






EelasticSearch是什么?
1.概述
Elasticsearch 是一个基于 Apache Lucene 构建的开源分布式搜索引擎和分析引擎。它专为云计算环境设计,提供了一个分布式的、高可用的实时分析和搜索平台。Elasticsearch 可以处理大量数据,并且具备横向扩展能力,能够通过增加更多的硬件资源来应对数据和查询量的增长。
Elasticsearch 的核心特点包括:
-
全文搜索:支持对各种类型的数据(包括结构化、半结构化和非结构化文本数据)进行快速高效的全文本搜索。
-
分布式:数据在集群中的多个节点间分布和复制,确保高可用性和容错性,同时也支持水平扩展,以应对更大的数据量和更高的并发访问。
-
实时性:数据一旦写入 Elasticsearch,几乎可以立即被搜索到,提供近乎实时的搜索体验。
-
分析能力:内置丰富的数据分析工具,包括聚合分析(Aggregations)和其他统计功能,便于用户对数据进行深入挖掘和洞察。
-
多租户:支持索引级别的隔离,每个索引可以配置分片数量和副本数量,以满足不同业务场景的需求。
-
RESTful API:通过 HTTP/HTTPS 协议提供 JSON 格式的 REST API 接口,易于与其他系统集成,支持多种开发语言调用。
-
灵活的文档模型:无需预定义严格的表结构,而是采用动态 schema 或映射,可以根据文档内容自动识别数据类型和结构。
Elasticsearch 被广泛应用在日志分析、监测数据、企业搜索、电子商务搜索、实时分析等多个领域,并常与 Logstash(日志收集和处理工具)、Kibana(数据可视化平台)共同构成 Elastic Stack(原 ELK Stack),形成一套完整的日志管理和数据分析解决方案。
2.什么场景会用到Elasticsearch
-
全文搜索:
-
电商搜索:快速查找商品信息,支持模糊匹配、关键词高亮显示、过滤、排序等功能。
-
站内搜索:网站内部的页面、文章、博客等内容的搜索,提供类似Google的搜索体验。
-
文档管理系统:企业级文档搜索,如办公文档、合同、法律文件等的高效检索。
-
论坛和社交媒体:用户发表的内容搜索,如帖子、评论、话题等。
-
日志分析与监控:
-
服务器日志:收集、索引和分析服务器产生的各类日志,用于故障排查、性能优化、安全审计等。
-
应用日志:跟踪应用程序的行为,帮助开发人员迅速定位错误、诊断问题。
-
运维监控:收集系统指标、网络流量数据,实时或历史数据分析,可视化展示系统状态和趋势。
-
数据分析:
-
业务分析:实时或批量分析业务数据,生成报表,进行趋势分析、关联分析等。
-
时序数据分析:存储和分析时间序列数据,例如设备传感器数据、用户行为数据等。
-
NoSQL JSON文档数据库:
-
作为JSON文档数据库使用,存储和检索半结构化数据,支持地理位置查询和混合查询。
-
搜索推荐:
-
实现个性化搜索和推荐功能,根据用户的搜索历史和行为模式,智能推荐相关内容。
-
地理信息系统:
-
存储和查询带有地理位置信息的数据,构建地图应用、位置服务等相关功能。
-
大规模监控系统:
-
结合Logstash和Kibana,搭建ELK Stack,进行大规模分布式环境下的日志集中管理、实时分析和可视化展示。
总之,Elasticsearch 适合那些需要对大量数据进行快速检索、实时分析和可视化展现的应用场景,特别是在处理非结构化或半结构化数据方面表现尤为出色。随着功能的不断丰富和完善,Elasticsearch 已经成为现代数据驱动型企业不可或缺的基础架构组件之一。
EelasticSearch安装
1.Docker安装
docker run -d --name es7 -e ES_JAVA_POTS="-Xms256m -Xmx256m" -e "discovery.type=single-node" -v /opt/es7/data/:/usr/share/elasticsearch/data -p 9200:9200 -p 9300:9300 elasticsearch:7.14.02.客户端UI工具,Edge浏览器扩展
3.分词器安装
3.1为什么要安装分词器?
在 Elasticsearch 的 IK Analyzer 中,ik_smart和 ik_max_word 是IK 分词器针对中文分词提供的两种策略,但分词效果和粒度不同:
ik_smart: 这种模式更侧重于保持语义完整性,尽量进行较少的、更有意义的拆分,减少无意义的子词组合,提高搜索准确率,降低误报率。
示例:“中华人民共和国人民大会堂” 分词结果(ik_smart)可能只有:“中华人民共和国”、“人民大会堂”等较完整、更具实际意义的词语组合。
ik_max_word: 此模式致力于最大化地拆分文本,即尽可能多地生成可能的词语组合,包括单字、双字直至整个短语。它的特点是尽力穷举所有可能的词汇,提高召回率,但在某些情况下可能会造成噪声较多。
示例:“中华人民共和国人民大会堂” 分词结果(ik_max_word)可能包括:中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等。
简单来说,
ik_max_word更倾向于全面细致的分词,而ik_smart则偏向于精简和精准的分词。在实际应用场景中,选择哪种模式取决于项目的具体需求,如是否需要扩大搜索覆盖面还是提高搜索准确性。
3.2安装
参考网址:https://blog.51cto.com/u_15116285/6100979
官方插件下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases
#第一步 copy 插件到容器
docker cp /opt/es7/elasticsearch-analysis-ik-7.14.0.zip 容器id:/usr/share/elasticsearch
#第二步进入你的容器
docker exec -it 容器id /bin/bash
若没有权限执行以下语句
chomd 777 ./data
#第三步执行如下命令,安装插件,中间会提示 Y or N,直接写 Y ,回车即可
elasticsearch-plugin install file:\/usr/share/elasticsearch/elasticsearch-analysis-ik-7.14.0.zip
#第四步退出容器
exit
#第五步重启容器
docker restart 容器ID
4.使用客户端查看


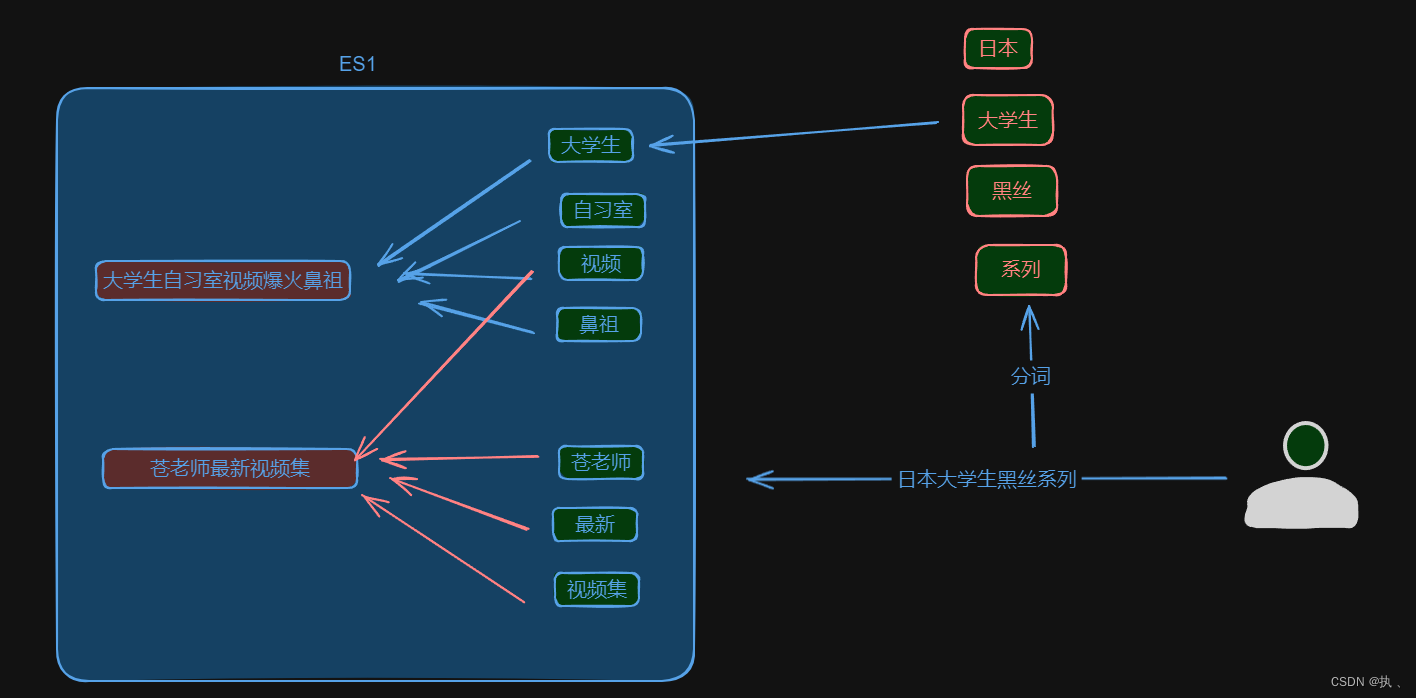
| post _analyze { "analyzer": "ik_smart", "text": "大学生自习室视频爆火鼻祖" } | post _analyze { "analyzer": "ik_max_word", "text": "大学生自习室视频爆火鼻祖" } |
5.原理
EelasticSearch使用
1. Easy-ES介绍
2. 导入依赖包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</exclusion>
<exclusion>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>cn.easy-es</groupId>
<artifactId>easy-es-boot-starter</artifactId>
<version>2.0.0-beta1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.14.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.14.0</version>
</dependency>
3. 在对像属性上添加注解
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Data
@IndexName( aliasName = "es_product")
public class EsProduct {
//将id设置为自定义的类型
@IndexId(type = IdType.CUSTOMIZE)
private Integer id;
@IndexField( fieldType= FieldType.TEXT,analyzer = Analyzer.IK_MAX_WORD,searchAnalyzer = Analyzer.IK_SMART)
private String name;
@IndexField( fieldType= FieldType.INTEGER)
private Integer categoryId;
@IndexField(fieldType= FieldType.DOUBLE)
private BigDecimal price;
@IndexField(fieldType = FieldType.TEXT,analyzer = Analyzer.IK_SMART)
private String brief;
@IndexField(fieldType = FieldType.KEYWORD)
private String img;
@IndexField(fieldType = FieldType.TEXT,analyzer = Analyzer.IK_MAX_WORD)
private List<String> tags;
@IndexField(fieldType = FieldType.INTEGER)
private Integer highOpinion;
@IndexField(fieldType = FieldType.INTEGER)
private Integer salesVolume;
@IndexField(fieldType = FieldType.DATE)
private LocalDateTime productionDate;
}4.新建Mapper类,类似Mybatis的dao
public interface EsProductMapper extends BaseEsMapper<EsProduct> {
}5.配置ES
# Easy-Es配置部分
easy-es:
# 启用Easy-Es功能
enable: true
# 设置Elasticsearch服务器地址和端口
address: 192.168.23.27:9200
# 全局配置项,设置是否打印执行的DSL语句(便于调试)
global-config:
print-dsl: true
Elasticsearch DSL (Domain Specific Language) 是一种专门设计用来与Elasticsearch搜索引擎进行交互的查询语言。它是一种基于JSON格式的查询语法,允许用户以结构化的方式来构建复杂的查询、过滤条件、聚合操作以及其他高级功能。
通过Elasticsearch DSL,开发人员可以灵活且高效地执行各种查询操作,包括全文本搜索、精确匹配、范围查询、布尔组合查询、排序、分页、高亮显示文本、统计计算、地理位置查询以及复杂的聚合分析等。
6. 创建、删除、查询索引
select8中match的用法
package com.by;
import cn.easyes.core.biz.EsPageInfo;
import cn.easyes.core.conditions.select.LambdaEsQueryWrapper;
import cn.hutool.core.collection.CollUtil;
import com.by.dao.EsProductMapper;
import com.by.model.EsProduct;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.index.query.Operator;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.math.BigDecimal;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
@SpringBootTest
@Slf4j
class AppTests {
@Autowired
EsProductMapper esProductMapper;
//创建索引
// @Test //当执行时,他会默认创建,执行时会报reason=index [esproduct/EBTP12JoTEGAAoZsQkmJvA] already exists异常,此时已经创建
void testCreateIndex() {
Boolean b = esProductMapper.createIndex();
Assertions.assertTrue(b);
}
@Test
//插入一个
void insert(){
//id我们定义的为Integer,而系统会为我们随机生成一个String类型的id以确保其唯一性,
// 此时我们需要再model中使用@IndexId(type = IdType.CUSTOMIZE)
EsProduct product = EsProduct.builder()
.id(1)
.brief("小米销量遥遥领先")
.categoryId(1)
.img("图片")
.highOpinion(99)//好评
.name("小米手机")
.price(new BigDecimal(99))
.productionDate(LocalDateTime.now())
.salesVolume(200)
.tags(CollUtil.newArrayList("为发烧而生"))
.build();
esProductMapper.insert(product);
}
@Test
//批量插入
void insert2(){
delete();
List<EsProduct> esProductList =new ArrayList<>();
for (int i = 1; i <= 10; i++) {
EsProduct esProduct = EsProduct.builder()
.id(i)
.name("小米"+i)
.img("图片地址"+i)
.brief("小米(MI)Redmi Note"+i+" 5G 120Hz OLED屏幕 骁龙4移动平台 5000mAh长续航 8GB+128GB子夜黑 小米红米")
.price(new BigDecimal(500.36+i))
.categoryId(1)
.highOpinion(100+i)
.productionDate(LocalDateTime.now())
.salesVolume(200+i)
.tags(CollUtil.newArrayList("12"+i+"高刷","舒适护眼"))
.build();
esProductList.add(esProduct);
}
Integer batch = esProductMapper.insertBatch(esProductList);
}
@Test
//批量删除
void delete(){
ArrayList<Integer> list = CollUtil.newArrayList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer integer = esProductMapper.deleteBatchIds(list);
}
@Test
void delete2(){
LambdaEsQueryWrapper<EsProduct> esQueryWrapper = new LambdaEsQueryWrapper<>();
LambdaEsQueryWrapper<EsProduct> wrapper = esQueryWrapper.eq(EsProduct::getId, 1);
Integer delete = esProductMapper.delete(wrapper);
}
@Test
void update(){
LambdaEsQueryWrapper<EsProduct> esQueryWrapper = new LambdaEsQueryWrapper<>();
LambdaEsQueryWrapper<EsProduct> wrapper = esQueryWrapper.like("name", "小");
EsProduct product = EsProduct.builder().brief("小米为发烧而生").tags(CollUtil.newArrayList("雷总说少妇勾魂,少女勾人")).build();
Integer update = esProductMapper.update(product, wrapper);
}
@Test
void update2(){
EsProduct product = EsProduct.builder().id(2).name("小米su7").brief("风一样的男人").build();
Integer update = esProductMapper.updateById(product);
}
@Test
void update3(){
ArrayList<EsProduct> list = CollUtil.newArrayList();
for (int i = 2; i < 5; i++) {
EsProduct product = EsProduct.builder().id(i).name("新能源汽车").brief("风一样的男人").price(new BigDecimal(7888)).build();
list.add(product);
}
Integer integer = esProductMapper.updateBatchByIds(list);
}
@Test
void select(){
EsProduct esProduct = esProductMapper.selectById(2);
}
@Test
void select2(){
List<EsProduct> esProductList = esProductMapper.selectBatchIds(CollUtil.newArrayList(2, 3, 4, 5));
}
@Test
void select3(){
LambdaEsQueryWrapper<EsProduct> queryWrapper = new LambdaEsQueryWrapper<>();
queryWrapper.like("name","米");
List<EsProduct> esProducts = esProductMapper.selectList(queryWrapper);
}
@Test
void select4(){
LambdaEsQueryWrapper<EsProduct> queryWrapper = new LambdaEsQueryWrapper<>();
queryWrapper.eq("category",1);
List<EsProduct> esProducts = esProductMapper.selectList(queryWrapper);
}
@Test
void select5(){
LambdaEsQueryWrapper<EsProduct> queryWrapper = new LambdaEsQueryWrapper<>();
queryWrapper.in("id",4,5,6);
List<EsProduct> esProducts = esProductMapper.selectList(queryWrapper);
}
@Test
void select6(){
LambdaEsQueryWrapper<EsProduct> queryWrapper = new LambdaEsQueryWrapper<>();
// queryWrapper.queryStringQuery("汽车之家");
queryWrapper.queryStringQuery("汽车之家",1.0f);
List<EsProduct> esProducts = esProductMapper.selectList(queryWrapper);
}
@Test
void select7(){
LambdaEsQueryWrapper<EsProduct> queryWrapper = new LambdaEsQueryWrapper<>();
// queryWrapper.queryStringQuery("汽车之家");
queryWrapper.match(EsProduct::getName,"汽车",1.0f)
.or()//拼接或者的意思
.match(EsProduct::getBrief,"小米",2.0f);
List<EsProduct> esProducts = esProductMapper.selectList(queryWrapper);
}
@Test
void select8(){
LambdaEsQueryWrapper<EsProduct> queryWrapper = new LambdaEsQueryWrapper<>();
// queryWrapper.multiMatchQuery("汽车", Operator.AND,EsProduct::getName,EsProduct::getBrief);
// String name = "";
// queryWrapper.multiMatchQuery(name==null,"小米",EsProduct::getName);
queryWrapper.and(w->w.match(EsProduct::getName,"小米",1.0f)
.or()
.match(EsProduct::getBrief,"汽车",2.0f)
.or().match(EsProduct::getTags,"发烧",3.0f));
queryWrapper.orderByDesc(EsProduct::getSalesVolume);
List<EsProduct> esProducts = esProductMapper.selectList(queryWrapper);
EsPageInfo<EsProduct> pageQuery = esProductMapper.pageQuery(queryWrapper, 2, 3);
}
@Test
void select9(){
LambdaEsQueryWrapper<EsProduct> queryWrapper = new LambdaEsQueryWrapper<>();
queryWrapper.match(EsProduct::getName,"水汽车门");
List<EsProduct> esProductList = esProductMapper.selectList(queryWrapper);
}
}
7. 原生Api调用
7.1查看索引mapping关系
GET /es_product/_mapping
7.2查看某个文档,具体字段的分词
GET /product/_doc/2/_termvectors?fields=brief















 347
347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









