








🔥博客主页:是dream
🚀系列专栏:深度学习环境搭建、环境配置问题解决、自然语言处理、语音信号处理、项目开发
💘每日语录:你要做冲出的黑马🐎 而不是坠落的星星。
🎉感谢大家点赞👍收藏⭐指正✍️
题目:
对中文文本进行分词操作,并打印出词频出现最高的前5个词。
前期准备:
1、pycharm
2、停用单词表(评论666获取“中文停用词表”)
3、中文文本
以下是中文文本的内容: '速览 \ 网传"日本政府计划用约700亿日元处理涉及排污的‘负面信息’”“日本拒绝他国对核污水直接取样”等说法属实。日本为应对有关福岛第一核电站排放核污染水所谓的"虚假信息",将为此申请逾700亿日元(约合35亿人民币)的2024财政年度预算。\ 据韩媒报道,"日本排放核污染水"这一过程的安全性存在争议,但自2021年日本政府正式决定向大海排放核污染水以来,日本一直反对韩国等相关国家"直接取样"分析放射性物质的浓度变化,并在排海后也坚持这一立场。\ 8月24日,中国海关总署已发布关于全面暂停进口日本水产品的公告,港澳地区也于当日开始禁止源自东京、福岛等10(都)县的水产品进口。\ 事件背景\ 2023年8月24日,日本政府无视各界反对声音,强行启动福岛第一核电站核污水排海,核污水通过海底管道,在距离海岸1公里处的排污口流入太平洋。\ 8月28日,"澎湃明查"后台收到读者提问:日本政府是否计划用约700亿日元处理涉及排污的所谓"负面信息",且拒绝他国对核污水直接取样?'
中文分词
import jieba
from collections import Counter
# 读取停用词表
stopwords_file = 'D:\\my_homework\\NLP_homework\\stop_words\\cn_stopwords.txt'
with open(stopwords_file, 'r', encoding='utf-8') as f:
stopwords = set([line.strip() for line in f.readlines()])
# 读取文本文件内容并删除换行符
input_file = 'news.txt'
with open(input_file, 'r', encoding='utf-8') as f:
text = f.read().replace('\n', '')
# 使用jieba分词
words = jieba.cut(text)
# 统计词频,排除停用词
word_freq = Counter()
for word in words:
word = word.strip() # 去除前导空格
if word and word not in stopwords: # 检查是否为空字符
word_freq[word] += 1
# 获取词频最高的前五个词
top_words = word_freq.most_common(5)
# 打印输出结果
for word, freq in top_words:
print(f'{word}: {freq}')
输出结果
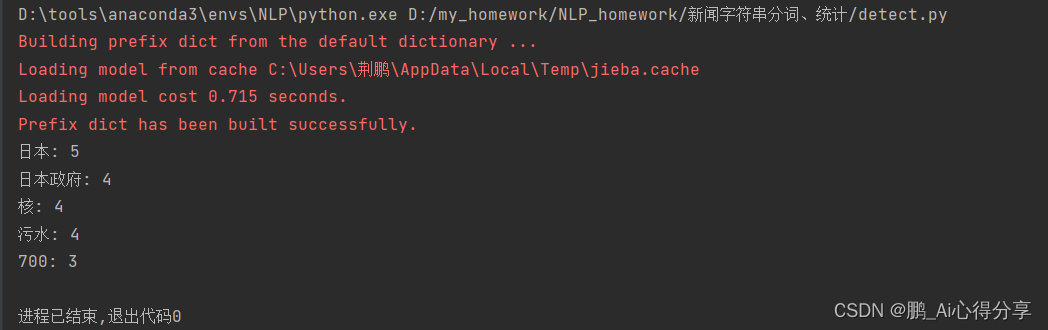
简单的图形化UI界面实现
import tkinter as tk
from tkinter import ttk, filedialog
import jieba
from collections import Counter
# 默认的停用词表文件路径和默认的词频数量
default_stopwords_file = 'D:\\my_homework\\NLP_homework\\stop_words\\cn_stopwords.txt'
default_top_words = 5 # 默认显示词频最高的5个词汇
# 创建一个函数来处理文本
def process_text():
# 使用文件选择对话框获取用户选择的文件路径
file_path = filedialog.askopenfilename()
stopwords_file = stopwords_entry.get() # 获取停用词表文件路径
top_words = int(top_words_entry.get()) # 获取词频数量
try:
# 读取文本文件内容并删除换行符
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read().replace('\n', '')
# 读取停用词表内容
with open(stopwords_file, 'r', encoding='utf-8') as f:
stopwords = set([line.strip() for line in f.readlines()])
# 使用jieba分词
words = jieba.cut(text)
# 统计词频,排除停用词
word_freq = Counter()
for word in words:
word = word.strip() # 去除前导空格
if word and word not in stopwords: # 检查是否为空字符
word_freq[word] += 1
# 获取词频最高的词汇
top_words = word_freq.most_common(top_words)
# 在滚动文本框中显示结果
result_text.config(state='normal') # 允许编辑文本框
result_text.delete('1.0', tk.END) # 清空文本框
for word, freq in top_words:
result_text.insert(tk.END, f'{word}: {freq}\n') # 将结果插入文本框
result_text.config(state='disabled') # 禁止编辑文本框
status_label.config(text="处理完成") # 更新状态栏
except Exception as e:
result_text.config(state='normal') # 允许编辑文本框
result_text.delete('1.0', tk.END) # 清空文本框
result_text.insert(tk.END, f'Error: {str(e)}') # 显示错误信息
result_text.config(state='disabled') # 禁止编辑文本框
status_label.config(text="处理出错") # 更新状态栏
# 创建主窗口
window = tk.Tk()
window.title("文本处理程序")
# 创建样式
style = ttk.Style()
style.configure('TButton', padding=6)
style.configure('TLabel', padding=6)
# 创建按钮
start_button = ttk.Button(window, text="开始处理文本", command=process_text)
start_button.pack(pady=5)
# 创建文本框用于显示结果
result_frame = ttk.Frame(window)
result_frame.pack()
result_text = tk.Text(result_frame, height=10, width=50)
result_text.pack(side="left", fill="both", expand=True)
scrollbar = tk.Scrollbar(result_frame, command=result_text.yview)
scrollbar.pack(side="right", fill="y")
result_text.config(yscrollcommand=scrollbar.set)
result_text.config(state='disabled') # 初始状态禁止编辑
# 添加停用词表文件路径输入框和选择按钮
stopwords_label = ttk.Label(window, text="停用词表文件路径:")
stopwords_label.pack(pady=5)
stopwords_entry = ttk.Entry(window, width=50)
stopwords_entry.insert(0, default_stopwords_file) # 设置默认停用词表文件路径
stopwords_entry.pack()
stopwords_select_button = ttk.Button(window, text="选择停用词表文件", command=lambda: select_stopwords_file())
stopwords_select_button.pack()
# 创建一个函数来选择停用词表文件
def select_stopwords_file():
stopwords_file = filedialog.askopenfilename()
stopwords_entry.delete(0, tk.END)
stopwords_entry.insert(0, stopwords_file)
# 添加词频数量输入框和标签
top_words_label = ttk.Label(window, text="显示词频最高的词汇数量:")
top_words_label.pack(pady=5)
top_words_entry = ttk.Entry(window, width=10)
top_words_entry.insert(0, default_top_words) # 设置默认词频数量
top_words_entry.pack()
# 创建状态栏
status_label = ttk.Label(window, text="", anchor="e")
status_label.pack(side="bottom", fill="x", pady=5)
# 启动主循环
window.mainloop()
在这个UI界面中,可以根据自己的需求选择不同的“中文停用词表”以及要进行分词处理的文件,还可以更改输出中文词的数目。


















 2084
2084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











