






山东大学计算机科学与技术学院机器学习实验5
实验题目:SVM
实验学时:4
实验目的:
这个实验的目的主要是熟练使用支持向量机(SVM)进行线性和非线性分类,并通过实际的数据集来评估和调整模型的性能。具体来说,实验分为三个部分:
- SVM实现与调参: 在第一部分,需要实现一个正则化的SVM分类器,使用不同的数据集进行训练和测试。通过调整正则化参数C,观察模型性能的变化。
- 手写数字识别: 第二部分要求将训练好的SVM模型应用于手写数字的识别任务。使用不同的数据集,并需要处理图像数据以进行分类。
- 非线性SVM: 最后一部分引入了非线性SVM,通过使用径向基函数(RBF)核来实现。需要训练SVM模型,可视化决策边界,并尝试不同的RBF参数(γ)以观察对决策边界的影响。
总体来说,这个实验旨在掌握SVM的基本原理和应用,并通过实际的编程和实验来加深理解。
实验步骤与内容:
① 首先读取数据集
1.打开指定的文件,获取文件标识符。
2.通过循环读取文件的每一行,将数据存储在单元格数组中。
3.初始化一个网格数组 grid 和标签数组 label,用于存储图像数据和相应的标签。
4.遍历每一行,提取字符数据,并将其转换为字符数组。
5.解析字符数组,提取像素索引和相应的灰度值,存储在 xy 中。
6.提取标签信息并存储在 label 中。
7.将灰度值映射到网格数组中,生成有颜色的图像。
8.将处理后的网格数组和标签数组存储在一个结构体 svm 中,并作为函数的输出。
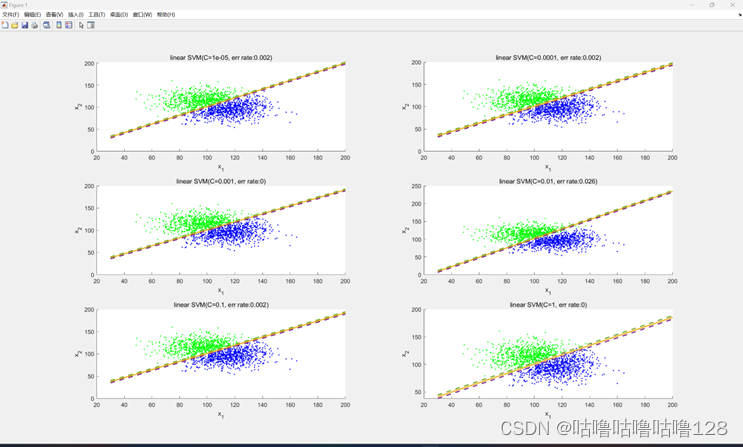
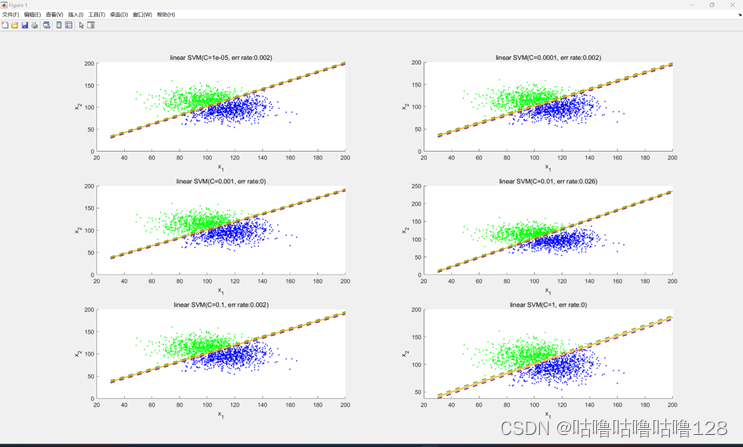
② 线性SVM
1.加载数据: 从文件中读取训练数据和测试数据。
2.初始化变量: 将正负样本、输入特征x和标签y进行设置。
3.训练SVM模型: 使用二次规划算法训练SVM模型,通过循环调整正则项参数C的大小。
4.绘制决策边界和支持向量: 在每次迭代中,计算并绘制决策边界和支持向量。
5.计算测试误差: 在测试集上计算误分类率。
6.绘制图形: 使用subplot显示每个不同C值下的决策边界和支持向量,观察它们在不同正则项参数下的变化。
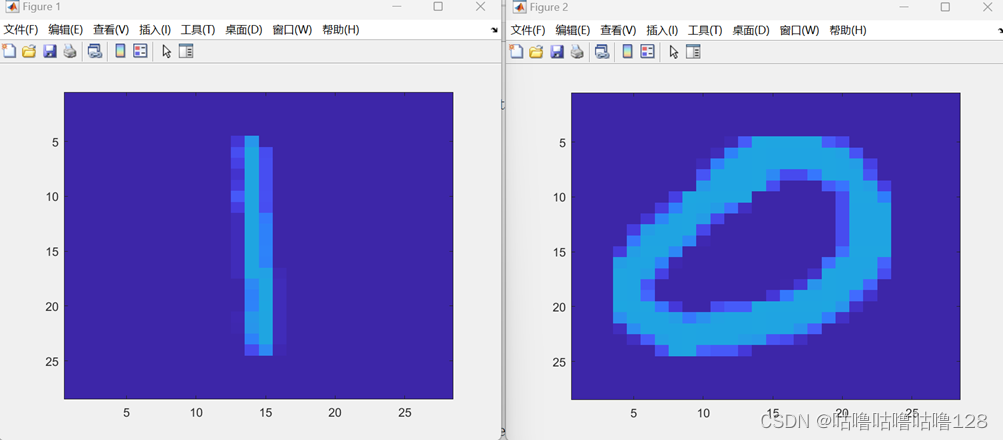
③ 手写数字识别
1.加载数据: 从文件中加载手写数字的训练和测试数据。
2.随机选择样本: 从所有训练和测试样本中,随机选择1000个训练样本和2115个测试样本。
3.无正则项的线性SVM分类: 使用线性核进行SVM分类,没有使用正则项。通过predict2函数在选择的训练和测试样本上进行分类,记录被错误分类的样本的索引。
4.显示错误分类的手写数字图像: 对于被错误分类的训练样本,从训练集中加载相应的手写数字图像并显示。同样,对于被错误分类的测试样本,从测试集中加载相应的手写数字图像并显示。
Predict2函数:
1.准备训练数据: 从给定的训练数据中提取输入特征和标签。
2.训练SVM模型: 使用二次规划(quadprog)求解SVM问题,得到支持向量和相应的权重和偏置。
3.准备测试数据: 从给定的测试数据中提取输入特征和标签。
4.测试SVM模型: 使用训练得到的SVM模型在测试数据上进行预测,计算并返回被 错误分类的测试样本的索引。
5.打印详细信息: 输出关于模型性能的详细信息,包括正类别和负类别的预测准确 率等。、
错误分类图片
④ 高维SVM
1.准备训练数据: 从给定的训练数据中提取输入特征和标签。
2.训练SVM模型: 使用二次规划(quadprog)求解SVM问题,得到支持向量和相应的权重和偏置。
3.绘制训练数据: 将正例和负例的训练样本在二维空间中用绿色和蓝色的点表示。
4.绘制决策边界和支持向量: 使用计算得到的SVM参数,在二维空间中绘制SVM的决策边界和支持向量。
5.绘制等高线: 使用contour函数绘制SVM的决策边界,其中颜色渐变表示决策函数的值。

⑤SMO算法
1.初始化: 初始化一些必要的参数,如样本数量(sampleNum)、权重(alpha)、偏置(bias)、迭代次数(iteratorTimes)、正则项参数(C)、最大迭代次数(maxItertimes)和容忍度(tolerance)。
2.计算核函数: 计算样本之间的核函数矩阵 K。
3.SMO主循环: 在主循环中,首先选择一个样本 i,然后根据 KKT 条件选择第二个样本 j,接着尝试更新 alpha1 和 alpha2。
4.计算新的 alpha2: 根据 SMO 算法的规则,计算新的 alpha2。
5.更新 alpha1: 根据 SMO 算法的规则,计算新的 alpha1。
6.更新偏置 bias: 根据新的 alpha1 和 alpha2,更新偏置 bias。
7.迭代次数增加: 更新迭代次数 iteratorTimes。
8.循环结束条件: 当达到最大迭代次数或者所有样本都满足 KKT 条件时,循环结束。
结论分析与体会:
首先,支持向量机是一种强大的机器学习算法,通过优化问题的对偶形式,实现对线性和非线性分类的高效求解。SMO算法作为其中的一种求解方法,通过选择样本对,迭代更新优化目标,最终得到模型参数。代码中的SVM实现展示了对线性分类问题的求解,通过选择不同的正则项参数C,可以调整模型的拟合程度,进而影响决策边界和支持向量。
其次,手写数字识别部分展示了如何利用SVM对图像进行分类。代码中通过提取局部二值模式(Local Binary Pattern, LBP)特征,训练SVM模型,实现了0和1的分类。通过调整正则项参数C,可以观察模型在训练和测试数据上的表现,并进一步优化模型的泛化能力。
最后,非线性SVM部分通过引入径向基函数(Radial Basis Function, RBF)核函数,实现了对非线性数据的分类。代码展示了如何使用RBF核函数构建高维特征空间,通过SVM实现复杂决策边界的绘制。通过调整核函数参数γ,可以观察决策边界的变化,进一步了解核函数在非线性分类中的作用。
总体而言,这些代码展示了SVM在不同场景下的应用,以及参数调整对模型性能的影响。通过实践这些例子,能够更深入理解SVM的工作原理和调参技巧,为实际问题的应用提供有力支持。同时,代码的注释和结构清晰,使得算法实现易于理解和修改。
附录:程序源代码
数据处理:
1. svm1 = re_hand_digits('data5/train-01-images.svm',12665);
2. svm2 = re_hand_digits('data5/test-01-images.svm',2115);
3. train_x = svm1.grid; train_y = svm1.label;
4. test_x = svm2.grid; test_y = svm2.label;
5. train = [train_x,train_y];
6. test = [test_x,test_y];
7.
8. [row,col] = size(test);
9. fid=fopen('hand_digits_test.dat','wt');
10. for i=1:1:row
11. for j=1:1:col
12. if(j==col)
13. fprintf(fid,'%g\n',test(i,j));
14. else
15. fprintf(fid,'%g\t',test(i,j));
16. end
17. end
18. end
19. fclose(fid);
20.
21. [row,col] = size(train);
22. fid=fopen('hand_digits_train.dat','wt');
23. for i=1:1:row
24. for j=1:1:col
25. if(j==col)
26. fprintf(fid,'%g\n',train(i,j));
27. else
28. fprintf(fid,'%g\t',train(i,j));
29. end
30. end
31. end
32. fclose(fid);
33.
1. function svm = re_hand_digits(filename,n)
2. fidin = fopen(filename);
3. i = 1;
4. apres = [];
5.
6. while ~feof(fidin)
7. tline = fgetl(fidin); % 从文件读行
8. apres{i} = tline;
9. i = i+1;
10. end
11.
12. grid = zeros(n,784);
13. label = zeros(n,1);
14. for k = 1:n
15. a = char(apres(k));
16. lena = size(a,2);
17. xy = sscanf(a(4:lena), '%d:%d');
18. label(k,1) = sscanf(a(1:3),'%d');
19. lenxy = size(xy,1);
20. for i=2:2:lenxy %% 隔一个数
21. if(xy(i)<=0)
22. break
23. end
24. grid(k,xy(i-1)) = xy(i) * 100/255; %转为有颜色的图像
25. end
26. end
27. svm.grid = grid;
28. svm.label = label;
29. end
30.
核函数:
1. function K = kernel(X,Y,type,gamma)
2. switch type
3. case 'linear' %线性核
4. K = X*Y';
5. case 'rbf' %高斯核
6. m = size(X,1);
7. K = zeros(m,m);
8. for i = 1:m
9. for j = 1:m
10. K(i,j) = exp(-gamma*norm(X(i,:)-Y(j,:))^2);
11. end
12. end
13. end
14. end
线性SVM预测:
1. function [test_miss,train_miss] = predict2(train_data_name,test_data_name,kertype,gamma,C)
2. %(1)-------------------training data ready-------------------
3. train_data = train_data_name;
4. n = size(train_data,2);
5. train_x = train_data(:,1:n-1);
6. train_y = train_data(:,n);
7.
8. %(2)-----------------training model-------------------
9. %二次规划用来求解问题,使用quadprog
10. n = length(train_y);
11. H = (train_y*train_y').*kernel(train_x,train_x,kertype,gamma);
12. f = -ones(n,1); %f'为1*n个-1
13. A = [];
14. b = [];
15. Aeq = train_y';
16. beq = 0;
17. lb = zeros(n,1);
18. if C == 0 %无正则项
19. ub = [];
20. else %有正则项
21. ub = C.*ones(n,1);
22. end
23. train_a = quadprog(H,f,A,b,Aeq,beq,lb,ub);
24. epsilon = 2e-7;
25. %找出支持向量
26. sv_index = find(abs(train_a)> epsilon & (C - train_a) > epsilon);
27. Xsv = train_x(sv_index,:);
28. Ysv = train_y(sv_index);
29. svnum = length(sv_index);
30. train_w(1:784,1) = sum(train_a.*train_y.*train_x(:,1:784));
31. train_b = sum(Ysv-Xsv*train_w)/svnum;
32. train_label = sign(train_x*train_w+train_b);
33. train_miss = find(train_label~=train_y);
34.
35. %(3)-------------------testing data ready----------------------
36. test_data = test_data_name;
37. m = size(test_data,2);
38. test_x = test_data(:,1:m-1);
39. test_y = test_data(:,m);
40. test_label = sign(test_x*train_w+train_b);
41. test_miss = find(test_label~=test_y);
42.
43. %(4)------------------detail -----------------------;
44. %print the detail
45. fprintf('--------------------------------------------\n');
46. fprintf('C = %d\n',C);
47. fprintf('number of test data label: %d\n',size(test_data,1));
48. fprintf('number of train data label: %d\n',size(train_data,1));
49. fprintf('predict corret number of test data label: %d\n',length(find(test_label==test_y)));
50. fprintf('predict corret number of train data label: %d\n',length(find(train_label==train_y)));
51. fprintf('Success rate of test data: %.4f\n',length(find(test_label==test_y))/size(test_data,1));
52. fprintf('Success rate of train data: %.4f\n',length(find(train_label==train_y))/size(train_data,1));
53. fprintf('--------------------------------------------\n');
54. end
手写数字识别:
1. train_data = load('hand_digits_train.dat');
2. test_data = load('hand_digits_test.dat');
3. train_len = size(train_data,1); test_len = size(test_data,1);
4. train_index = randperm(train_len,1000);
5. test_index = randperm(test_len,2115);
6. train_select = zeros(1000,785);
7. test_select = zeros(2115,785);
8. for i = 1:1000
9. train_select(i,:) = train_data(train_index(i),:);
10. end
11. for i = 1:2115
12. test_select(i,:) = test_data(test_index(i),:);
13. end
14.
15. %无正则项
16. [train_miss_index,test_miss_index] = predict2(train_select,test_select,'linear',0,100);
17. %查看被错误分类的手写字体
18. %训练错误手写字体
19. for i = 1:length(train_miss_index)
20. strimage('data5/train-01-images.svm',train_miss_index(i));
21. if i~=length(train_miss_index)
22. figure;
23. end
24. end
25. %测试错误手写字体
26. for i = 1:length(test_miss_index)
27. strimage('data5/test-01-images.svm',test_miss_index(i));
28. if i~=length(test_miss_index)
29. figure;
30. end
31. end
32. h=figure(1);
33.
34. set(h,'visible','on')
SMO算法:
1.
% to fix
2. function [alpha, bias] = SMO(Features, Labels, C, maxItertimes, tolerance)
3.
4. % init
5.
6. [sampleNum,b ] = size(Features);
7. alpha = zeros(sampleNum, 1);
8. bias = 0;
9. iteratorTimes = 0;
10.
11. K = Features * Features'; % 计算K
12. while iteratorTimes < maxItertimes
13. % find alpha1
14. for i = 1 : sampleNum
15. g1 = (alpha .* Labels)' * (Features * Features(i, :)') + bias;
16. Error1 = g1 - Labels(i);
17. % choose i: voilate KKT conditions
18. if(((Error1 * Labels(i) < -tolerance) && alpha(i) < C) ||...
19. ((Error1 * Labels(i) > tolerance) && alpha(i) > 0))
20. % choose j: different from i
21. j = i;
22. while j == i
23. j = randi(sampleNum); % 随机另外一个alpha2
24. end
25.
26. % 尝试更新alpha1和alpha2
27. alpha1 = alpha(i, 1);
28. alpha2 = alpha(j, 1);
29. y1 = Labels(i); y2 = Labels(j);
30.
31. g2 = (alpha .* Labels)' * (Features * Features(j, :)') + bias;
32. Error2 = g2 - Labels(j);
33.
34. % 计算Lower bound和Higher bound
35. if y1 ~= y2
36. L = max(0, alpha2 - alpha1);
37. H = min(C, C + alpha2 - alpha1);
38. else
39. L = max(0, alpha1 + alpha2 - C);
40. H = min(C, alpha1 + alpha2);
41. end
42.
43. if L == H
44. fprintf('L=H\n');
45. continue;
46. end
47.
48. para = K(i, i) + K(j, j) - 2 * K(i, j);
49.
50. if para <= 0
51. fprintf('parameter\leq 0\n');
52. continue;
53. end
54. % 得到新的alpha
55. alpha2New = alpha2 + y2 * (Error1 - Error2) / para;
56.
57. alpha2New = max(alpha2New, L);
58. alpha2New = min(alpha2New, H);
59.
60. if abs(alpha2New-alpha2)<=0.0001
61. %continue;
62. break
63. end
64.
65. alpha1New=alpha1+y1*y2*(alpha2-alpha2New);
66.
67. % updata bias
68. bias1=-Error1-y1*K(i,i)*(alpha1New-alpha1)-y2*K(j,i)*(alpha2New-alpha2)+bias;
69. bias2=-Error2-y1*K(i,j)*(alpha1New-alpha1)-y2*K(j,j)*(alpha2New-alpha2)+bias;
70.
71. if alpha1New>0&&alpha1New<C
72. bias=bias1;
73. elseif alpha2New>0&&alpha2New<C
74. bias=bias2;
75. else
76. bias=(bias2+bias1)/2;
77. end
78.
79. alpha(i,1)=alpha1New;
80. alpha(j,1)=alpha2New;
81. end
82. end
83.
84.
85. iteratorTimes = iteratorTimes + 1;
86.
87. fprintf('iteratorTimes=%d\n', iteratorTimes);
88. end
















 797
797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











