






条形图
条形图是一种常用的数据可视化图表类型,有多种常用的形式,可以根据数据的性质和目的选择适当的形式。以下是一些常见的条形图形式:
- 垂直条形图(Vertical Bar Chart):
- 场景: 适用于展示不同类别之间的比较,特别是当类别数量有限且类别名称较短时。
- 使用方法: 每个垂直条形代表一个类别,条形的高度表示相应类别的数值。可以用于显示单一数据系列或多个数据系列的比较。
- 水平条形图(Horizontal Bar Chart):
- 场景: 适用于比较不同类别,尤其是类别数量较多或类别名称较长时。水平条形图更易于展示长名称。
- 使用方法: 每个水平条形代表一个类别,条形的长度表示相应类别的数值。同样可以用于显示单一数据系列或多个数据系列的比较。
- 堆叠条形图(Stacked Bar Chart):
- 场景: 用于显示总量及各部分的相对贡献,特别是关注整体趋势以及各组成部分之间的比例。
- 使用方法: 每个垂直条形或水平条形的高度(或长度)代表总量,而不同颜色的堆叠部分表示不同的数据系列。可以突出整体趋势,同时展示各组成部分的相对贡献。
- 分组条形图(Grouped Bar Chart):
- 场景: 用于直观比较不同类别 内的不同组 的数据,强调类别内部的差异。
- 使用方法: 将每个类别内的不同数据系列的条形并排分组,每个组内的条形表示一个数据系列。这样可以清晰地比较不同组之间的差异,同时可以比较同一组内不同数据系列的数值。
matplotlib绘制条形图
单图示例代码
垂直条形图
import matplotlib.pyplot as plt
# 示例数据
categories = ['Category A', 'Category B', 'Category C', 'Category D']
values = [25, 50, 75, 100]
# 创建条形图
plt.bar(categories, values)
# 添加标题和标签
plt.title('Bar Chart Example')
plt.xlabel('Categories')
plt.ylabel('Values')
# 显示条形图
plt.show()
水平条形图
import matplotlib.pyplot as plt
# 示例数据
categories = ['Category A', 'Category B', 'Category C', 'Category D']
values = [25, 50, 75, 100]
# 创建水平条形图
plt.barh(categories, values)
# 添加标题和标签
plt.title('Horizontal Bar Chart Example')
plt.xlabel('Values')
plt.ylabel('Categories')
# 显示水平条形图
plt.show()
在Matplotlib中,绘制垂直条形图和水平条形图的主要区别在于使用的函数和参数的设置:
- 垂直条形图:
- 使用
plt.bar(x, height, ...),其中x是类别数据(例如类别标签),height是数值数据(例如对应的数值)。- 水平条形图:
- 使用
plt.barh(y, width, ...),其中y是类别数据(例如类别标签),width是数值数据(例如对应的数值)。
多图示例代码
import matplotlib.pyplot as plt
# 示例数据
categories = ['Category A', 'Category B', 'Category C', 'Category D']
values_1 = [25, 50, 75, 100]
values_2 = [10, 30, 50, 70]
# 创建两个子图
fig, axs = plt.subplots(1, 2, figsize=(10, 4))
# 第一个子图
axs[0].bar(categories, values_1, color='blue')
axs[0].set_title('Bar Chart 1')
# 第二个子图
axs[1].bar(categories, values_2, color='green')
axs[1].set_title('Bar Chart 2')
# 显示图形
plt.show()
seaborn绘制条形图
单图示例代码
垂直条形图
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(rc={ 'font.sans-serif': ['simhei', 'Arial']}) # 处理图形显示中文乱码问题
# 示例数据
categories = ['类别A', '类别B', '类别C', '类别D']
values = [25, 50, 75, 100]
# 创建条形图
sns.barplot(x=categories, y=values, color='skyblue')
# 添加标题和标签
plt.title('Seaborn 条形图示例')
plt.xlabel('类别')
plt.ylabel('数值')
# 显示条形图
plt.show()
水平条形图
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(rc={ 'font.sans-serif': ['simhei', 'Arial']}) # 处理图形显示中文乱码问题
# 示例数据
categories = ['类别A', '类别B', '类别C', '类别D']
values = [25, 50, 75, 100]
# 创建水平条形图
sns.barplot(x=values, y=categories, color='skyblue')
# 添加标题和标签
plt.title('Seaborn 横向条形图示例')
plt.xlabel('数值')
plt.ylabel('类别')
# 显示横向条形图
plt.show()
- 当使用Seaborn绘制垂直条形图和水平条形图时,主要区别在于参数
x和y的数据类型和含义:
- 垂直条形图:
- 使用
sns.barplot(x, y, ...),其中x是类别数据(例如类别标签),y是数值数据(例如对应的数值)。- 水平条形图:
- 仍然使用
sns.barplot(x, y, ...),但在水平条形图中,x是数值数据(例如对应的数值),而y是类别数据(例如类别标签)。
多图示例代码
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(rc={'font.sans-serif': ['simhei', 'Arial']}) # 处理图形显示中文乱码问题
# 示例数据
categories = ['类别A', '类别B', '类别C', '类别D']
values_1 = [25, 50, 75, 100]
values_2 = [15, 30, 45, 60]
# 创建一个包含两个子图的图表
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
# 绘制第一个条形图
sns.barplot(x=categories, y=values_1, color='skyblue', ax=axes[0])
axes[0].set_title('数据集1')
# 绘制第二个条形图
sns.barplot(x=categories, y=values_2, color='lightgreen', ax=axes[1])
axes[1].set_title('数据集2')
# 显示图形
plt.show()
plotly绘制条形图
plotly绘制折线图有多种指定数据的方式:
-
x、y为可迭代类型,如列表、数组;
-
bar第一个参数指定为DataFrame,x为该DataFrame的一个列名,y也为该DataFrame的一个列名;
-
bar的第一个参数指定为Series,x为索引,y为值;
-
# 记住数据是DataFrame与时series是的区别是: # dataframe选取某一列直接用列名,而series是用index、values的!
单图示例代码
垂直条形图
import plotly.express as px
# 示例数据
categories = ['类别A', '类别B', '类别C', '类别D']
values = [25, 50, 75, 100]
# 创建条形图
fig = px.bar(
x=categories,
y=values,
labels={'y': '数值'},
color_discrete_sequence=['skyblue', 'lightgreen'],
title='垂直条形图示例',
category_orders={'x': categories} # 指定在图表中的类别轴上的顺序
)
# 显示图形
fig.show()
水平条形图
import plotly.express as px
# 示例数据
categories = ['类别A', '类别B', '类别C', '类别D']
values = [25, 50, 75, 100]
# 创建水平条形图
fig = px.bar(
x=values,
y=categories,
orientation='h', # orientation: 可选,条形的方向。'v' 表示垂直条形图,'h' 表示水平条形图。
labels={'y': '类别'},
color_discrete_sequence=['skyblue', 'lightgreen'],
title='条形图示例',
category_orders={'x': categories} # 指定在图表中的类别轴上的顺序
)
# 显示图形
fig.show()
当使用 Plotly Express 绘制垂直条形图和水平条形图时,主要区别在于:
- 垂直条形图:
- 默认情况下,条形图是垂直方向的。
- 设置
x为类别数据,y为数值数据。- 水平条形图:
- 使用
orientation='h'参数将条形图方向设置为水平方向。- 设置
x为数值数据,y为类别数据。
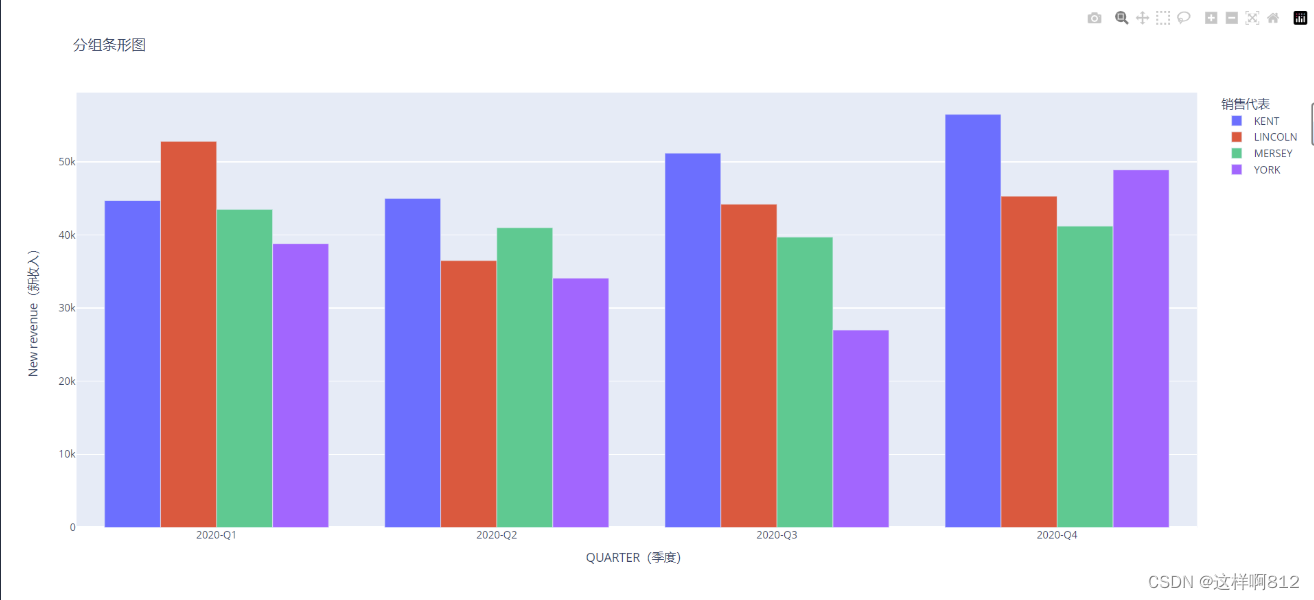
分组条形图
import plotly.express as px
import pandas as pd
# 创建数据字典
data = {
'QUARTER': ['2020-Q1', '2020-Q2', '2020-Q3', '2020-Q4'],
'KENT': [44700, 45000, 51200, 56500],
'LINCOLN': [52800, 36500, 44200, 45300],
'MERSEY': [43500, 41000, 39700, 41200],
'YORK': [38800, 34100, 27000, 48900]
}
# 使用数据字典创建DataFrame
df = pd.DataFrame(data)
# 使用px.bar创建分组条形图
fig = px.bar(df,
x='QUARTER',
y=['KENT', 'LINCOLN', 'MERSEY', 'YORK'],
barmode='group', # barmode='group' 绘制分组条形图
labels={'QUARTER': 'QUARTER(季度)', 'value': 'New revenue(新收入)', 'variable': '销售代表'},
title='分组条形图')
# 显示图表
fig.show()
labels参数用于指定图表中各个轴的标签,具体解释如下:
'QUARTER': 指定x轴(横轴)的标签,这里表示季度。'value': 指定y轴(纵轴)的标签,这里表示新收入。'variable': 指定legend标签的显示名称,这里表示不同的销售代表
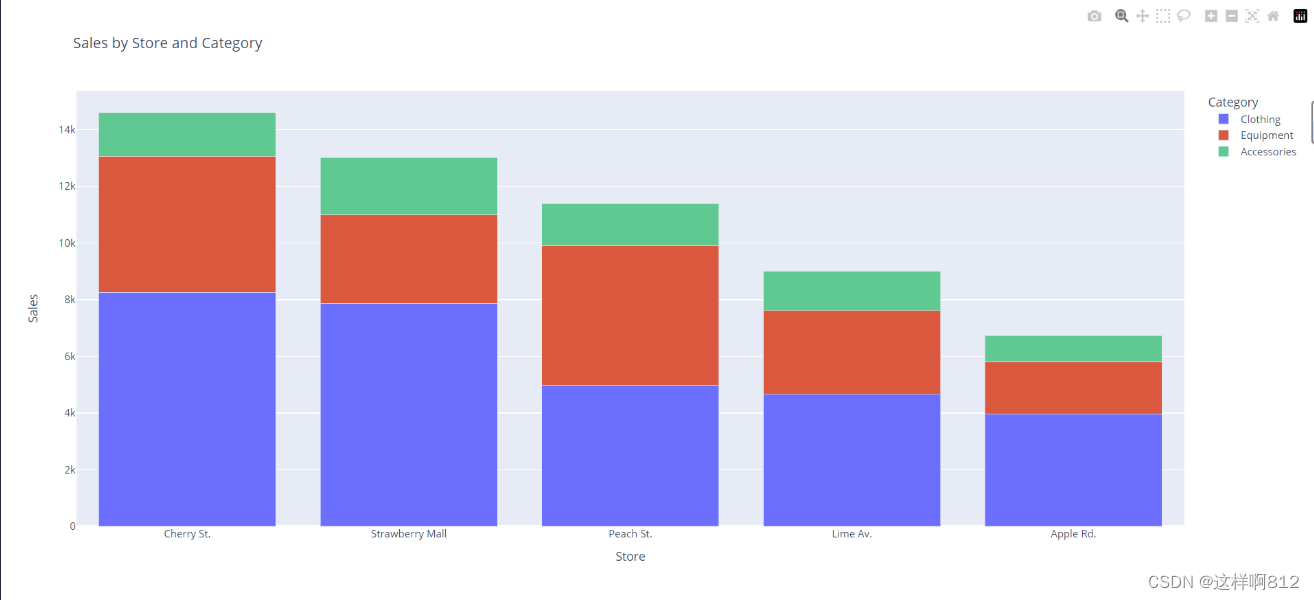
堆叠条形图
import plotly.express as px
import pandas as pd
# 创建数据字典
data = {
'Store': ['Cherry St.', 'Strawberry Mall', 'Peach St.', 'Lime Av.', 'Apple Rd.'],
'Clothing': [8261.68, 7875.87, 4990.23, 4658.42, 3952.00],
'Equipment': [4810.34, 3126.58, 4923.48, 2955.55, 1858.46],
'Accessories': [1536.57, 2019.81, 1472.59, 1390.55, 917.90]
}
# 使用数据字典创建DataFrame
df = pd.DataFrame(data)
# 使用px.bar绘制堆叠条形图
fig = px.bar(df,
x='Store',
y=['Clothing', 'Equipment', 'Accessories'],
barmode='stack', # barmode='stack' 绘制堆叠条形图
title='Sales by Store and Category',
labels={'value': 'Sales', 'variable': 'Category'},
)
# 显示图形
fig.show()
labels`参数用于指定图表中各个轴的标签,具体解释如下:
'value': 指定y轴(纵轴)的标签,这里表示销售额(Sales)。'variable': 指定legend标签的显示名称,这里表示不同的类别(Category),即服装、设备和配饰。
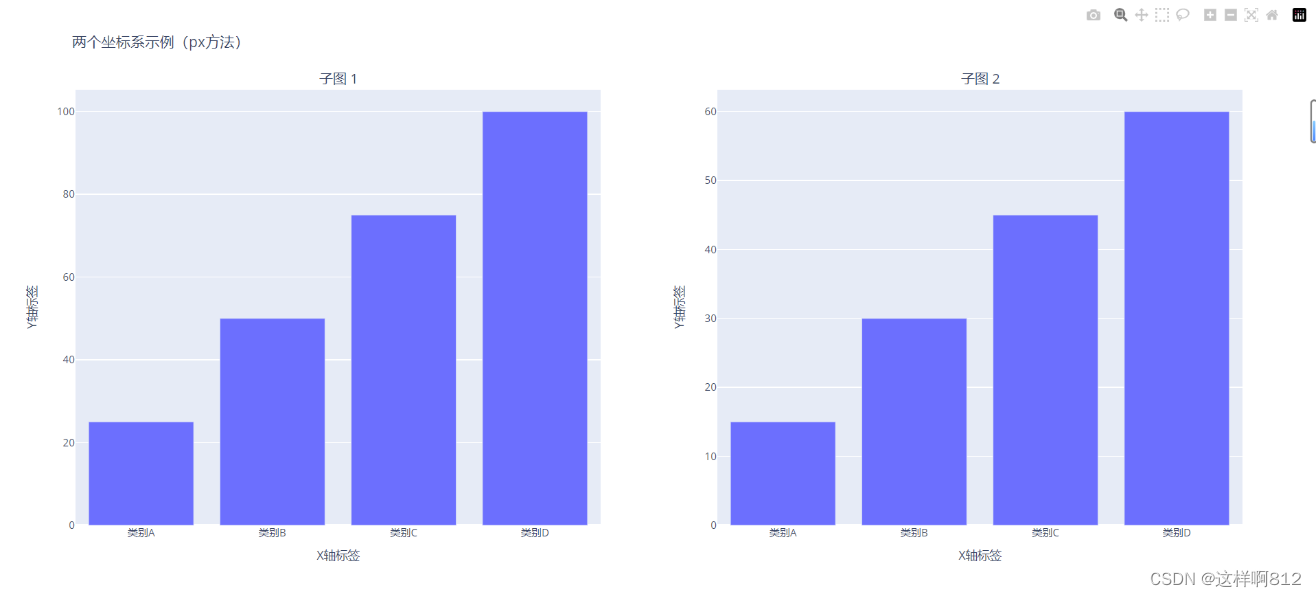
多图示例代码
Plotly Graph Objects(go)方法
import plotly.express as px
from plotly.subplots import make_subplots
# 示例数据
categories = ['类别A', '类别B', '类别C', '类别D']
values_1 = [25, 50, 75, 100]
values_2 = [15, 30, 45, 60]
# 创建子图
fig = make_subplots(rows=1, cols=2, subplot_titles=("子图 1", "子图 2"))
# 添加第一个子图
trace1 = px.bar(x=categories, y=values_1)
fig.add_trace(trace1.data[0], row=1, col=1)
# 添加第二个子图
trace2 = px.bar(x=categories, y=values_2)
fig.add_trace(trace2.data[0], row=1, col=2)
# 更新图表布局
fig.update_layout(
title="两个坐标系示例(px方法)",
xaxis=dict(title="X轴标签"),
yaxis=dict(title="Y轴标签"),
xaxis2=dict(title="X轴标签"),
yaxis2=dict(title="Y轴标签"),
)
# 显示图形
fig.show()
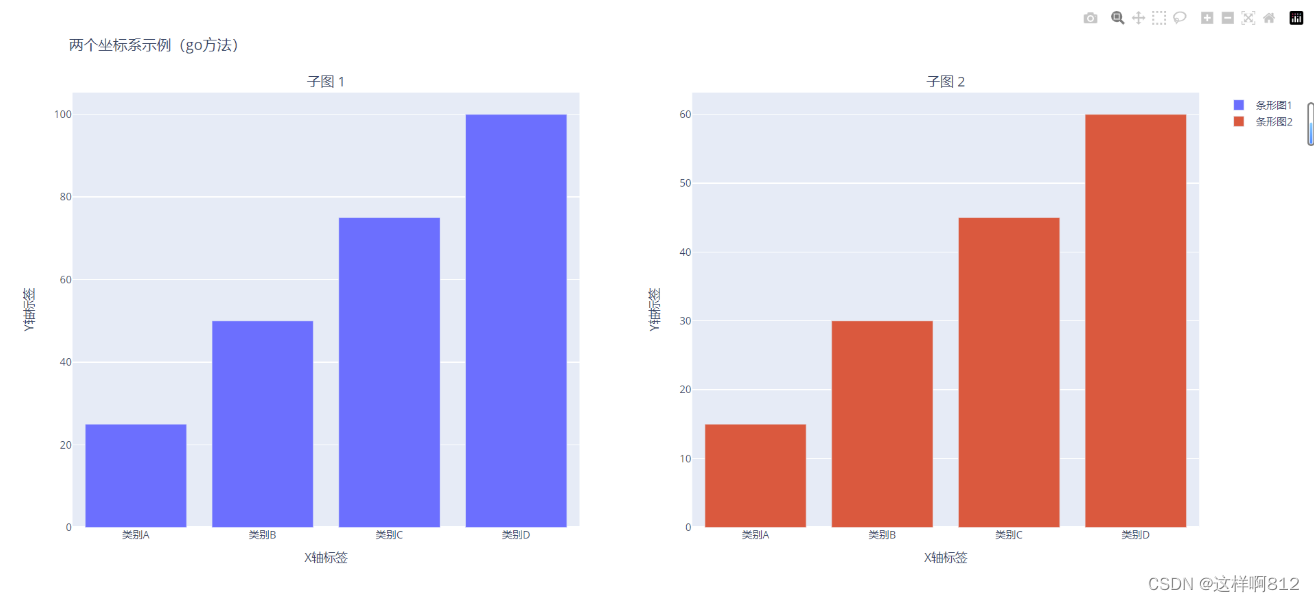
Plotly Express(px)方法
import plotly.graph_objects as go
from plotly.subplots import make_subplots
# 示例数据
categories = ['类别A', '类别B', '类别C', '类别D']
values_1 = [25, 50, 75, 100]
values_2 = [15, 30, 45, 60]
# 创建子图
fig = make_subplots(rows=1, cols=2, subplot_titles=("子图 1", "子图 2"))
# 添加第一个子图
trace1 = go.Bar(x=categories, y=values_1, name="条形图1")
fig.add_trace(trace1, row=1, col=1)
# 添加第二个子图
trace2 = go.Bar(x=categories, y=values_2, name="条形图2")
fig.add_trace(trace2, row=1, col=2)
# 更新图表布局
fig.update_layout(
title="两个坐标系示例(go方法)",
xaxis=dict(title="X轴标签"),
yaxis=dict(title="Y轴标签"),
xaxis2=dict(title="X轴标签"),
yaxis2=dict(title="Y轴标签"),
)
# 显示图形
fig.show()
案例
该部分包含了常用的垂直、水平、分组、堆叠条形图实例,绘图中存在一些细节,具体见后方内容。
水平条形图
数据为DataFrame类型
利用水平条形图,展示了 YouTube 上订阅者数量最多的前 10 个频道(Youtuber),图表中的条形的颜色代表了对应频道的订阅者数量。
import plotly.express as px
# 准备top10数据,选择基于'subscribers'的前10条记录
top_10_subscribers = data.nlargest(10, 'subscribers')
# 根据'subscribers'升序排序数据(可选) --> 水平条形实现升序降序
# top_10_subscribers = top_10_subscribers.sort_values(by='subscribers', ascending=True)
# 绘制水平条形图
fig = px.bar(top_10_subscribers,
x='subscribers', # x轴的数值
y='Youtuber', # y轴的类别(YouTube频道名称)
orientation='h', # 水平条形图
text='subscribers', # 在条形上显示订阅者数量的文本
title="Top 10 YouTube Channels by Subscribers", # 图表标题
height=500, # 图表高度
opacity=0.8, # 条形的不透明度
color='subscribers', # 根据'subscribers'着色
labels={'subscribers': 'subscribers (in billions)', 'Youtuber': 'Youtube Channel'}, # 轴标签
color_continuous_scale='Viridis' # 着色的颜色刻度
)
# 自定义图表的外观
fig.update_traces(marker_line_color='rgb(8,48,107)', # 设置条形的边框颜色
marker_line_width=1.5, # 设置条形的边框宽度
textposition='inside' # 设置文本位置在条形内部
)
# 显示图表
fig.show()

### px.bar api说明
# data_frame: 必需,一个 pandas DataFrame,包含要绘制的数据。
# x: 必需,指定 x 轴上要显示的数据列。
# y: 必需,指定 y 轴上要显示的数据列。
# color: 可选,用于为条形图的不同条形着色的数据列。
# text:可选,为每个条形添加文本标签,这些文本标签可以显示在条形的上方、下方或内部
# title: 可选,图表的标题。
# width 和 height: 可选,设置图表的宽度和高度。
# labels: 可选,用于指定 x 轴和 y 轴的标签。
# orientation: 可选,条形的方向。'v' 表示垂直条形图,'h' 表示水平条形图。
# opacity:可选,用于设置条形的不透明度,即控制条形的填充颜色的透明度。
# color_continuous_scale:可选,设置连续色彩映射的参数。这个参数接受一个色彩映射名称(比如 "Viridis"、"YlOrRd" 等)或一个色彩映射列表
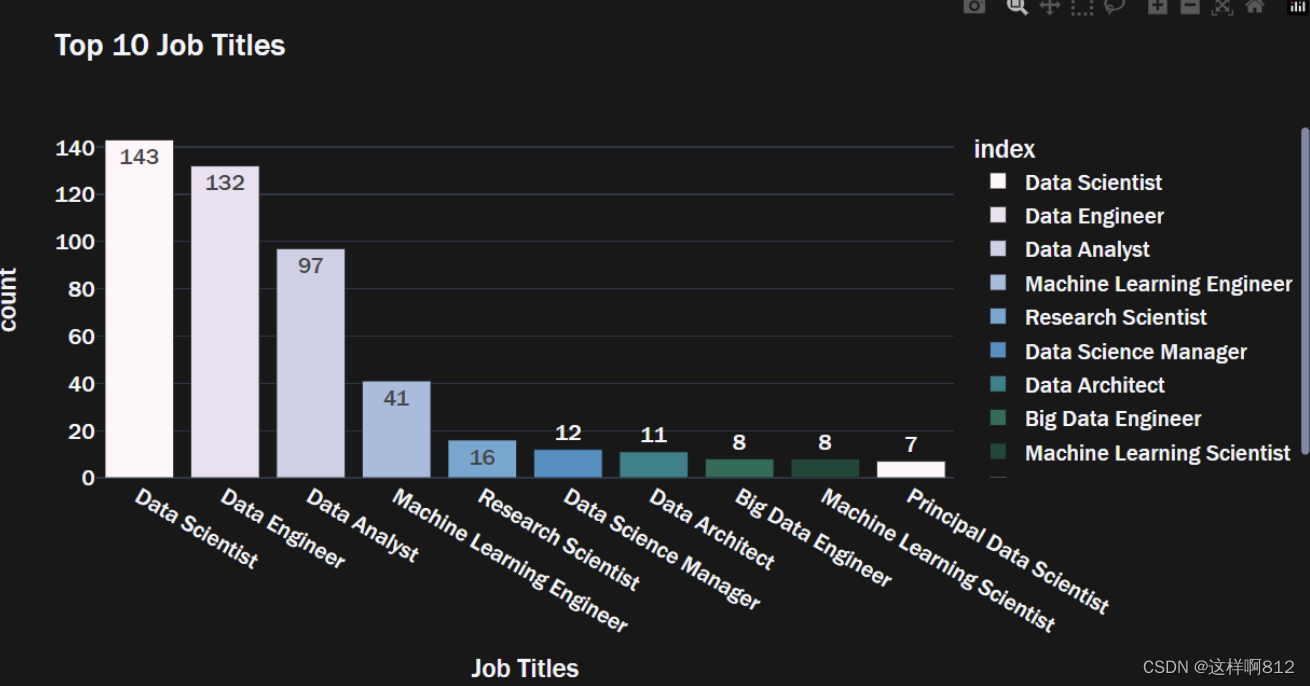
数据为Series类型
# 1、series的索引数据是字符串类型 --> 可直接用下面方法
import plotly.express as px
# 准备数据
top10_job_title = XXX # XXX是你的数据Series对象,包含索引和值信息
# 画图
fig = px.bar(top10_job_title,
x=top10_job_title.index,
y=top10_job_title.values,
color=top10_job_title.index,
color_discrete_sequence=px.colors.sequential.PuBuGn, # 这是一个蓝绿色调的渐变颜色序列
text=top10_job_title.values,
title='Top 10 Job Titles',
template='plotly_dark')
# 更新图表布局和标签
fig.update_layout(
xaxis_title="Job Titles",
yaxis_title="Count",
font=dict(size=17, family="Franklin Gothic")
)
# 显示图表
fig.show()
对于字符串类型的索引,
px.bar函数会自动将该索引用作横坐标(x轴),并且会使用y参数指定的数值数据作为纵坐标(y轴)。这种情况下,横坐标上的刻度会被设置为字符串标签,使得绘制的条形图更符合字符串索引的特性。
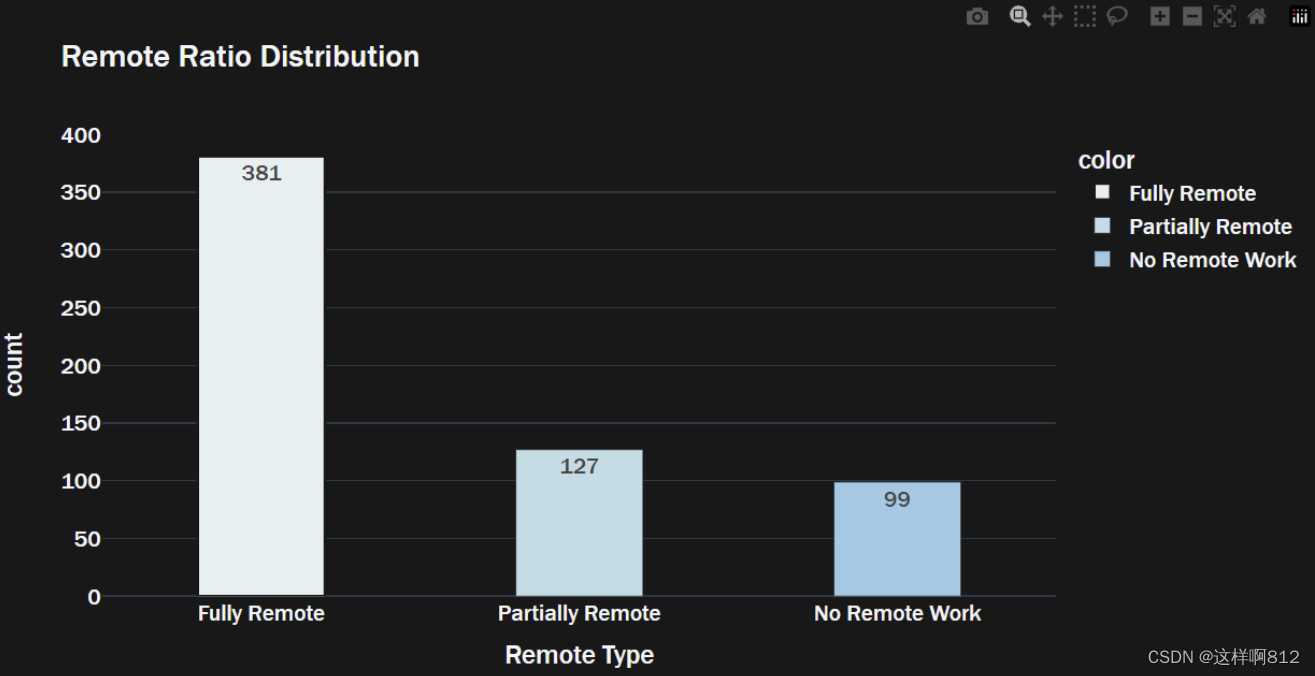
# 2、series索引数据是数值时 --> 需要指定x轴的离散类别,不然的话就被api理解为了连续型数据,导致画的图不对
import plotly.express as px
# 指定x轴上的数据离散类别
remote_type = ['Fully Remote', 'Partially Remote', 'No Remote Work']
# 准备数据,data是你的数据 Series
data = ...
# 画图
fig = px.bar(data,
x=remote_type,
y=data.value_counts().values,
color=remote_type,
color_discrete_sequence=px.colors.sequential.dense, # 这是一种密集的渐变颜色序列
text=data.value_counts().values,
title='Remote Ratio Distribution',
template='plotly_dark')
# 更新条形的宽度和边框线宽度
fig.update_traces(width=0.4)
fig.data[0].marker.line.width = 2
# 更新图表布局和标签
fig.update_layout(
xaxis_title="Remote Type",
yaxis_title="Count",
font=dict(size=17, family="Franklin Gothic")
)
# 显示图表
fig.show()
当把series索引数据理解为了连续型(即依旧是用1、series的索引数据是字符串类型的代码来画图)时将绘制出如下错误图形:

update_traces和update_layout是 Plotly 中用于更新图表外观和布局的两个不同的方法。它们分别用于更新图表的不同部分。
- update_traces: 用于更新与每个图表元素(trace)相关的属性。在 Plotly 中,trace 是图表中的一个数据集,比如条形图中的一根条形,散点图中的一组点等。通过
update_traces,您可以修改每个 trace 的外观属性,例如颜色、线宽、文本等。fig.update_traces(marker_color='blue', marker_size=10, textposition='inside')
- update_layout: 用于更新整个图表的布局和其他全局属性。通过
update_layout,您可以修改整个图表的外观,包括标题、轴标签、图例位置等。fig.update_layout(title='My Chart', xaxis_title='X Axis', yaxis_title='Y Axis', legend=dict(x=0, y=1))这两个方法是对图表的不同层次进行操作的。
update_traces更专注于个别 trace 的属性,而update_layout更专注于整体图表的布局和外观。
分组条形图
数据为单层索引的DataFrame
用前面单图示例代码中分组条形图的代码方式来写即可。
数据为多层索引的Series
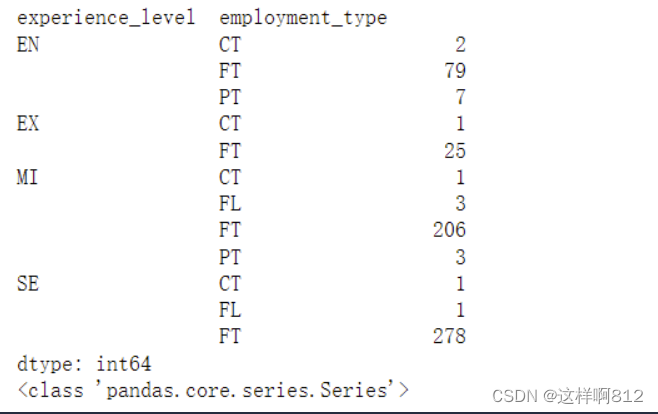
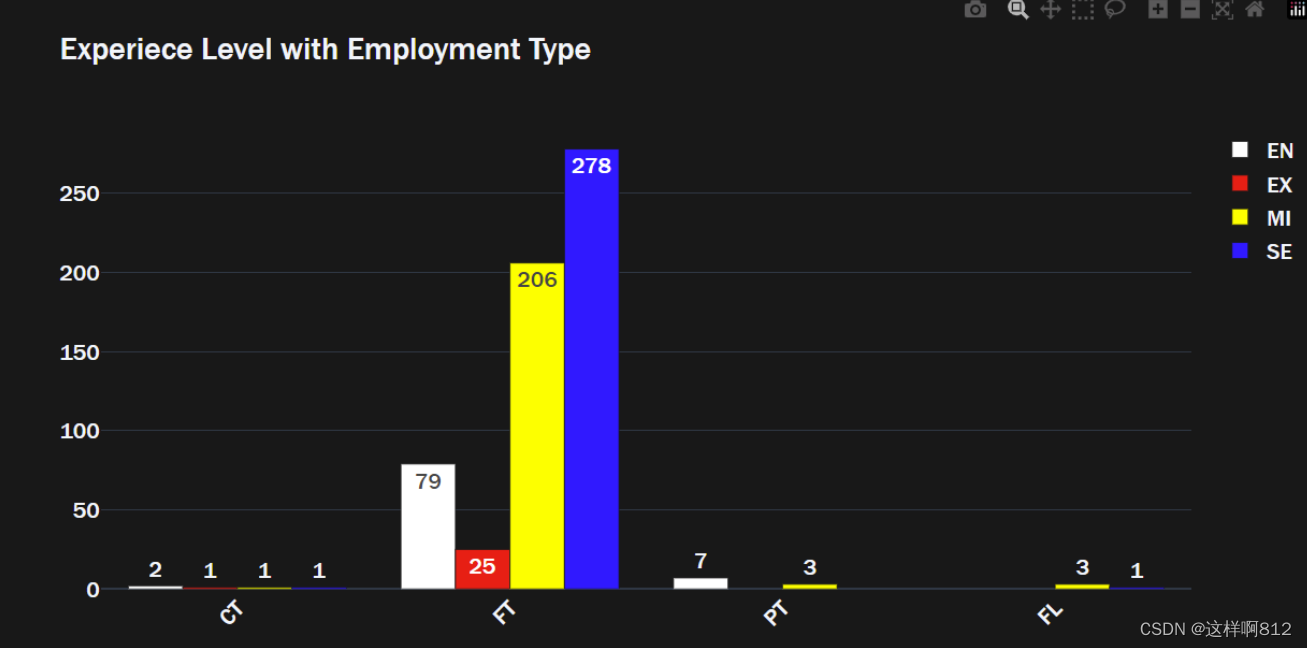
import plotly.graph_objects as go
# 准备数据 这个的数据显示在上面的图中
exlevel_type = XXX
# 创建一个 go.Figure 对象,其中包含四个条形图 (go.Bar)。
fig = go.Figure(data=[
go.Bar(name='EN', x=exlevel_type['EN'].index, y=exlevel_type['EN'].values, # name 条形图的名称
text=exlevel_type['EN'].values, marker_color='white'),
go.Bar(name='EX', x=exlevel_type['EX'].index, y=exlevel_type['EX'].values,
text=exlevel_type['EX'].values, marker_color='red'),
go.Bar(name='MI', x=exlevel_type['MI'].index, y=exlevel_type['MI'].values,
text=exlevel_type['MI'].values, marker_color='yellow'),
go.Bar(name='SE', x=exlevel_type['SE'].index, y=exlevel_type['SE'].values,
text=exlevel_type['SE'].values, marker_color='blue'),
])
# 更新图表布局
fig.update_layout(barmode='group',
xaxis_tickangle=-45,
title='Experiece Level with Employment Type',
font=dict(family="Franklin Gothic", size=17),
template='plotly_dark')
# 显示图形
fig.show()
每一个go.bar怎么看:name设置组的名称,x设置类别的名称,y设置处在这两个分类变量下的值为多少。
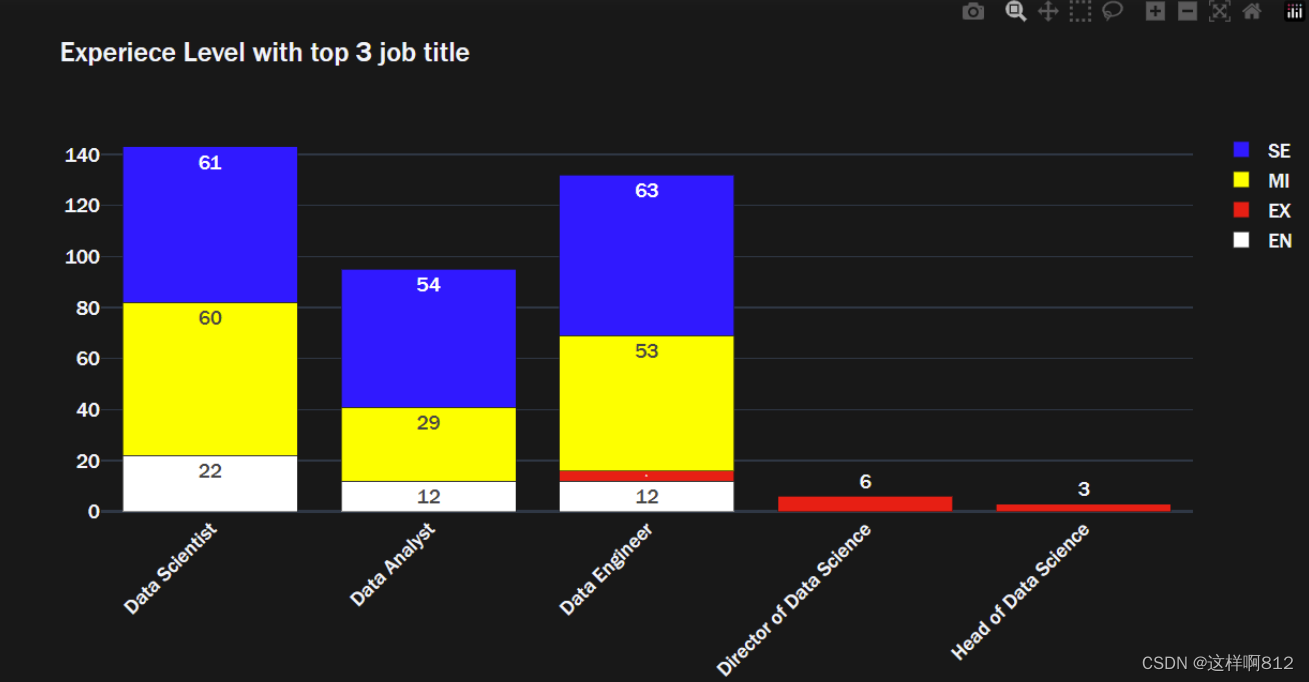
堆叠条形图
# 表示不同经验水平下top3的雇佣类型的相对比例
import plotly.graph_objects as go
# 使用groupby函数,将数据按照经验级别('experience_level')和职位('job_title')进行分组,并计算每个组的数量。
exlevel_job = data.groupby(['experience_level','job_title']).size()
# 从每个级别中选择前三个最常见的职位,分别存储在entry_top3(入门级)、executive_top3(高管级)、mid_top3(中级)和senior_top3(高级)变量中。
entry_top3 = exlevel_job['EN'].sort_values(ascending=False)[:3]
executive_top3 = exlevel_job['EX'].sort_values(ascending=False)[:3]
mid_top3 = exlevel_job['MI'].sort_values(ascending=False)[:3]
senior_top3 = exlevel_job['SE'].sort_values(ascending=False)[:3]
fig = go.Figure(data=[
go.Bar(name='EN', x=entry_top3.index, y=entry_top3.values,
text=entry_top3.values, marker_color='white'),
go.Bar(name='EX', x=executive_top3.index, y=executive_top3.values,
text=executive_top3.values, marker_color='red'),
go.Bar(name='MI', x=mid_top3.index, y=mid_top3.values,
text=mid_top3.values, marker_color='yellow'),
go.Bar(name='SE', x=senior_top3.index, y=senior_top3.values,
text=senior_top3.values, marker_color='blue'),
])
fig.update_layout(barmode = 'stack', # barmode='stack' 绘制堆叠条形图
xaxis_tickangle=-45,
title='Experiece Level with top 3 job title',
font = dict(family="Franklin Gothic", size=15),
template='plotly_dark')
fig.show()
# 这个图形的目的是展示不同经验级别(experience level)与前三个最常见职位(job title)之间的关系。图形中的每个条形表示一个经验级别和职位的组合
# 通过这个图形,您可以快速了解每个经验级别中哪些职位最为常见,并且可以进行比较。这有助于识别不同经验级别下的主要职位趋势。
结语
在本文中,我们深入研究了Matplotlib、Seaborn和Plotly,并重点介绍了使用Plotly绘制水平、垂直、分组和堆叠条形图的技巧。这三个强大的Python可视化工具为数据科学家和分析师提供了丰富的选择。
通过学习这些技术,读者将能够更灵活地呈现数据,利用Plotly的交互性使观众更深入地理解数据。数据可视化的学习旅程中,Matplotlib、Seaborn和Plotly的综合应用将为您的工作提供更多创造性和表现力。希望这些技能能够在您的数据探索中发挥作用,让信息更直观地传达给观众。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









