







/1 前言/
想要电脑换个壁纸时都特别苦恼,因为百度搜到那些壁纸也就是分辨率达到了壁纸的水准。可是里面图片的质量嘛,实在是不忍直视…。而有些4K高清的壁纸大多是有版权的 ,这就使我们想要获取高清的图片,变得非常的困难。
wallhaven 网站是无版权的4K壁纸 ,而且主题丰富(创意、摄影、人物、动漫、绘画、视觉),今天教大家如何去批量的去下载wallhaven4K原图。
/2 项目目标/
获取对应的4K壁纸,并批量下载保存在文件夹。
/3 涉及的库和网站/
软件:PyCharm
需要用到的库:requests、lxml、fake_useragent、time
先列出网址,如下所示:
https://wallhaven.cc/search?q=id%3A65348&page={}网址city=%E5%B9%BF%E5%B7%9E指的是广州这个城市、pn指的是页数。
/4 项目分析/
滑动鼠标观察下一页的网址的变化:
https://wallhaven.cc/search?q=id%3A65348&page=1https://wallhaven.cc/search?q=id%3A65348&page=2https://wallhaven.cc/search?q=id%3A65348&page=3
滑动下一页时,每增加一页page自增加1,用{}代替变换的变量,再用for循环遍历这网址,实现多个网址请求。
/5 具体实现/
1、定义一个class类继承object,定义init方法继承self,主函数main继承self。导入需要的库和网址。
import requestsfrom lxml import etreefrom fake_useragent import UserAgentimport timeclass wallhaven(object):def __init__(self):self.url = "https://wallhaven.cc/search?q=id%3A65348&page={}"def main(self):passif __name__ == '__main__':imageSpider = wallhaven()imageSpider.main()
2、fake_useragent模块实现随机产生UserAgent。
ua = UserAgent(verify_ssl=False)for i in range(1, 50):self.headers = {'User-Agent': ua.random,}
3、for循环实现多网址访问。
startPage = int(input("起始页:"))endPage = int(input("终止页:"))for page in range(startPage, endPage + 1):url = self.url.format(page)
4、发送请求 获取响应。
'''发送请求 获取响应'''def get_page(self, url):res = requests.get(url=url, headers=self.headers)html = res.content.decode("utf-8")return html
5、解析一级页面,得到二级页面的 href 地址。
def parse_page(self, html):parse_html = etree.HTML(html)image_src_list = parse_html.xpath('//figure//a/@href')
6、遍历二级页面网址,发生请求、解析数据。找到相对于的图片地址。
html1 = self.get_page(i) # 二级页面发生请求parse_html1 = etree.HTML(html1)# print(parse_html1)filename = parse_html1.xpath('//div[@class="scrollbox"]//img/@src')# print(filename)
7、获取到的图片地址,发生请求,保存。
# 图片地址发生请求for img in filename:dirname = "./图/" + img[32:] '''可修改图片保存的地址'''print(dirname)html2 = requests.get(url=img, headers=self.headers).contentwith open(dirname, 'wb') as f:f.write(html2)print("%s下载成功" % filename)
8、调用方法,实现功能。
html = self.get_page(url)self.parse_page(html)
优化:设置延时。(防止ip被封)。
time.sleep(1.4) """时间延时"""/6 效果展示/
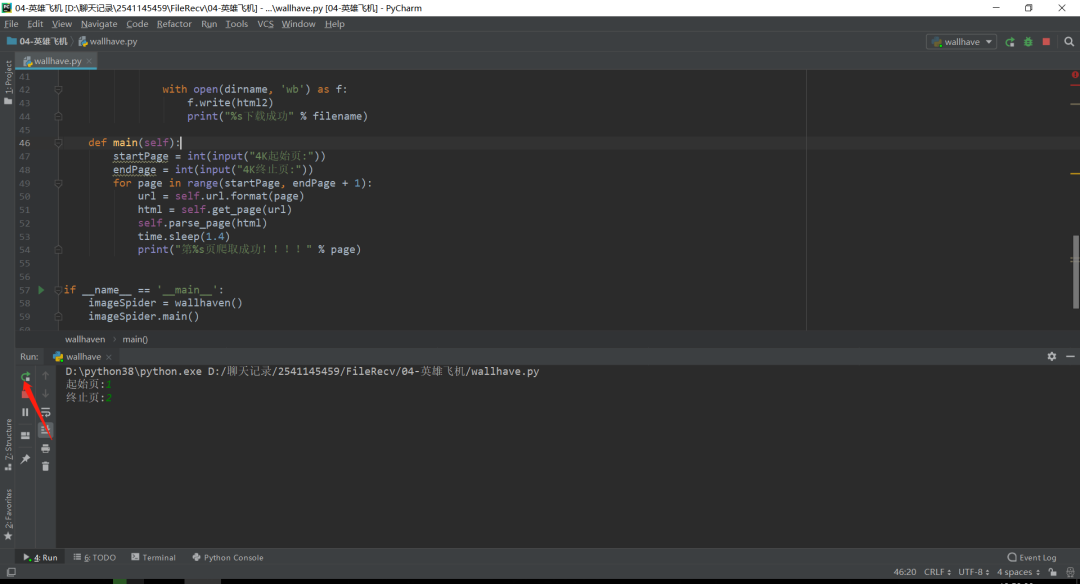
1、点击绿色按钮运行,将结果显示在控制台,如下图所示。输起始页和终止页,回车。
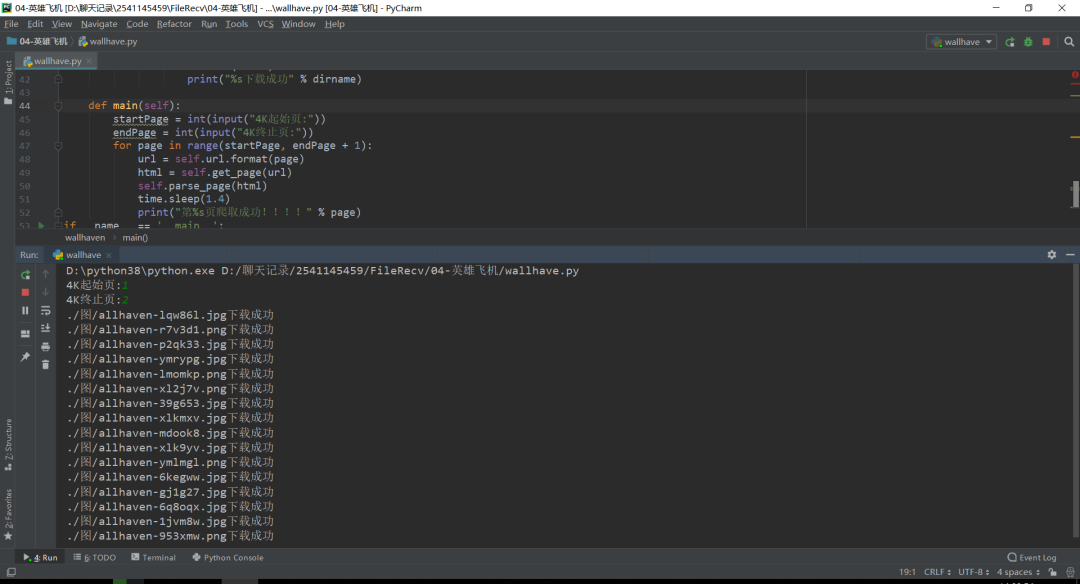
2、图片下载成功控制台输出。
3、批量保存。
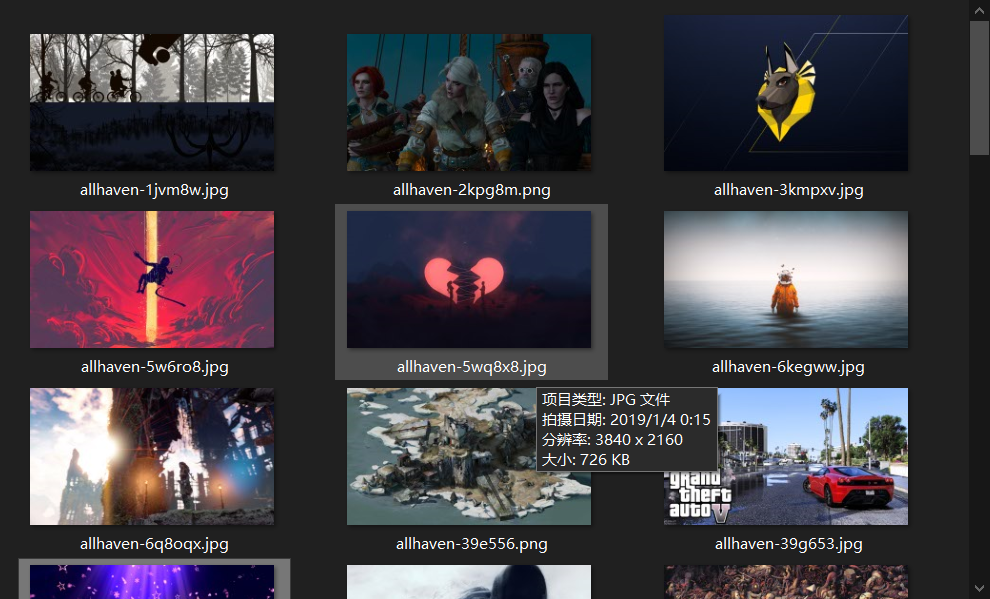
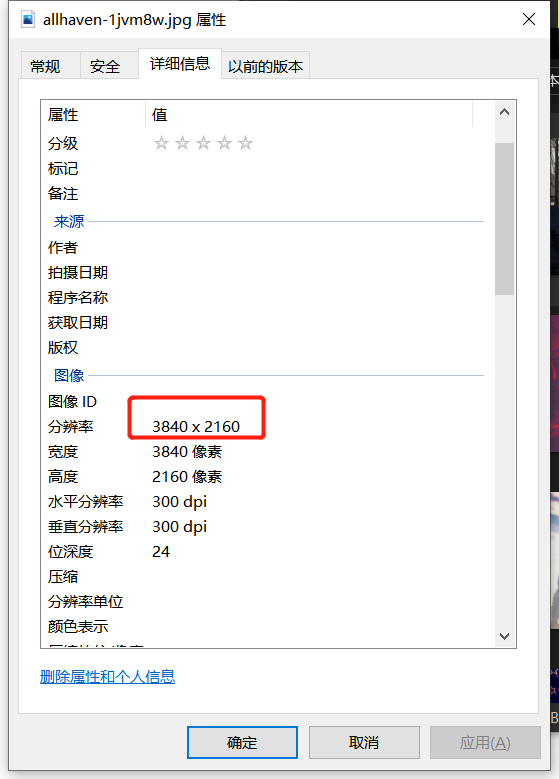
4、验证4K。(点击图片打开属性)
/7 小结/
1、不建议抓取太多数据,容易对服务器造成负载,浅尝辄止即可。
2、本文基于Python网络爬虫,利用爬虫库,获取wallhaven4K壁纸。
3、4K的壁纸下载时可能会有点缓慢,请大家耐心的等待。如果图片的地址不一样,需要自己修改一下图片的保存的地址。
4、大家也可以在wallhaven网址上,寻找自己喜欢图片,按照操作步骤,自己尝试去做。自己实现的时候,总会有各种各样的问题,切勿眼高手低,勤动手,才可以理解的更加深刻。

















 2896
2896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











