






1.打开你想导出字幕的视频
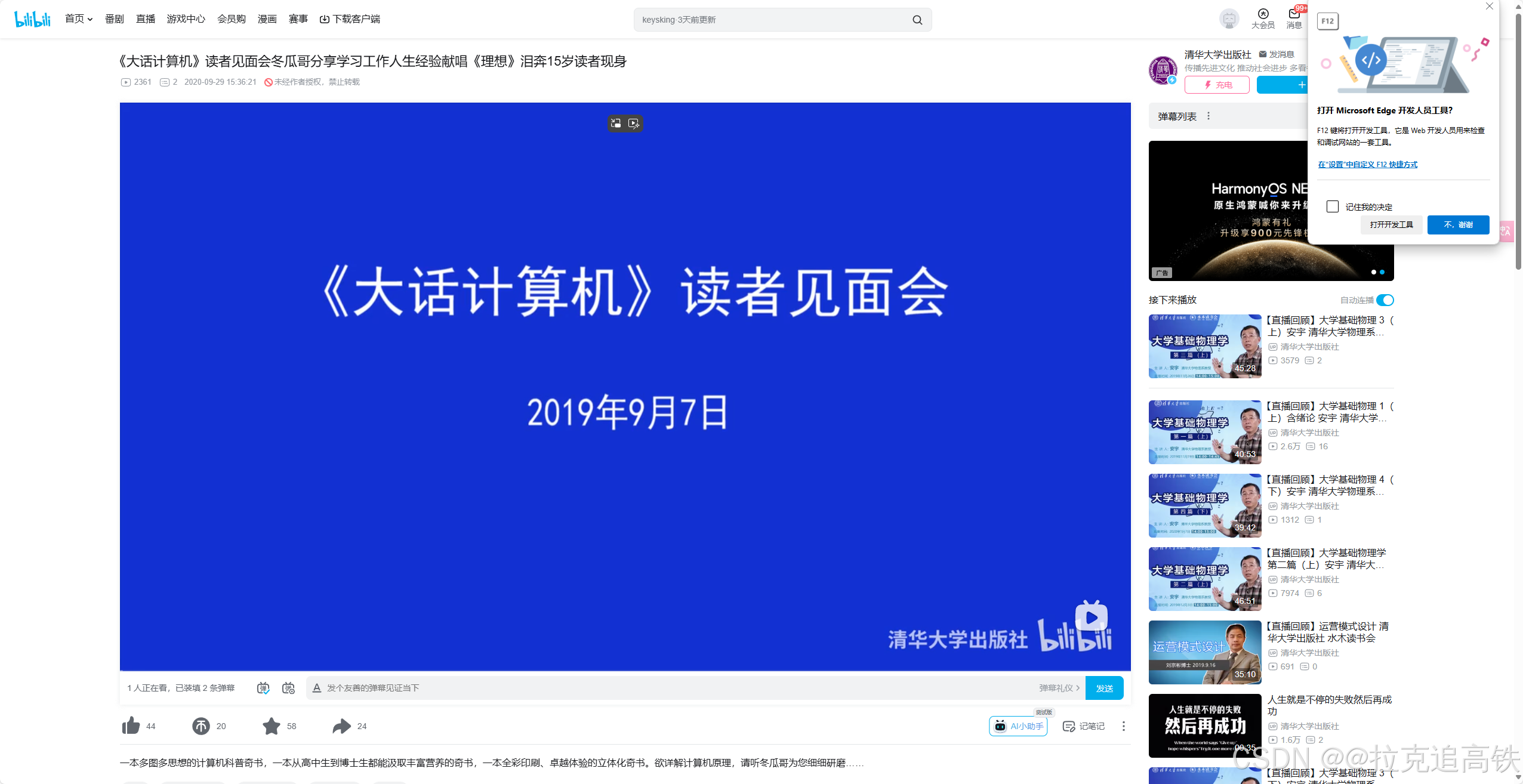
2.按F12右上角弹出开发工具选项,若未弹出则按Fn+F12
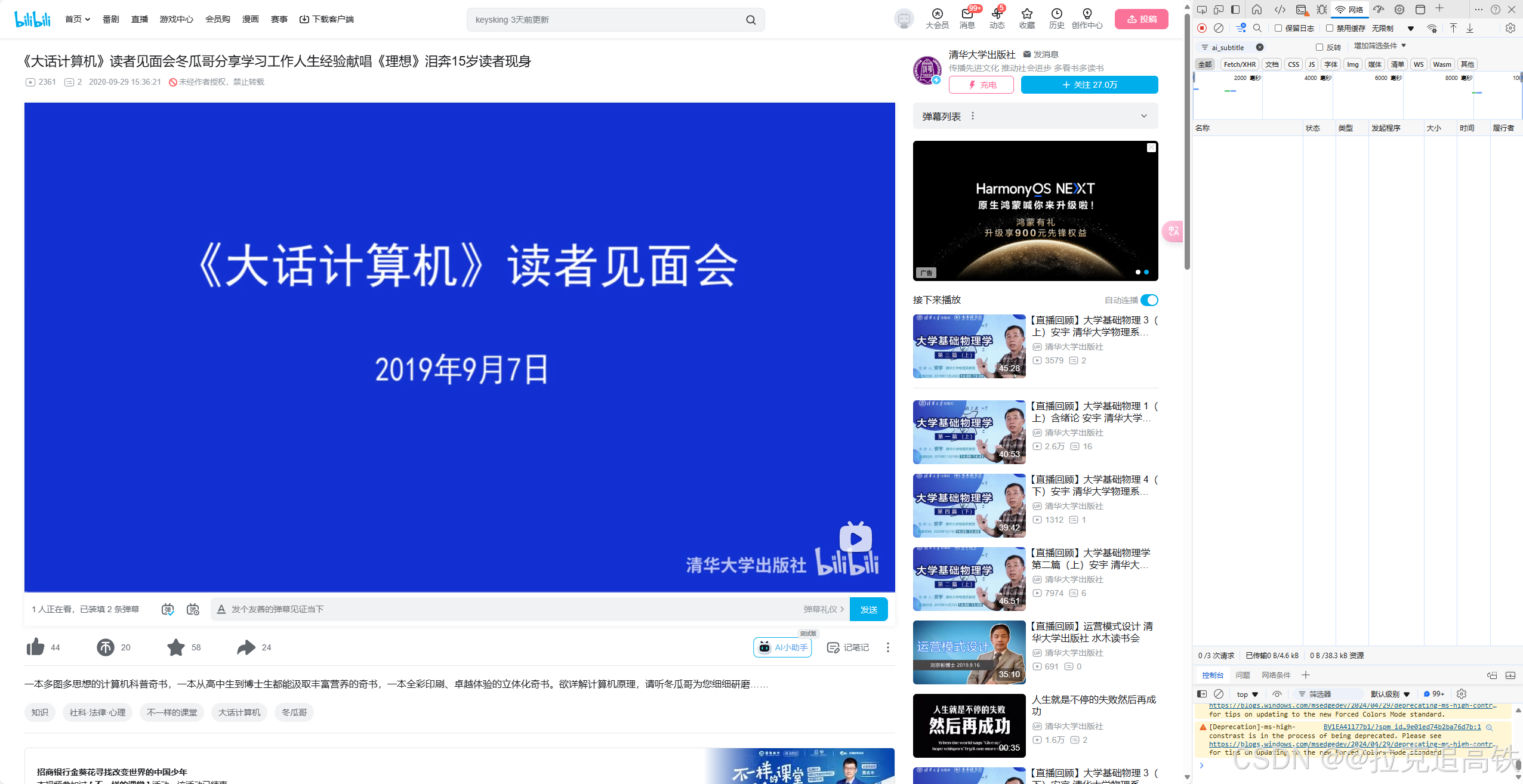
3.单击打开开发工具,进入开发页面
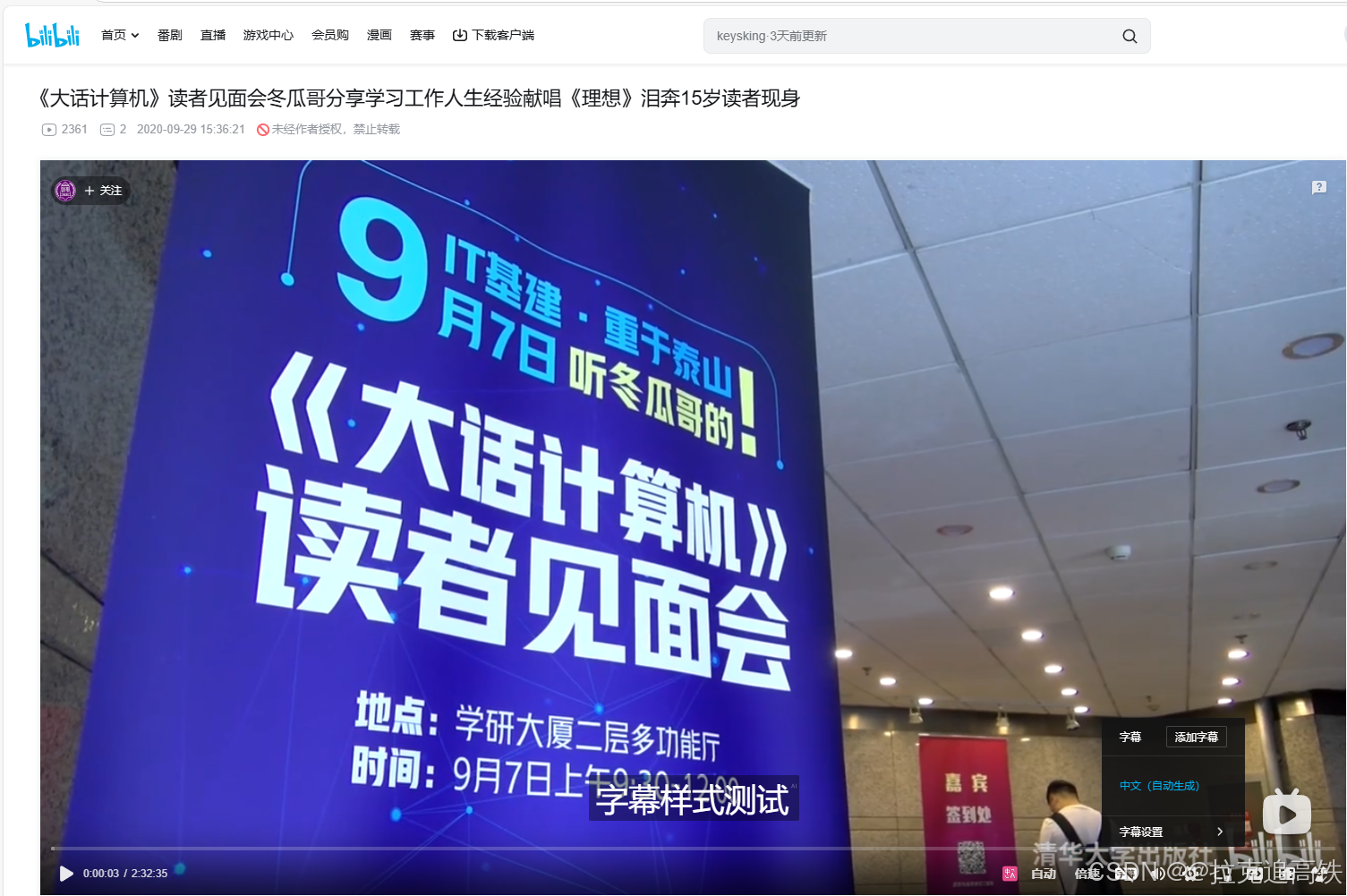
4.打开字幕
5.点击上方的网络,在搜索框中输入ai_subitile,下方弹出的文件中选第一个。若此时文件为弹出,则刷新视频页面,重新打开字幕重复第五步操作
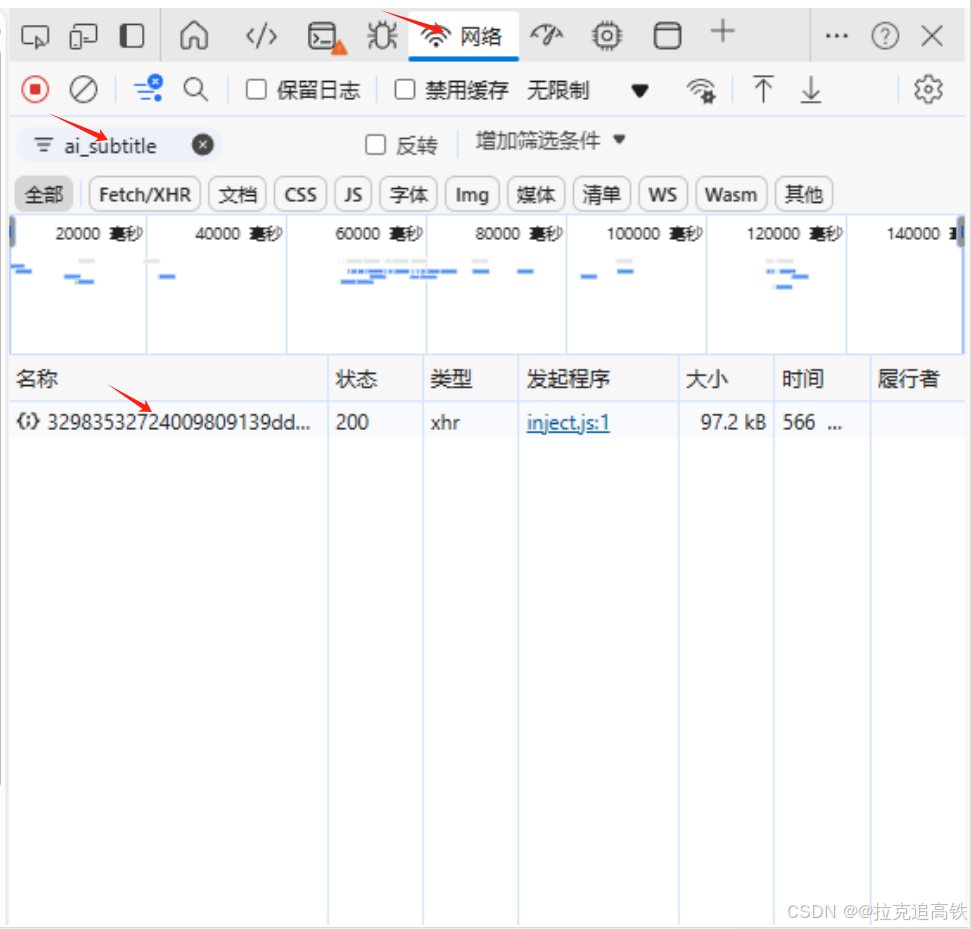
6.单击弹出的第一个文件,点击响应,复制所有代码
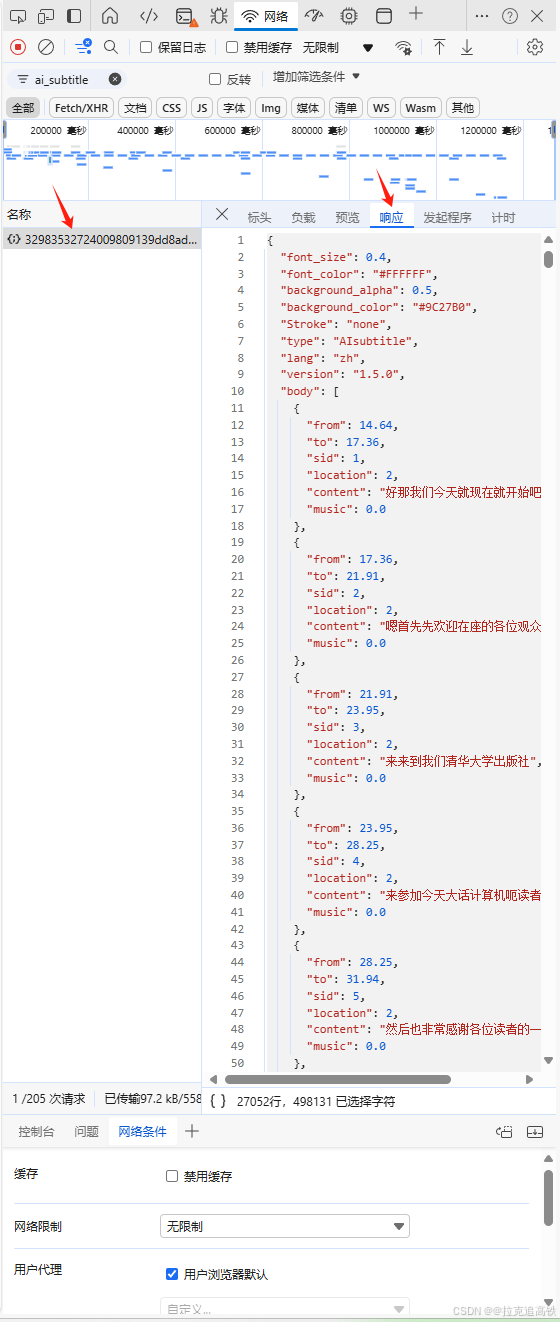
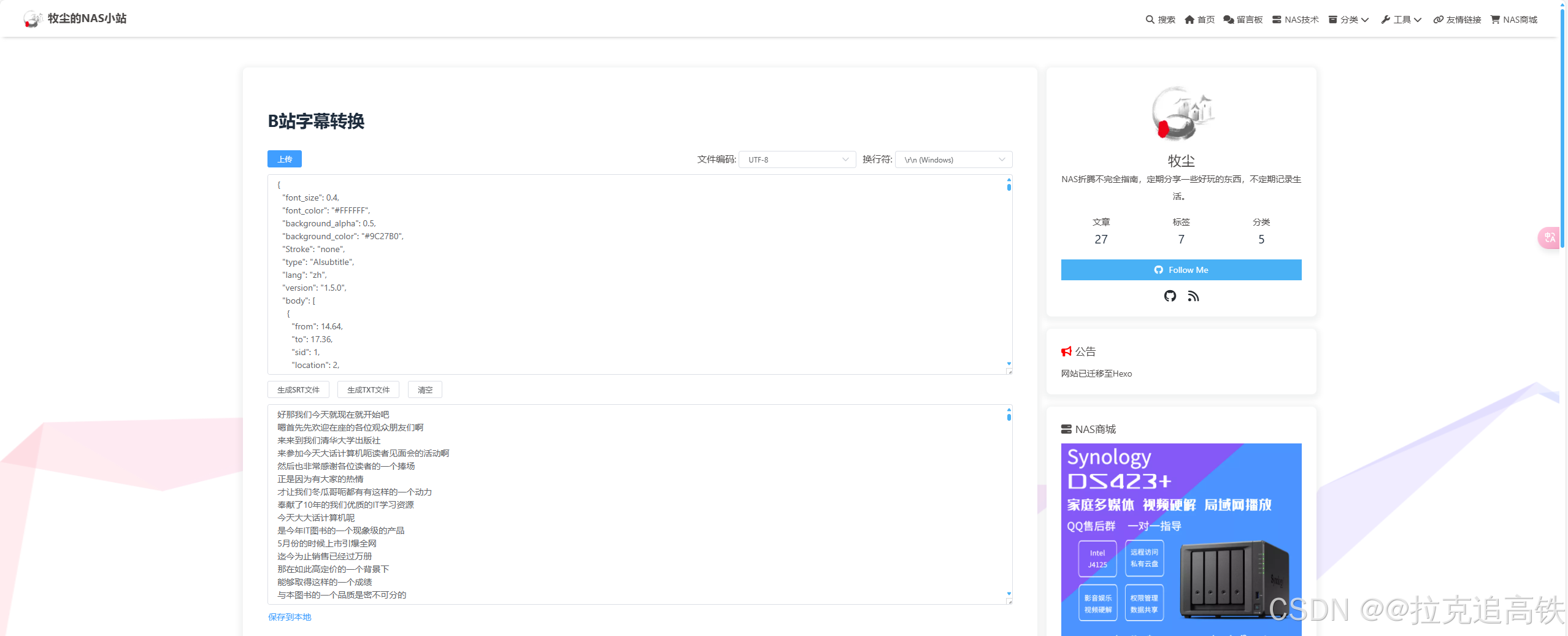
7.打开此网址,将复制的代码粘贴值代码框然后转换即可B站字幕转换 | 牧尘的NAS小站
8.如有疑问,评论区留言
1.打开你想导出字幕的视频
2.按F12右上角弹出开发工具选项,若未弹出则按Fn+F12
3.单击打开开发工具,进入开发页面
4.打开字幕
5.点击上方的网络,在搜索框中输入ai_subitile,下方弹出的文件中选第一个。若此时文件为弹出,则刷新视频页面,重新打开字幕重复第五步操作
6.单击弹出的第一个文件,点击响应,复制所有代码
7.打开此网址,将复制的代码粘贴值代码框然后转换即可B站字幕转换 | 牧尘的NAS小站
8.如有疑问,评论区留言
 4761
1918
3691
9670
4761
1918
3691
9670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























