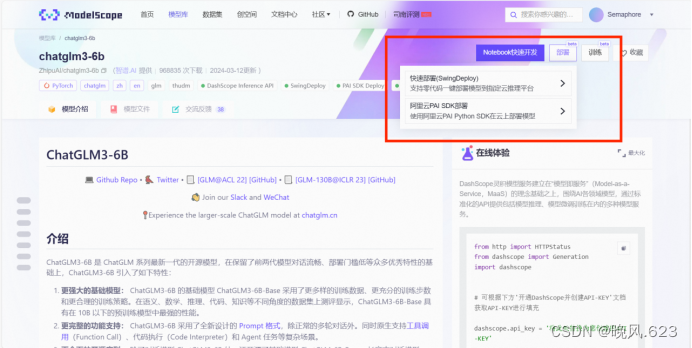
- 模型详情页:右上快速部署,这里以chatglm3-6b为例,该模型支持快速部署和训练服务。
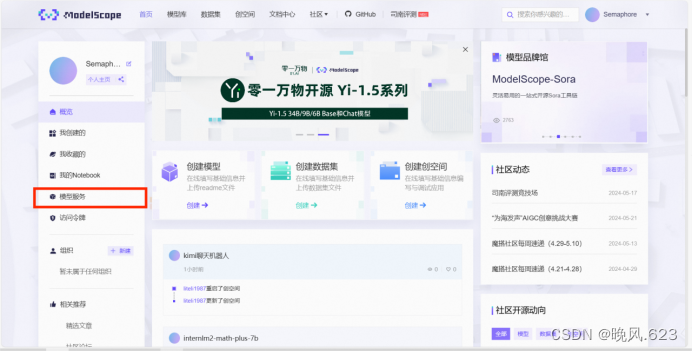
另外,也可以切换至首页,通过左侧【模型服务】进入模型部署服务页面。
在新建快速部署后,用户可以针对模型部署信息进行配置,包括必要的部署模型版本、部署地域、部署卡型、部署显存等。
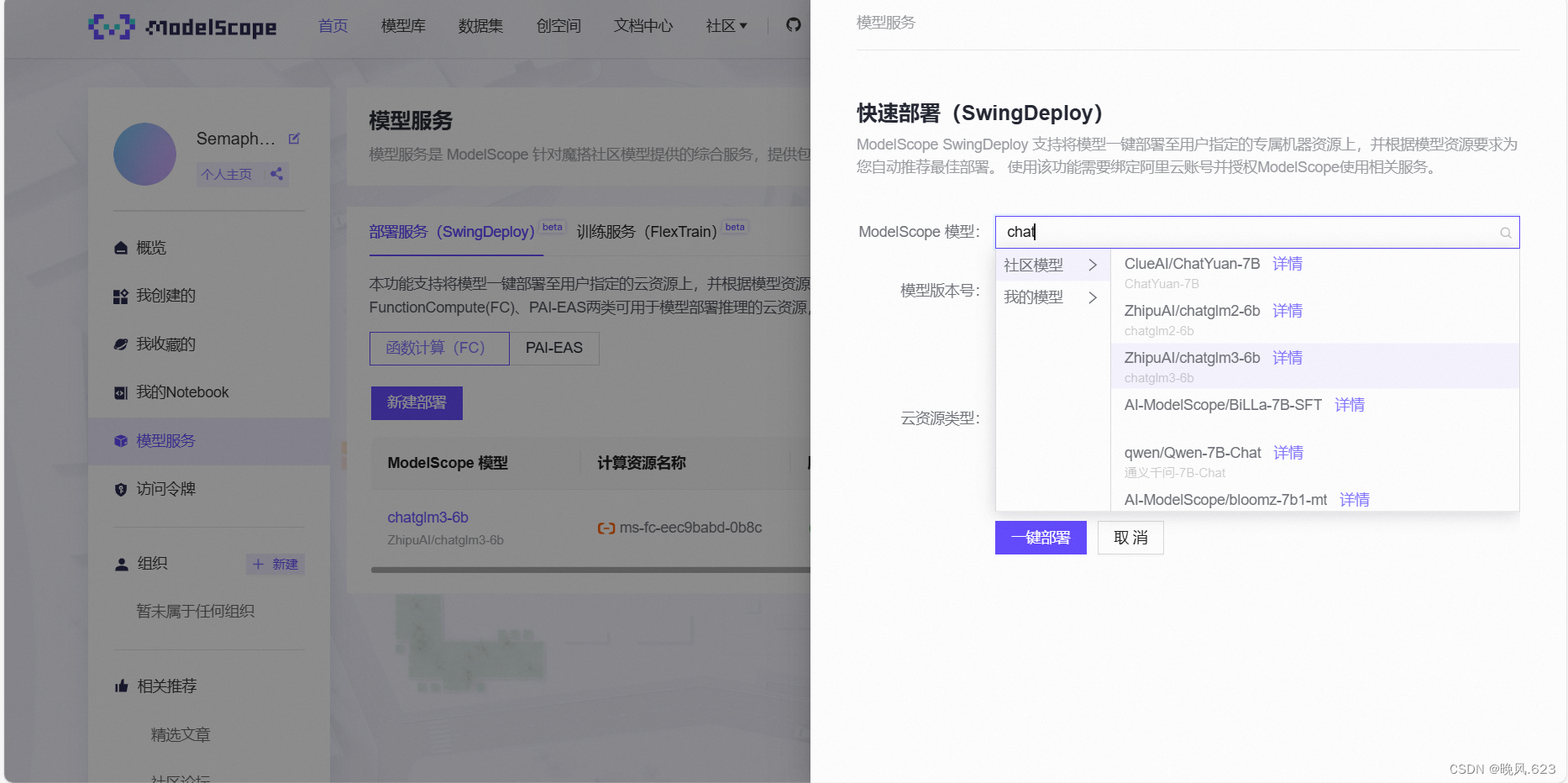
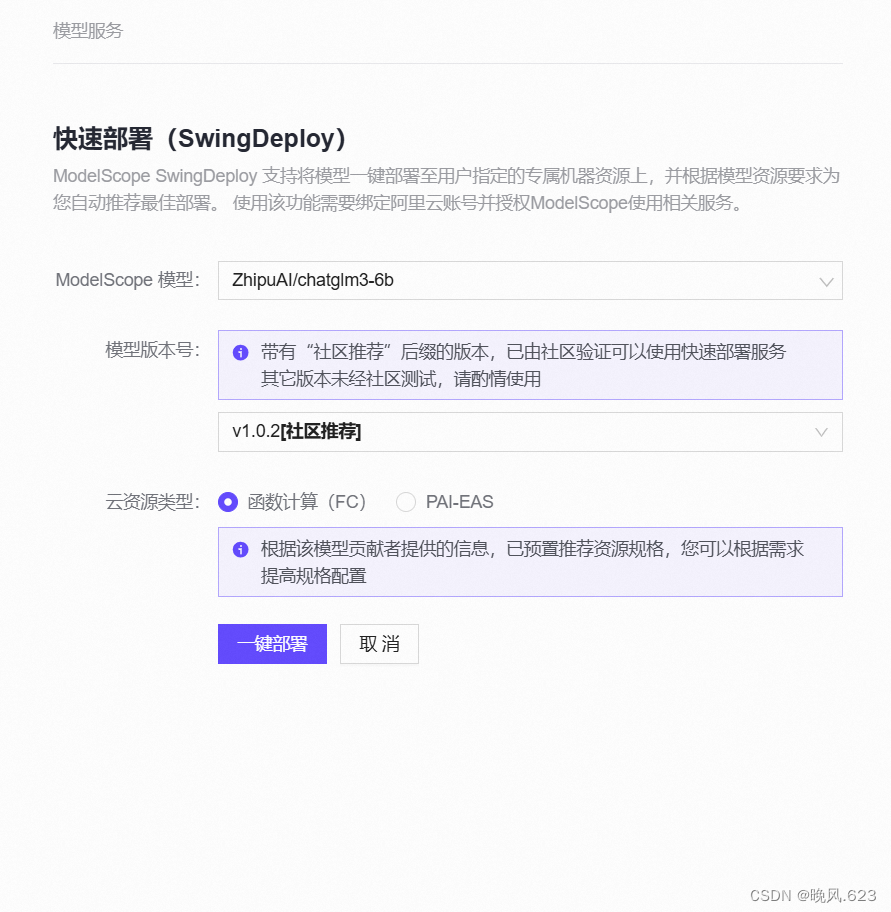
当用户点击确认快速配置无误后,通过点击【一键部署】按钮,从而进入部署过程;整个过程一般持续1-5分钟,当部署完成后,可以看到服务状态切换为【部署成功】。

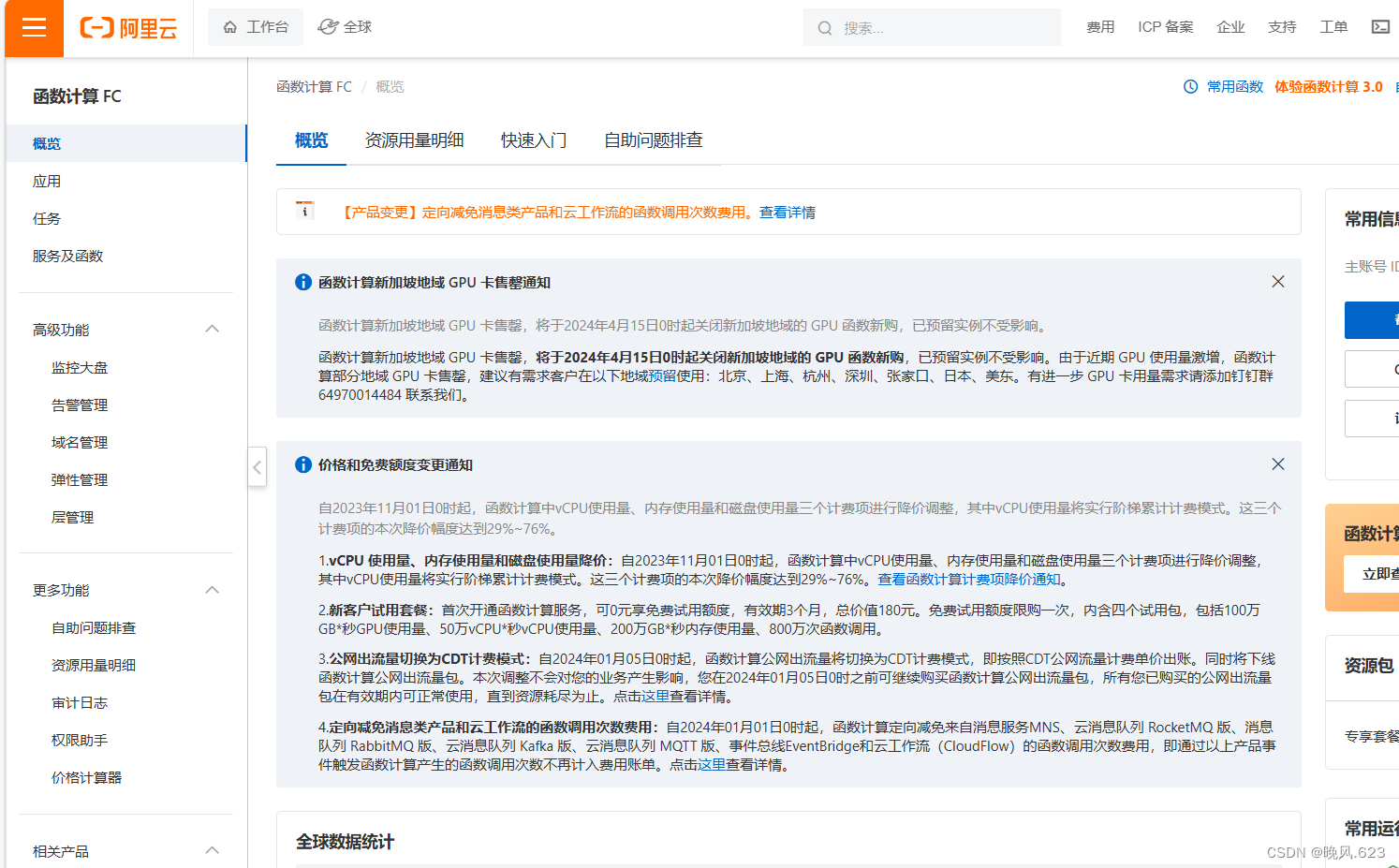
2. 用户在魔搭一键部署模型到阿里云函数计算FC后,实际在FC部署了什么?
当用户将魔搭开源模型一键部署(SwingDeploy)到阿里云函数计算FC后,实际上是在阿里云函数计算FC平台创建了对应的服务与函数。函数计算平台在收到该函数的推理请求调用后,会根据服务和函数的配置来创建对应的CPU/GPU容器实例。函数实例处理完请求后,再由平台将响应返回给用户。对应的CPU/GPU容器实例空闲一段时间没有处理调用请求后,函数计算平台会将其释放。所以默认情况下,空闲未使用的服务/函数没有资源消耗,函数计算仅对请求处理部分计费。使用魔搭的“模型服务”SwingDeploy一键部署模型到函数计算后,可以在部署列表中看到“服务名称”,使用服务名称可以到函数计算控制台相应地域的服务列表找到部署好的服务和函数。
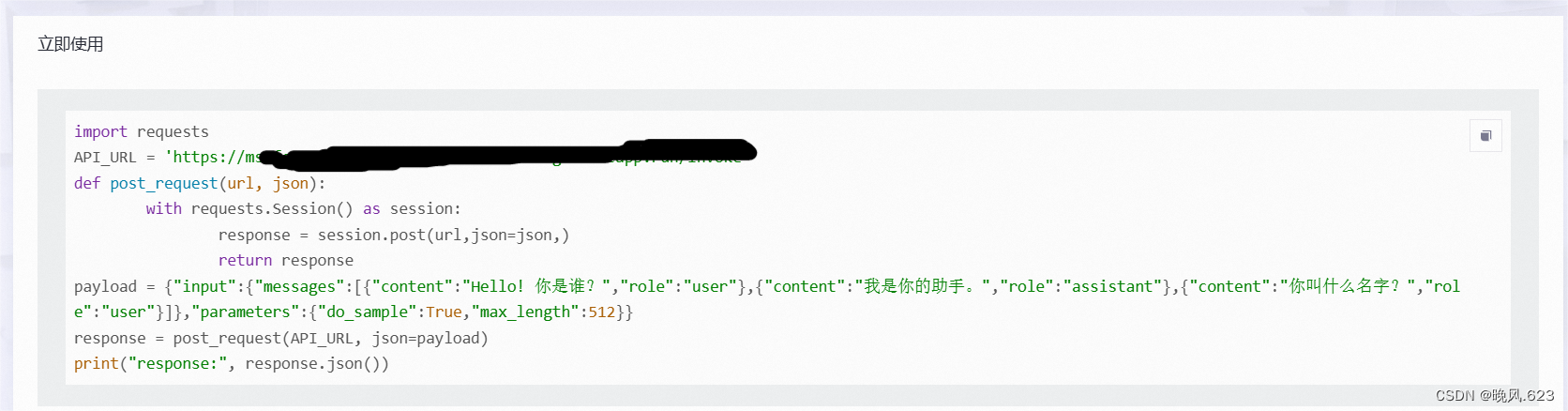
3. 用户如何调用部署在FC的模型?
在已部署的模型处点击详情后,用户可以通过魔搭平台提供的示例代码调用已部署好的模型。

4. 部署在FC的模型首次调用耗时长,后续调用耗时短。
函数如果长时间空闲(没有推理调用发生),FC平台会通过回收函数容器实例来释放资源。函数计算平台在收到一个调用请求后,会判断当前是否有空闲的函数容器实例可供使用,如果没有,则需要新创建一个函数容器实例来服务该请求,这个过程称之为冷启动。
如果函数应用本身初始化时间耗时较长(比如应用三方依赖加载、大模型初始化),那么该函数容器实例上发生的初次推理请求的端到端时延也会增加,例如,初始化较大的模型文件(ChatGLM-6B模型文件15GB、QWen Chat 14GB)。为了应对LLM大模型场景,函数容器实例按照弹性规则,可以分为按量和预留两种模式。
在FC控制台中,可以在函数详情的“弹性管理”选项卡配置弹性规则;弹性管理的详细配置方法详见文档。
例如:可以通过如下操作指导,预留指定数量的GPU实例(测试目的:一般建议预留1个GPU实例)。
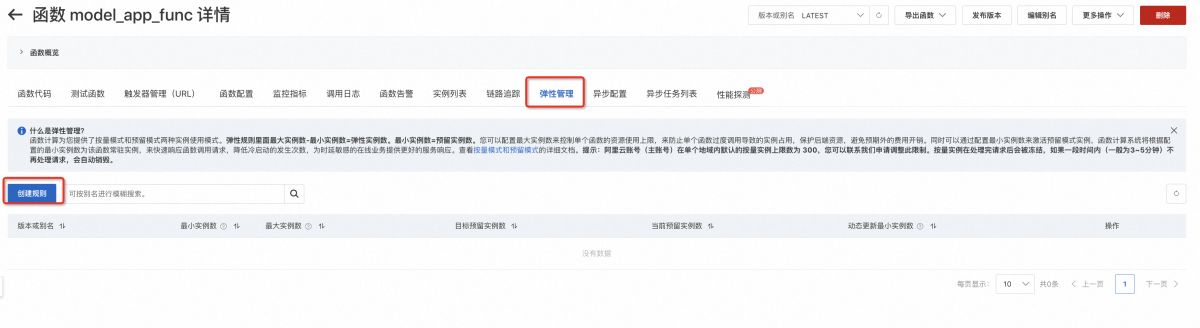
切换至函数的弹性管理Tab页
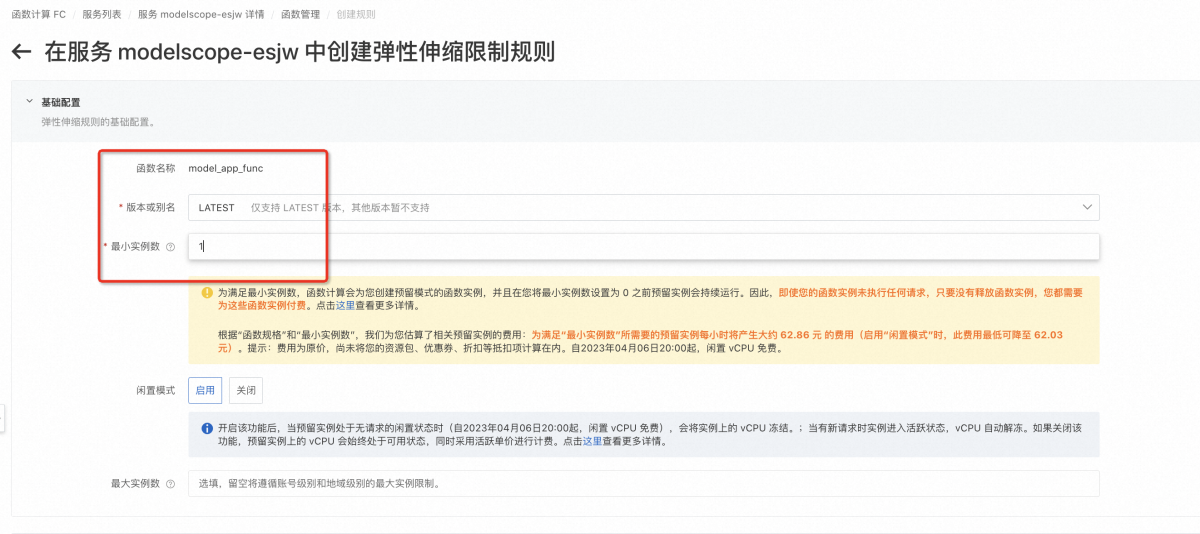
设置函数的LATEST版本,至少预留1个GPU实例
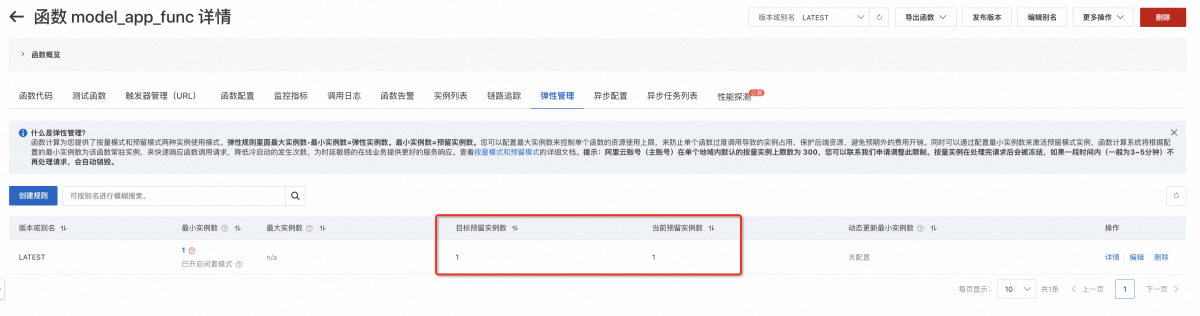
查看当前预留实例数量,是否满足目标预留实例数量。(上图表明完成指定数量的GPU实例预留)
当预留实例就绪后,推理请求调用会被优先分配至该预留实例上执行,从而规避按量场景下的冷启动。
用户可以通过请求级别的日志观测,来查看请求是由按量实例服务、还是预留实例服务。
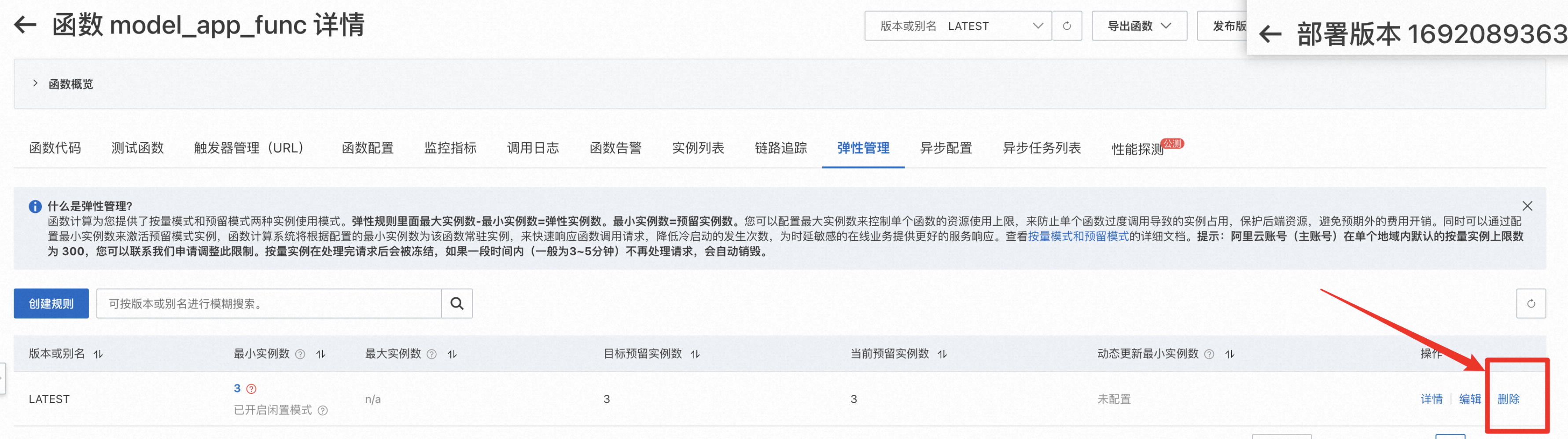
通过删除弹性规则,可以删除对应预留实例。
注意:预留实例的生命周期,完全由用户全权负责。















 1241
1241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









