






1.2 可计算载体:形式化余机械化
自然语言处理在很大程度上难以精确表达数字概念,研究人员开始使用符号来表达
形式化:在给定的一组推理规则后,从已有的知识(公理,定理和命题)出发,根据推理规则,把数学概念形式化描述出来,得到众多先前未定义的知识。这样的系统称为形式化系统。如果已有的知识和推理都是正确的,则形式化系统可以源源不断得到所有可以被推导出来的知识。为了保证其的有效性,都需要以下的特性:
1、完备性:所有能够以某形式化系统推导出来的知识,都可以从这个形式化系统中推导出来
2、一致性:所有可推导出来的知识不会同时推导出来其否定的,如推导出A>=0,则不会同时推导出A<0。也就是说形式化系统是自洽的,非矛盾的。
3、可判定性:对于形式化系统推导得到的任何知识,存在算法可在有限内判定其为真或为假。
原始递归函数和λ-演算”成为人工智能的“机器载体”。
图灵机模型:是一个抽象的机械式计算装置,它两端无限长的纸带,纸带上为一个一个可擦写小方格,小方格中可以放入某个计算任务所需要的数据,程序控制器事先存储若干指令,读写控制指针从左到右,触发的对应指令去执行某一操作,并将计算结果写入纸带方格。上述步骤周而复始,直至结束,纸带所记载的信息就是计算结果。
gcd( , )函数——>求最大公约数函数
任何可计算函数均可通过三种方式完成计算:原始递归函数,“ λ-演算 ” 和图灵机
模拟人类智能:以符号主义为核心的逻辑推理,以问题求解为核心的探寻搜索,以数据驱动为核心的机器学习,以行为主义为核心的强化学习,以博弈对抗为核心的决策智能
智能计算方法
1.3.1符号主义为核心的逻辑推理
人工智能问题求解三大方法:推理,搜索,约束
推理:归纳推理,演绎推理,因果推理
1、归纳:从特殊到一般,由具体到抽象
2、演绎:从一般出发,得到具体陈述或个别结论
3、因果:引起和被引起关系
推理由易到难程度分为三个层次:
1、关联:可直接从数据中计算得到的统计相关
2、干预:无法直接从观测数据得到关系
3、反事实:某个事情已经发生了,则在相同环境中,这个事情不发生会带来怎样的新结果
1.3.2 以问题求解为核心的探寻搜索
搜索算法:无信息搜索,有信息搜索和对抗搜索
无信息搜索:利用搜索策略来扩展被搜索空间中的节点次序可分类为广度优先搜索和深度优先搜索等搜索方法
有信息搜索:利用与所求解问题相关的辅助信息,代表算法为贪婪最佳优先搜索和A*搜索
对抗搜索:又称为博弈搜索,指在一个竞争的环境中,智能体之间通过竞争实现相反的利益,一方最大化这个利益,另一方最小化这个利益,代表算法为最小最大搜索,Alpha-Beta剪枝搜索和蒙特卡洛树搜索
1.3.3 以数据驱动为核心的机器学习
机器学习:监督学习,无监督学习,半监督学习
监督学习有两个路径:
1、基于训练数据,从假设空间这一学习范围中得到一个最优映射函数f(也称为决策函数),映射函数f将数据映射到语义标注空间,实现数据的分类和识别。一个良好的监督学习算法就是使f(Xi)与yi之间的差值越小越好。一旦训练得到了映射函数f,就可以利用映射函数f来对未知数据进行识别和分类。
2、除了从训练数据中直接来学习映射函数外,也可以通过概率模型来进行识别和分类。如再判别式学习方法中,可从训练数据中学习条件概率分布P(yi | xi),进而根据这一取值来判断数据xi属于yi的概率,以实现对xi的分类和识别。或者如在生成式学习方法中,学习数据和类型标签的联合概率分布P(X,Y),再通过贝叶斯理论来求取后验概率,完成识别和分类。
赫布理论指出:神经元之间持续重复经验刺激可导致突触传递效能增加
深度学习也是一种监督学习
无监督学习:数据本身不包含标注信息
半监督学习:一部分数据有标注信息而一部分没有
监督学习算法:回归分析、提升算法,支持向量机和决策树与判别学习方法,也包括隐狄利克雷分布和隐马尔可夫链等生成式学习方法
无监督学习算法:聚类,降维和期望极大算法
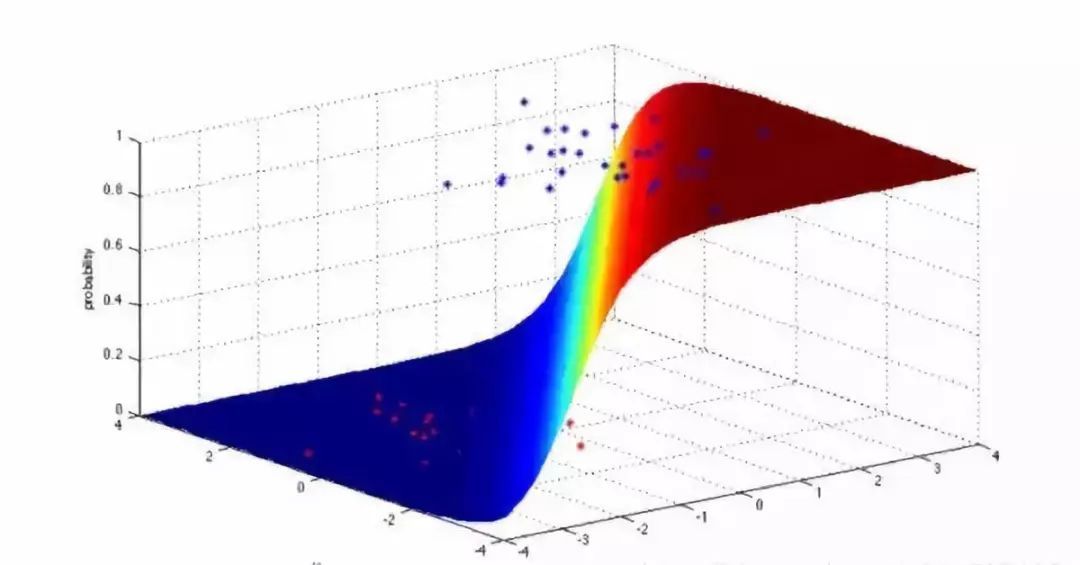
逻辑回归(Logistic Regression)
逻辑回归模型是一个二分类模型,它选取不同的特征与权重来对样本进行概率分类,用一个log函数计算样本属于某一类的概率。即一个样本会有一定的概率属于一个类,会有一定的概率属于另一类,概率大的类即为样本所属类。用于估计某种事物的可能性。
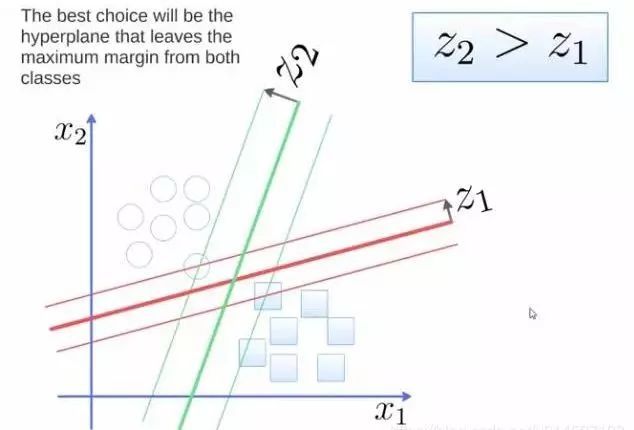
支持向量机(SVM)
支持向量机(support vector machine)是一个二分类算法,它可以在N维空间找到一个(N-1)维的超平面,这个超平面可以将这些点分为两类。也就是说,平面内如果存在线性可分的两类点,SVM可以找到一条最优的直线将这些点分开。SVM应用范围很广。

要将两类分开,想要得到一个超平面,最优的超平面是到两类的margin达到最大,margin就是超平面与离它最近一点的距离,如下图,Z2>Z1,所以绿色的超平面比较好。
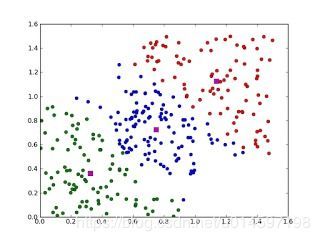
1、聚类算法
聚类算法就是将一堆数据进行处理,根据它们的相似性对数据进行聚类。
聚类,就像回归一样,有时候人们描述的是一类问题,有时候描述的是一类算法。聚类算法通常按照中心点或者分层的方式对输入数据进行归并。所以的聚类算法都试图找到数据的内在结构,以便按照最大的共同点将数据进行归类。常见的聚类算法包括 k-Means算法以及期望最大化算法(Expectation Maximization, EM)。
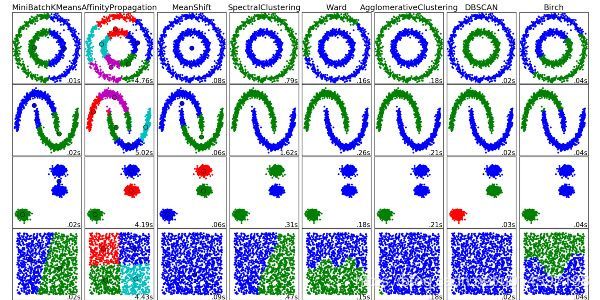
聚类算法有很多种,具体如下:中心聚类、关联聚类、密度聚类、概率聚类、降维、神经网络/深度学习。
1.3.4 以行为为核心的强化学习
强化学习:根据环境所提供的奖励反馈或者惩罚反馈来学习所处状态可施加的最佳行动(如碰墙后折返),通过运用 “尝试-试错”与平衡“探索(未知空间)与利用(已有经验)”等机制不断进步,改进行动策略。强化学习就是这样一种赋予智能体自监督学习能力,使其能够自主与环境交互,做出序列决策,完成序列化形式的任务,向“学会学习”这一能力塑造目标而努力。
简单来说,强化学习就是不断与环境交互,利用环境给出的奖惩不断地改进决策。
| 监督学习 | 无监督学习 | 强化学习 | |
|---|---|---|---|
| 学习依据 | 基于监督信息 | 基于对数据结果的阶段 | 基于评价 |
| 数据来源 | 一次性给定 (含标注信息) | 一次性给定 (无标注信息) | 在序列交互中产生,且只有在一个序列中结束后才会反馈明确奖惩值 |
| 决策过程 | 根据标注信息做出单步静态决策 | 无 | 根据环境给出的滞后回报做出序列决策 |
| 学习目标 | 样本空间到高级语义空间的映射 | 同一类数据的分布模式 | 选择能够获取最大收益的状态到动作的映射 |
1.3.5 以博弈对抗为核心的决策智能
博弈行为是多个带有相互竞争性质的主体,为了达到各自目标和利益,采用的带有对抗性质的行为,即“两害相权取其轻,两利相权取其重”。现在的博弈主要研究博弈行为中的最优的对抗策略及其稳定局势。推动机器学习从“数据拟合”过程中以“求取最优解”为核心向博弈对抗过程中“求取均衡解”为核心的转变。
小结
在解决现实生活中的实际问题中,一般是多种机器学习算法融汇使用,如AlphaGo就是通过深度学习来构造黑白相间棋盘的特征表达,通过强化学习来进行自我博弈以提高智能体学习能力,通过蒙特卡洛树搜索来寻找较佳落子。
第二章 逻辑与推理
2.1 命题逻辑
为了表达概念,但自然语言不能够准确的叙述,因此引入一种目标语言,这个目标语言由表达判断的一些语言汇集而成,它和一些公式符号相结合,就形成数理逻辑的形式符号体系。命题逻辑是数理逻辑的基础。
命题:命题是一个能确定为真或为假的陈述句
原子命题:原子命题指不包含其他命题作为其组成部分的命题,又称简单命题
复合命题:复合命题指包含其他命题作为其组成作为其组成部分的命题。
| 命题联结词 | 表示形式 | 意义 |
| 与 | p∧q | 命题合取,即“ p且q ” |
| 或 | pνq | 命题析取,即“ p或q ” |
| 非 | ┐p | 命题否定,即“非p” |
| 条件 | p—>q | 命题蕴含,p称为前件,q称为后件,即“ 如果p,则q ” |
| 双向条件 | p<—>q | 命题双向蕴含,即“ p当且仅当q ” |
















 8707
8707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









