







1. 并查集引入
并查集是一种通过并查集算法维护的树形结构,作用:
- 判断两个节点是否有公共根节点(是否属于同一集合)
- 合并两个符合规则的分支
- 等等(图连通性、元素分组)
- 一开始各自根节点是自己:
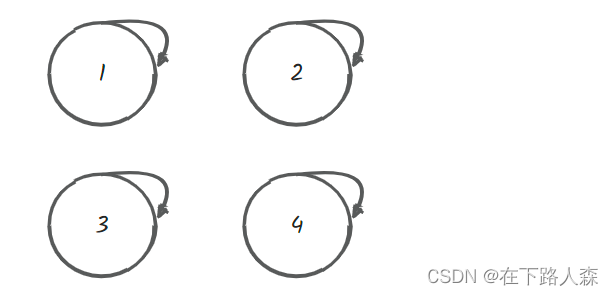
- [1,2]满足条件,合并
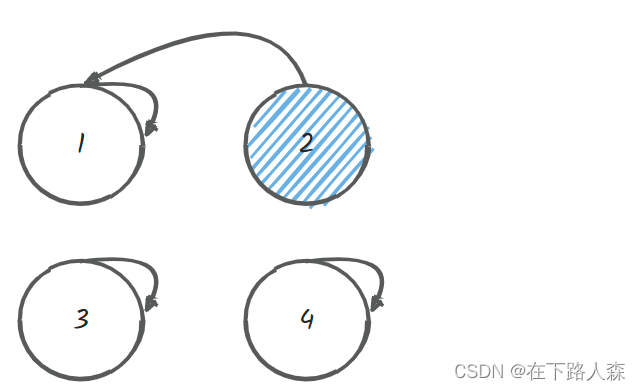
- [3,4]满足条件、合并
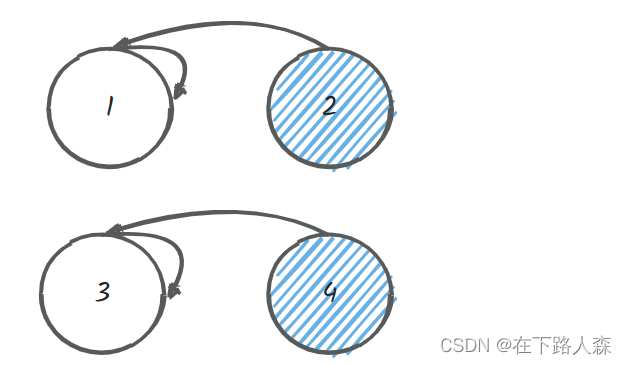
- [2,3]满足条件,合并
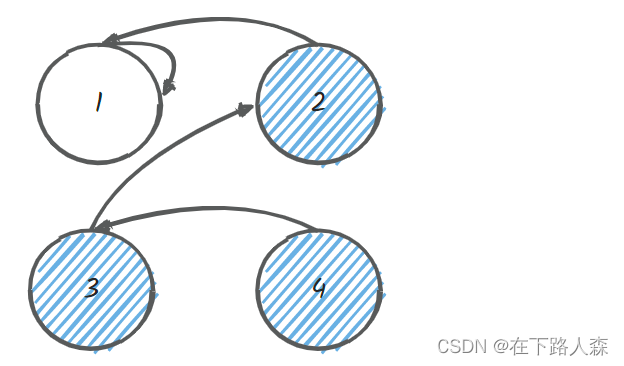
- 最后,
[1,2,3,4]通过合并算法连接到了一起 - 若要判断两节点是否是同一集合只需遍历到其根节点,判断根节点是否相同即可
算法核心:查找(查找同一根节点)、合并(将两个分支合并为一个)
查找算法:查找根结点
node数组存储对应下标元素的前一个节点,如上面图解中,我们将节点之间关系转化成数组之间的联系:node[1]=1;node[2]=1;node[3]=2;node[4]=3;
- 代码:
int find(int x){//传入待查找x //若x节点的根节点不是自己则继续往上查找,直到找到根节点 if(node[x]!=x)x=find(x); return x;//返回x的根节点 } - 执行图解:
- 首先,经过初始化后node数组对应存储元素为[1,1,2,3]:(第一个下标0忽略)
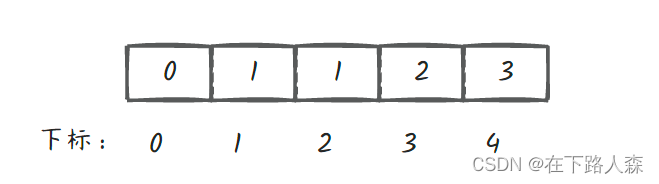
- 如:x=3:
node[3]=2,表示下标3前一个是下标2,node[2]=1,下标2前一个是下标1,node[1]=1,1的根节点是自己,则1是根节点,返回1。
- 可以看出,以这种存储有很大的不好(当所有节点成一条链时),后面有优化
- 首先,经过初始化后node数组对应存储元素为[1,1,2,3]:(第一个下标0忽略)
合并算法:通过两个节点能合并两个分支
- 代码:
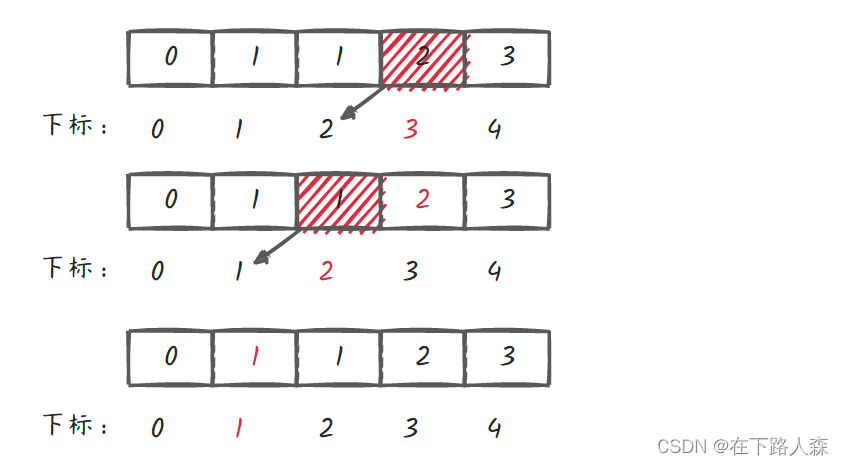
void union(int x,int y){//待合并分支的某两个节点x,y int root1=find(x);//x的根节点 int root2=find(y);//y的根节点 //如果x的根节点和y的不相同,那么把y节点的根节点接到x上(root2下标的前一个下标为root1) if(root1!=root2)node[root2]=root1; } - 图解:如果我们手里有两条链,如何进行合并呢?:
- 转化成数组node:
[1,1,3,3];
- 执行图解:
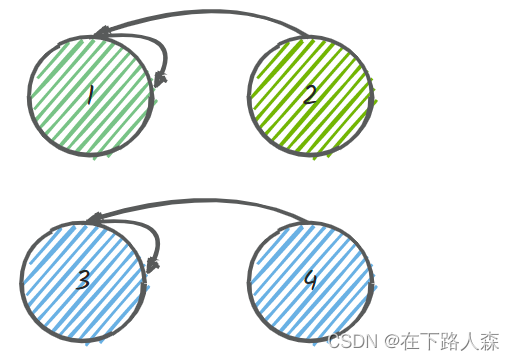
x=2,y=4
先找到y=4的的根节点3(蓝色部分),x=2的的根节点1(绿色部分);若不相同则将根节点3的前一个换成根节点1:node[3]=1
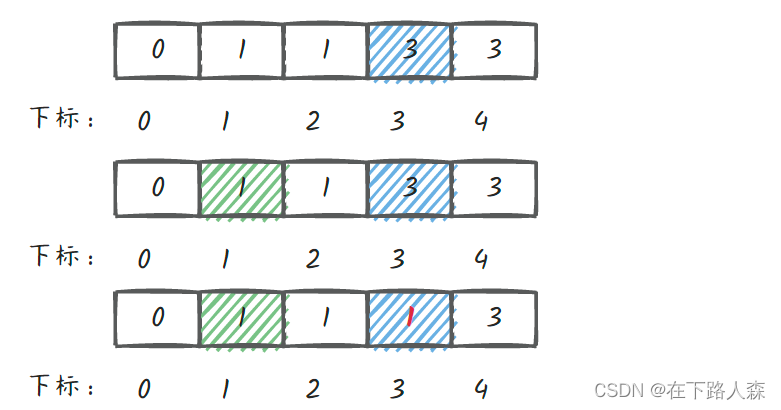
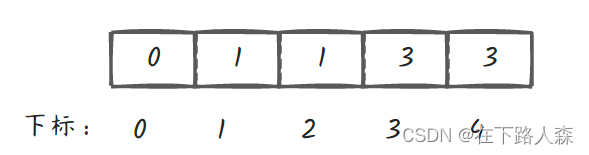
- 这样就形成了:
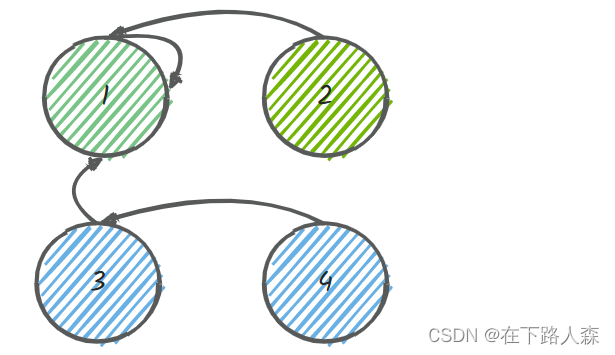
- 转化成数组node:
2. 举例分析
亲戚问题:让互无联系的两个人,知道出自同一族群
x是y的亲戚,z是y的亲戚,同时x也是z的亲戚
问题: 现有几个族群,[3,2,1,4,5,9,6,7,8];我们规定若满足arr[i]-arr[j]=1, i,j>0,则arr[i]和arr[j]是亲戚关系;6和3是亲戚嘛?
分析
- 首先自身族群内部的联系(初始化)
- 遍历所有节点,若有满足
arr[i]-arr[j]=1, i,j>0则开始合并 - 判断6和3是否是亲戚
具体实现
题目:存在arr[i]-arr[j]=1, i,j>0则合并,初始先建立一个map表,存储自己的值和下标,后续遍历i合并时,只需进行:map.contains(arr[i]-1);map.contains(arr[i]+1);即可知道是否有亲戚存在。有则进行合并.
- 一开始
[3,2,1,4,5]五个人互无联系,自己是自己的前一个:node数组:[3,2,1,4,5](不赘述[6,7,8,9])
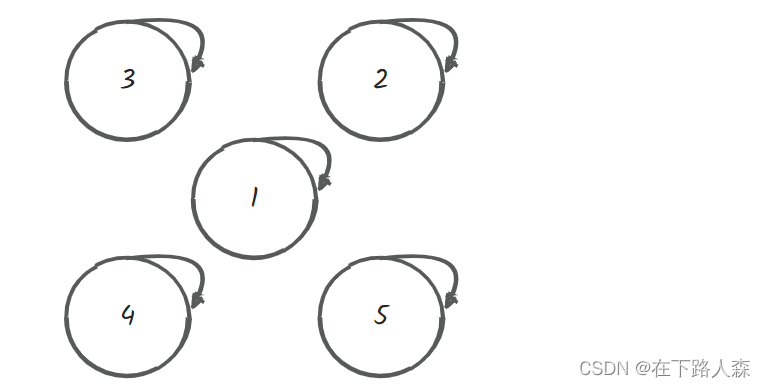
- 遍历所有节点:
3:arr[3]-arr[2]=1;合并3和22:arr[2]-arr[1]=1;合并2和11:不操作4:arr[4]-arr[3]=1;合并4和15:arr[5]-arr[4]=1;合并5和1
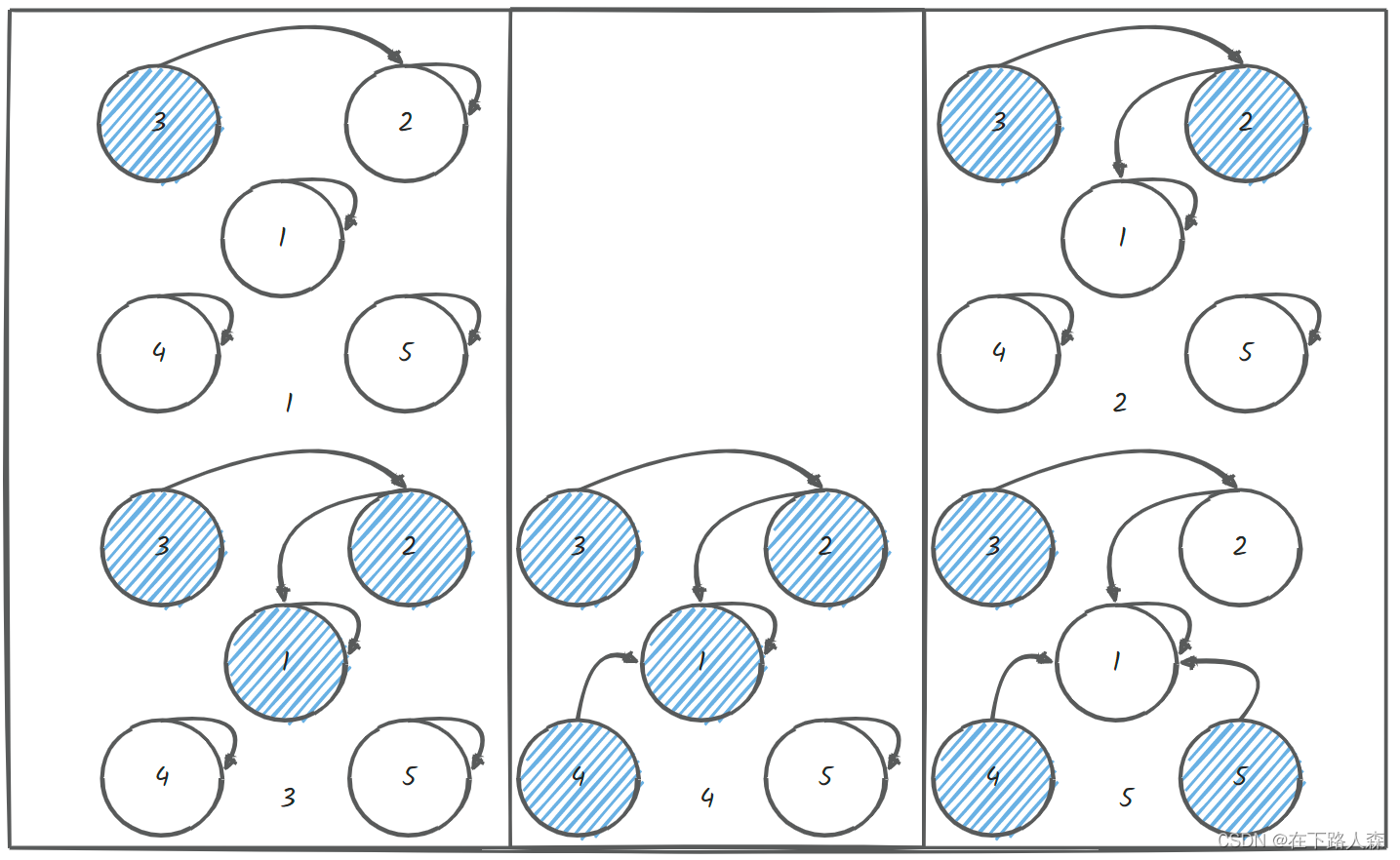
- 现只需判断
find(6)==find(3)即可知6和3是否是亲戚;
注意:以上算法有个问题:只有在找到根节点时,下一次合并才会连接到根节点上,如果根节点最后才遍历到,那会形成只有一条链的结构,查询时间将大幅度增加
4. 优化
优化find(int x):
若我们需要查找的数据连成一条链,时间复杂度必然很高,因为并查集算法不看过程,只在意最后的根节点,所以可以在查询根节点时就改变整个查询链上的节点的前一节点为根节点:
- 代码:
int find(int x){ if(x!=node[x]){ node[x]=find(node[x]); } return node[x]; } - 解析:递归到最底层返回是根节点的下标
i,令node[x]=i即可实现查询链上的所有结点的前一下标都为根节点
优化union(int x,int y):
如有以下两个链,是该将[1,2,3]并入[4]还是反过来呢?
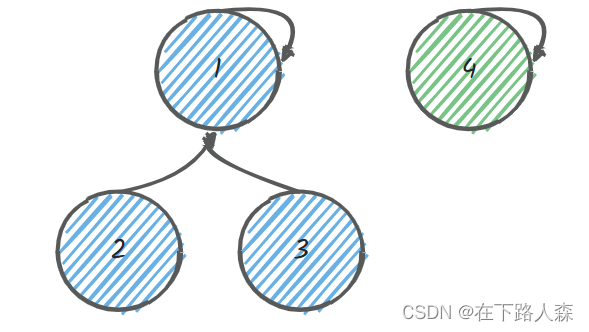
显然,为了使查询的时间更短,我们最后构造的树型结构高度要尽可能低,所以是将[4]并入[1,2,3],但如何确定呢?
- 这里我们需要维护一个树高(秩)数组
rank(初始值都为1),存储每个结点的高度 - 两个结点的根节点的
rank值小的并入大的 - 根节点
rank值相等则随便并入哪一个,但并入操作完成后的根节点rank值+1 - 代码:
void union(int x,int y){ int root1=find(x); int root2=find(y); if(root1==root2)return;//在同一个链上,则不用合并 if(rank[root1]<rank[root2])node[root1]=root2; else{ if(rank[root1]==rank[root2])rank[root1]++;//合并后作为根节点的结点的rank值+1 node[root2]=root1; } }
5. 综上
创建一个单独的类UF:
public class UF {
int[]node;
int[]rank;
UFUtil(int n){//初始化
node=new int[n+1];
for(int i=1;i<=n;i++){
node[i]=i;
rank[i]=1;
}
}
int find(int x){
if(x==node[x])return x;
else{
node[x]=find(node[x]);
return node[x];
}
}
void union(int x,int y){
int root1=find(x);
int root2=find(y);
if(root1==root2)return;
if(rank[root1]<rank[root2])node[root1]=root2;
else{
if(rank[root1]==rank[root2])rank[root1]++;
node[root2]=root1;
}
}
}
6. 练习
题目
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
输入:nums = [100,4,200,1,3,2]
输出:4
解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
示例 2:
输入:nums = [0,3,7,2,5,8,4,6,0,1]
输出:9
提示:
0 <= nums.length <= 105
-109 <= nums[i] <= 109
代码及解析:
这题解法有很多,此处展示并查集的解法:
class Solution {
Map<Integer,Integer>map=new HashMap<>();
public int longestConsecutive(int[] nums) {
int len=nums.length;
UF uf=new UF(len);
for(int i=0;i<len;i++){
//如果数字已存在则不需要再操作
if(map.containsKey(nums[i]))continue;
//nums[i]-1存在,符合合并条件,合并nums[i]-1的下标和下标i+1
if(map.containsKey(nums[i]-1))uf.union(i+1,map.get(nums[i]-1));
//nums[i]+1存在,符合合并条件,合并nums[i]+1的下标和下标i+1
if(map.containsKey(nums[i]+1))uf.union(i+1,map.get(nums[i]+1));
//往map存入
map.put(nums[i], i+1);
}
return uf.getMax();
}
}
class UF {
int[]node;
int[]rank;
UF(int n){
node=new int[n+1];
rank=new int[n+1];
for(int i=1;i<=n;i++){
node[i]=i;
rank[i]=1;
}
}
int find(int x){
if(x!=node[x]){
node[x]=find(node[x]);
}
return node[x];
}
void union(int x,int y){
int root1=find(x);
int root2=find(y);
if(root1==root2)return;
if(rank[root1]<rank[root2])node[root1]=root2;
else{
if(rank[root1]==rank[root2])rank[root1]++;
node[root2]=root1;
}
}
int getMax(){
Map<Integer,Integer>map=new HashMap<>();
int max=0;
for(int i=1;i<node.length;i++){
int t=find(node[i]);
map.put(t, map.getOrDefault(t, 0)+1);
if(map.get(t)>max)max=map.get(t);
}
return max;
}
}
注意:上面解题方法中getMax方法,采用遍历每一个结点,找出根节点find(node[i]);存入新创建的map中,再读取取得最大值。(此map存储根节点对应的结点总数)
int getMax(){
Map<Integer,Integer>map=new HashMap<>();
int max=0;
for(int i=1;i<node.length;i++){
int t=find(node[i]);
map.put(t, map.getOrDefault(t, 0)+1);
if(map.get(t)>max)max=map.get(t);
}
return max;
}
代码优化
为了契合举例分析中的例子,此处未将程序进行优化
此题优化:
- 将
rank数组存储高度改成size数组存储有多少结点指向自己; - 初始化也都为
1 - 合并时若
root1成为根节点,则size[root1]+=size[root2]; - 合并规则可根据
size大小或不做任何规则















 562
562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









