






 本文介绍了使用Python(pandas和numpy)对口袋妖怪数据进行处理的实验,包括数据导入、去重、基本信息分析、类型分布、数值排序、数据划分、总和验证以及Series的构造。
本文介绍了使用Python(pandas和numpy)对口袋妖怪数据进行处理的实验,包括数据导入、去重、基本信息分析、类型分布、数值排序、数据划分、总和验证以及Series的构造。
一 、 实验题目
实验四: 口袋妖怪数据处理
二 、 实验目的和要求
实验四:
1 、 目的: 掌握爬虫基础语法
2 、要求: 掌握pandas,numpy数据处理的方法
三 、 实验内容
- 代码
# 首先要导入对应的模块
import pandas as pd
import numpy as np
df = pd.read_csv('data/pokemon.csv')
df.head()
# In[2]:
# df.shape
# 2.对于#重复的妖怪只保留第一条记录,解决以下问题:
# df_unique = df.drop_duplicates('#')
# In[3]:
# 1.查看基本数据信息,数据样本数量、每一列数据类型、是否有缺失数据
print(df.info())
x=pd.isnull(df).any()
print(x)
# 计算出每个特征有多少百分比是缺失的
percent_missing = df.isnull().sum() * 100 / len(df)
missing_value_df = pd.DataFrame({
# 'column_name': df.columns,
'percent_missing': percent_missing
})
missing_value_df.sort_values(by='percent_missing', ascending=False).head(10)
print(missing_value_df)
# 2.计算所有宝可梦宝贝的平均HP值
avg=df['HP'].mean()
print("平均值:",avg)
# 3.数据集合中Type 1属性有哪些属性
print(df['Type 1'].value_counts())
# 4.将数据按照Attack列值进行排序(降序)
m=df.sort_values(by=["Attack"])
print(m)
# <div class="alert alert-info alert-dismissible">听了上述的讲解后,在巩固一下吧,练一练 <span class="label label-warning">时间20分钟</span>
# </div>
# Q1.将数据按照Total列的值进行划分,划分成三个部分,并统计每一部分的样本数量
a=df[df.Total<=300]
len1=len(a.index)
b=df[(300<df.Total )&(df.Total<=500)]
len2=len(b.index)
c=df[df.Total>500]
len3=len(c.index)
print(a)
print("a区域样本数量为:",len1)
print(b)
print("b区域样本数量为:",len2)
print(c)
print("c区域样本数量为:",len3)
# Q2.对`HP, Attack, Defense, Sp. Atk, Sp. Def, Speed`进行加总,验证是否为`Total`值。
df_demo = df[['HP','Attack','Defense','Sp. Atk','Sp. Def','Speed']]
var = df_demo.sum(axis=1) == df['Total']
print(var)
# 【拓展】Q3.构造Series,取出物攻,超过120的替换为`high`,不足50的替换为`low`,否则设为`mid`
attck=df['Attack'].mask(df['Attack']>120,'high').mask(df['Attack']<50,'low').mask((df['Attack']<=120)&(df['Attack']>=50),'mid')
print(attck)
- 运行结果截图:

图 1基本数据信息
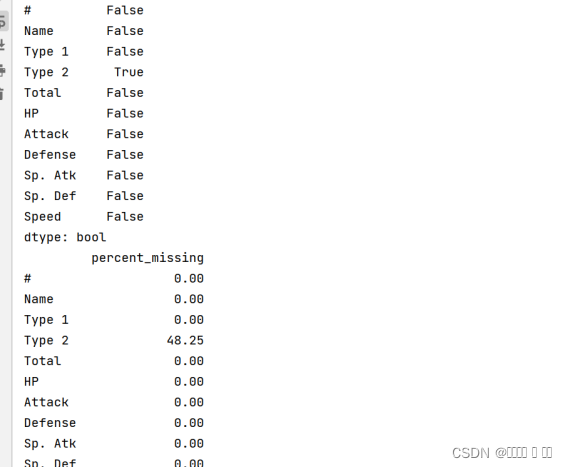
图 2类型缺失及占比
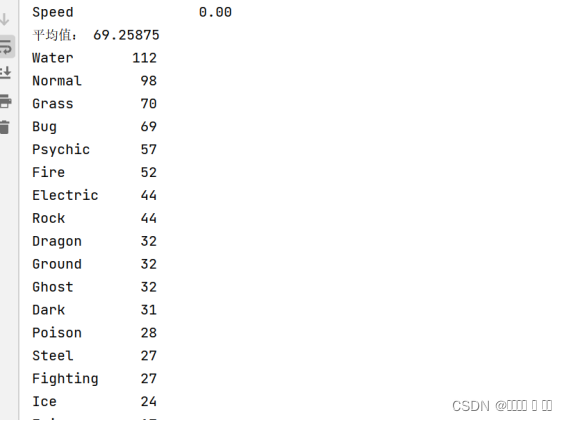
图 3 PH平均值及type1中属性
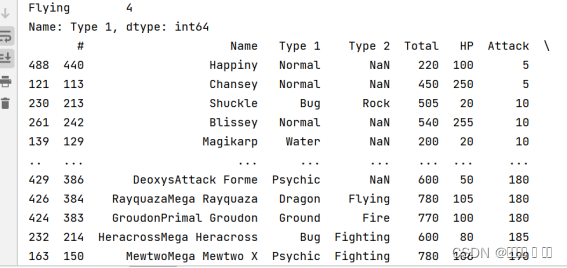
图 4 attack排序
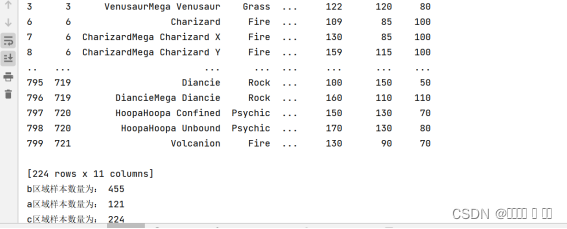
图 5 分类及样本数量
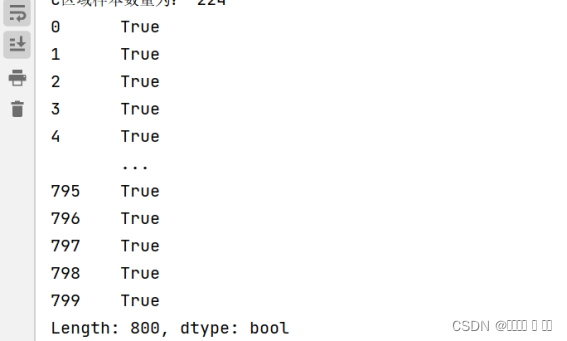
图 6 total验证
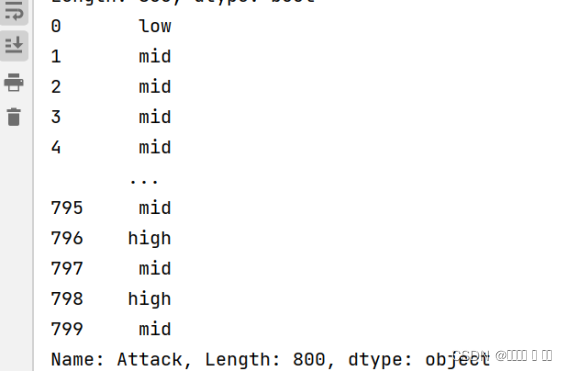
图 7构造Series
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











