






1 知识图谱的介绍
知识图谱,是结构化的语义知识库,用于迅速描述物理世界中的概念及其相互关系,通过知识图谱能够将Web上的信息、数据以及链接关系聚集为知识,使信息资源更易于计算、理解以及评价,并能实现知识的快速响应和推理。
1.1知识图谱的应用
当下知识图谱已在工业领域得到了广泛应用,如搜索领域的Google搜索、百度搜索,社交领域的领英经济图谱,企业信息领域的天眼查企业图谱,电商领域的淘宝商品图谱,O2O领域的美团知识大脑,医疗领域的丁香园知识图谱,以及工业制造业知识图谱等。
 1.2知识图谱构建分类
1.2知识图谱构建分类
识图谱的构建技术主要有自顶向下和自底向上两种。
- 自顶向下构建:借助百科类网站等结构化数据源,从高质量数据中提取本体和模式信息,加入到知识库里。
- 自底向上构建:借助一定的技术手段,从公开采集的数据中提取出资源模式,选择其中置信度较高的信息,加入到知识库中。

1.3 “实体-关系-实体”三元组
下图是典型的知识图谱样例示意图。可以看到,“图谱”中有很多节点,如果两个节点之间存在关系,他们就会被一条无向边连接在一起,这个节点我们称为实体(Entity),节点之间的这条边,我们称为关系(Relationship)。
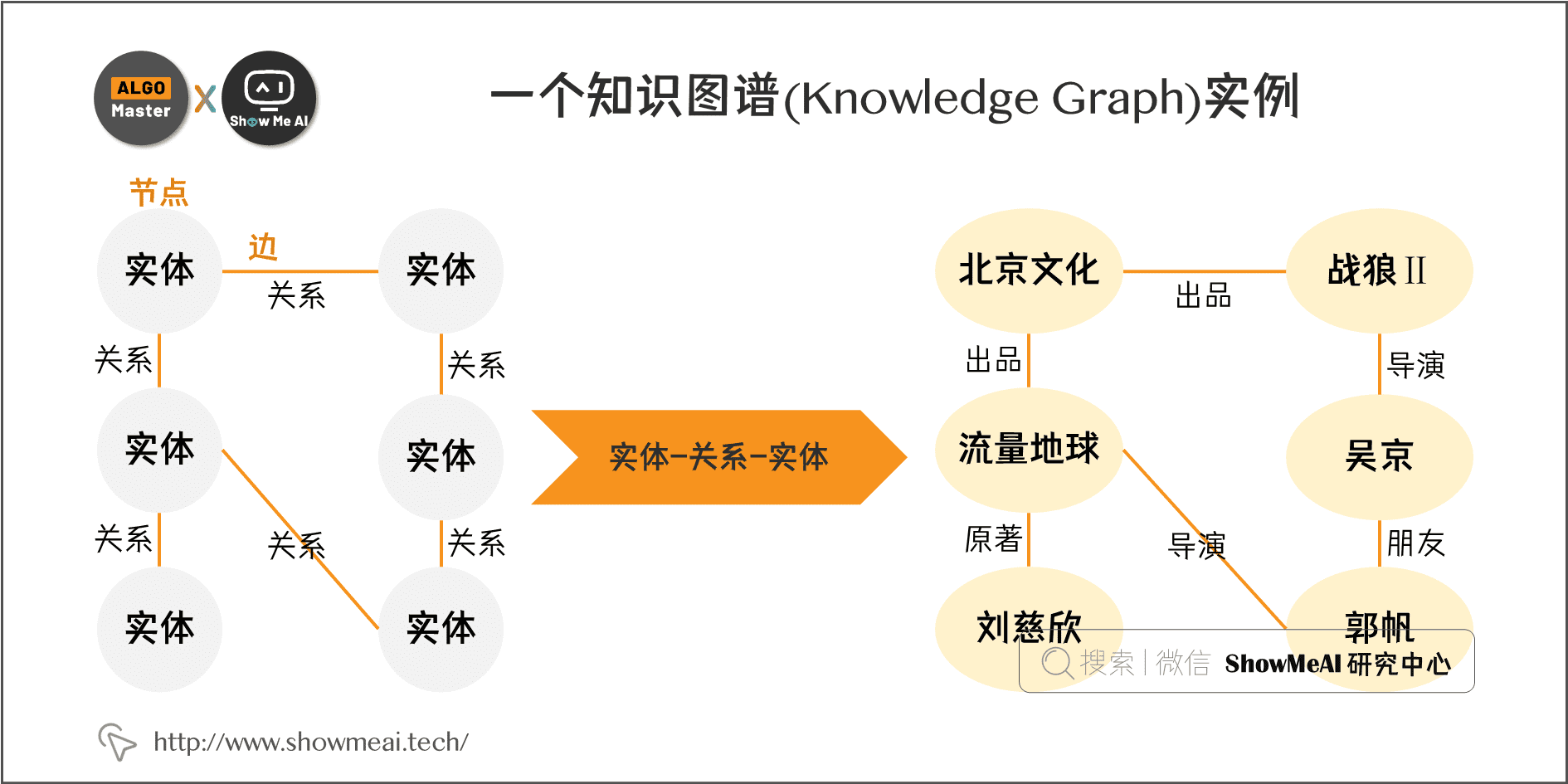
知识图谱的基本单位,就是“实体(Entity)-关系(Relationship)-实体(Entity)” 构成的三元组,这也是知识图谱的核心。
二、数据类型和存储方式
知识图谱的原始数据类型一般来说有三类(也是互联网上的三类原始数据):
- 结构化数据(Structed Data),如:关系数据库、链接数据
- 半结构化数据(Semi-Structured Data),如:XML、JSON、百科
- 非结构化数据(Unstructured Data),如:图片、音频、视频
 典型的半结构化数据样例如下:
典型的半结构化数据样例如下:

如何存储上面这三类数据类型呢?
两种选择:
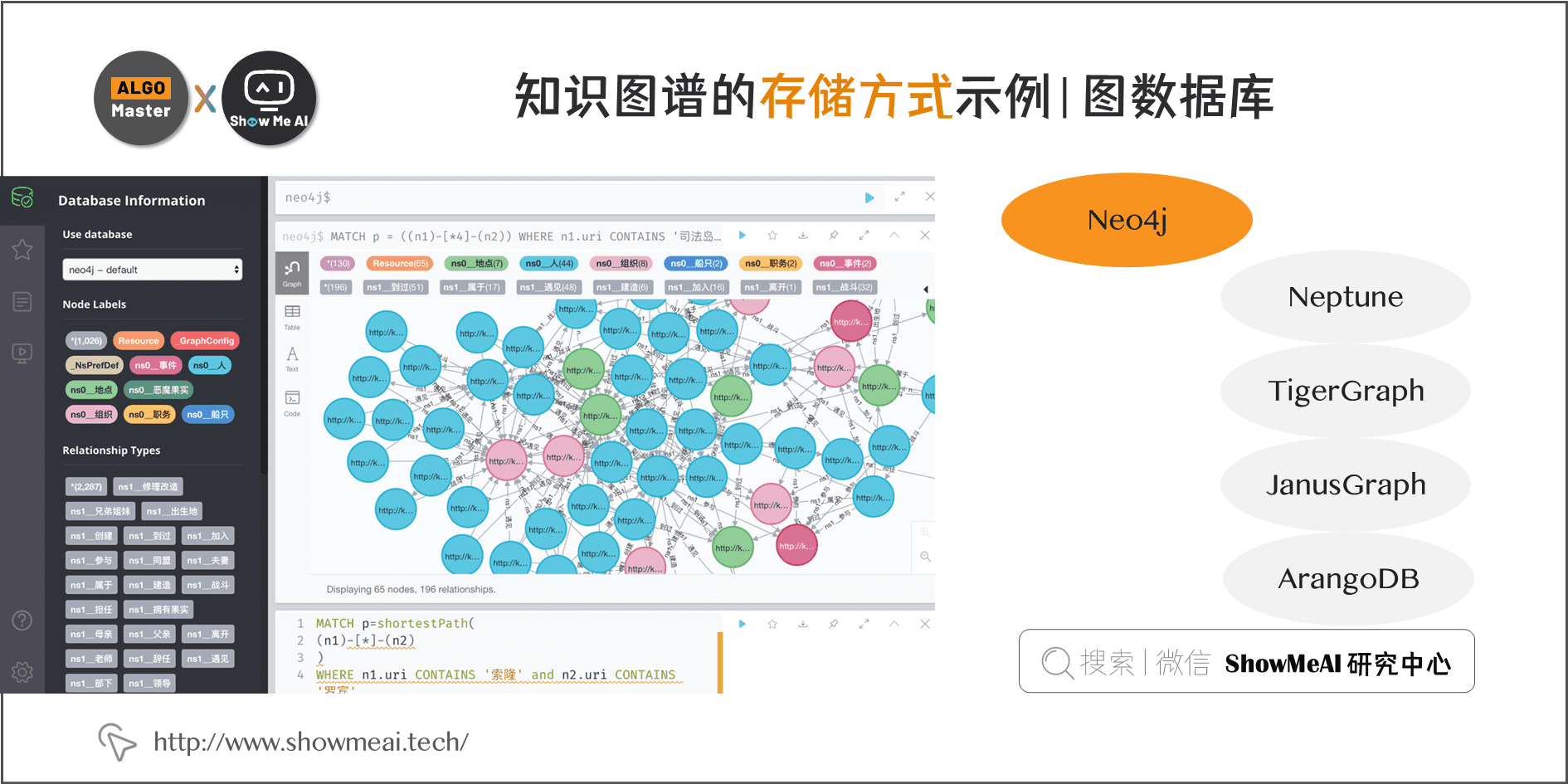
可以通过 RDF(资源描述框架)这样的规范存储格式来进行存储,比较常用的有 Jena等。
另一种方法是使用 图数据库来进行存储,常用的有 Neo4j等。
注意:
截止目前为止,看起来知识图谱主要是一堆三元组,那用关系数据库来存储可以吗?
对,从技术上来说,用关系数据库来存储知识图谱(尤其是简单结构的知识图谱),是完全没问题的。但一旦知识图谱变复杂,用传统的「关系数据存储」,查询效率会显著低于「图数据库」。在一些涉及到2,3度的关联查询场景,图数据库能把查询效率提升几千倍甚至几百万倍。
而且基于图的存储在设计上会非常灵活,一般只需要局部的改动即可。当你的场景数据规模较大的时候,建议直接用图数据库来进行存储。
三、知识图谱的架构
知识图谱的架构主要可以被分为:
- 逻辑架构
- 技术架构
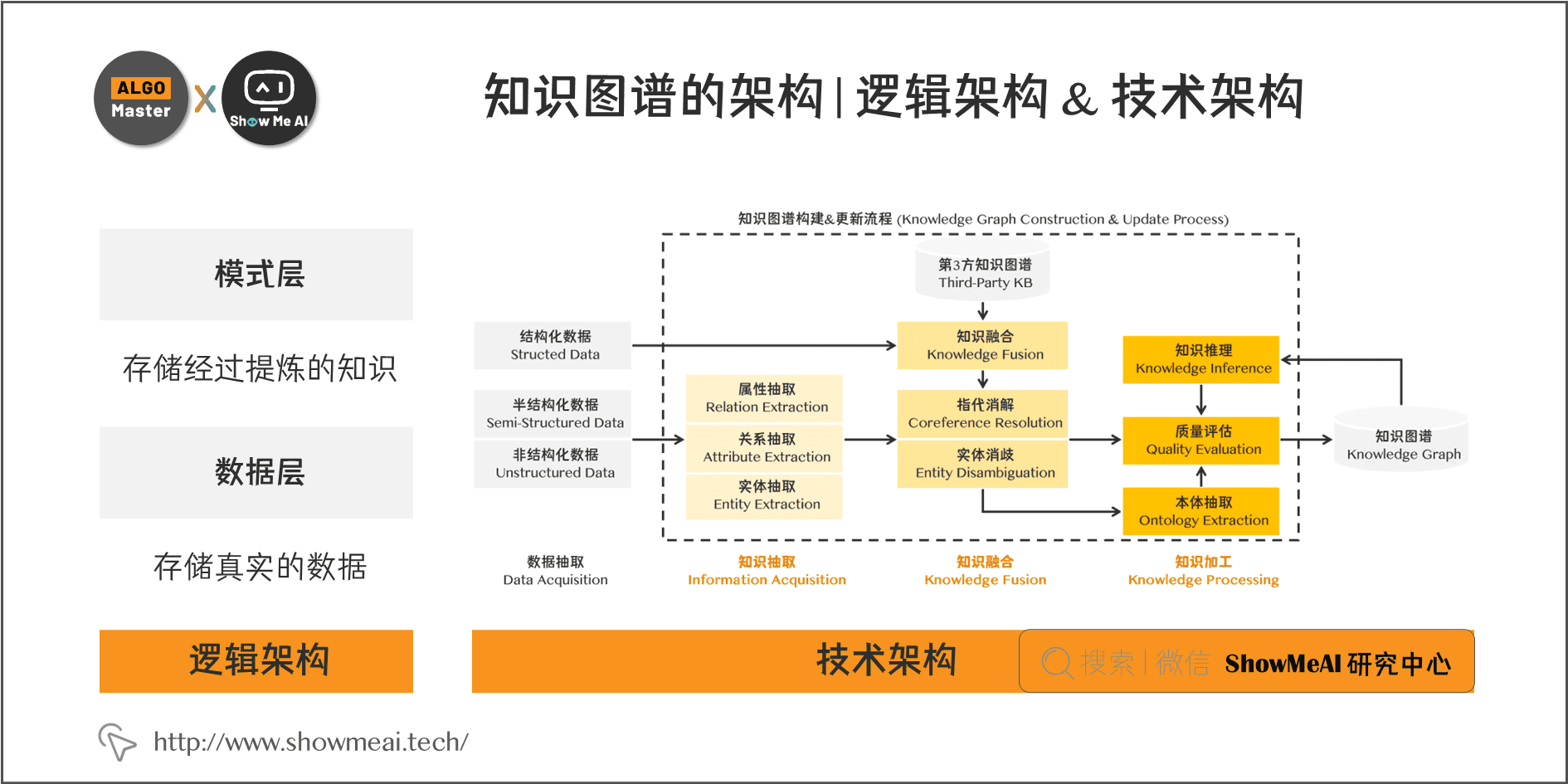
3.1 逻辑架构
在逻辑上,我们通常将知识图谱划分为两个层次:数据层和模式层。
- 模式层:在数据层之上,是知识图谱的核心,存储经过提炼的知识,通常通过本体库来管理这一层(本体库可以理解为面向对象里的“类”这样一个概念,本体库就储存着知识图谱的类)。
- 数据层:存储真实的数据。
可以看看这个例子:
- 模式层: 实体-关系-实体,实体-属性-性值
- 数据层:吴京-妻子-谢楠,吴京-导演-战狼Ⅱ
3.2 技术架构
知识图谱的整体架构如图所示,其中虚线框内的部分为知识图谱的构建过程,同时也是知识图谱更新的过程。别紧张,让我们顺着这张图来理一下思路。
- 首先,我们有一大堆的数据,这些数据可能是结构化的、非结构化的以及半结构化的;
- 然后,我们基于这些数据来构建知识图谱,这一步主要是通过一系列自动化或半自动化的技术手段,来从原始数据中提取出知识要素,即一堆实体关系,并将其存入我们的知识库的模式层和数据层。
四、构建技术
前面的内容说到了,知识图谱有自顶向下和自底向上两种构建方式,这里提到的构建技术主要是自底向上的构建技术。
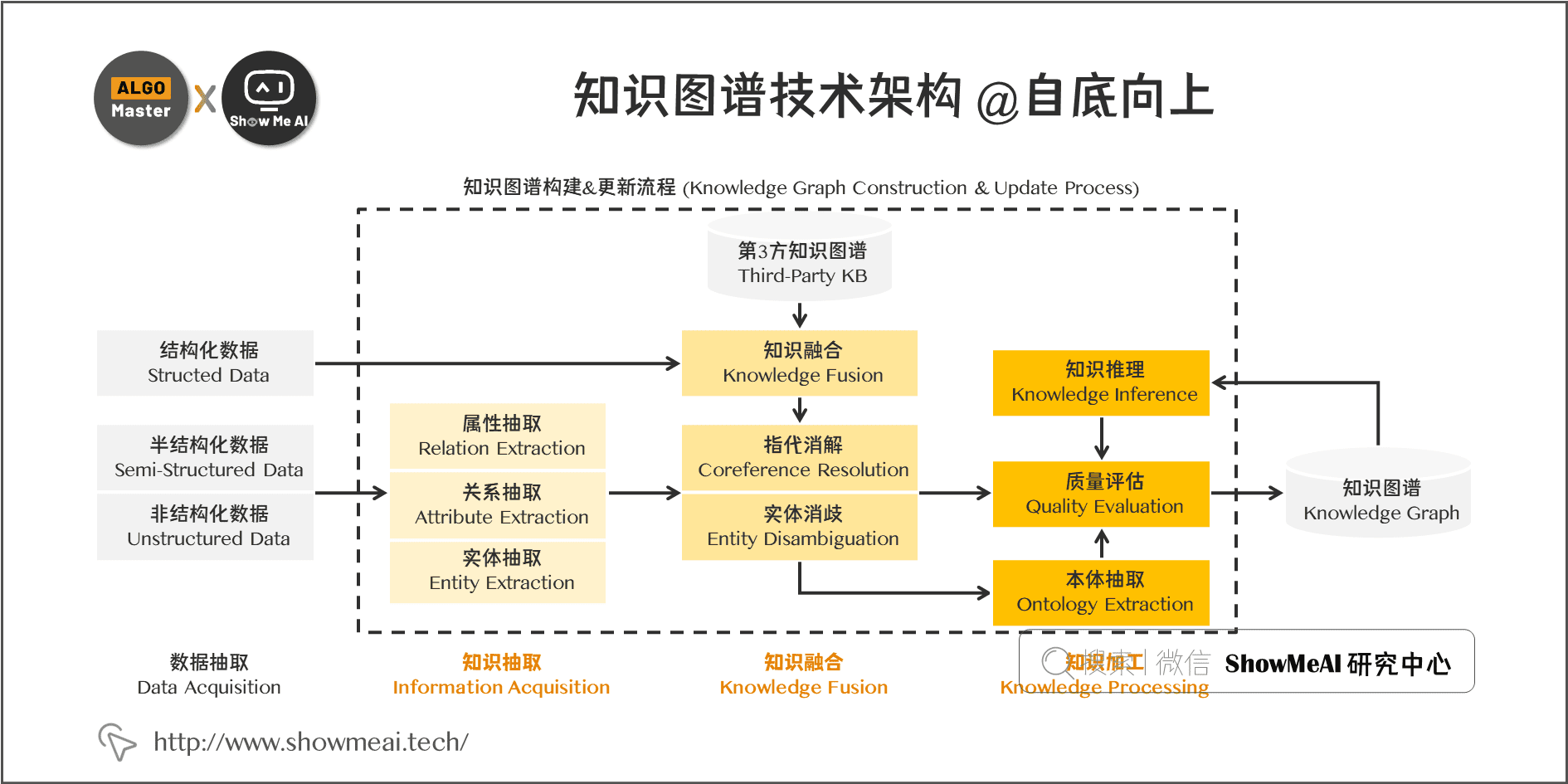
如前所述,构建知识图谱是一个迭代更新的过程,根据知识获取的逻辑,每一轮迭代包含三个阶段:
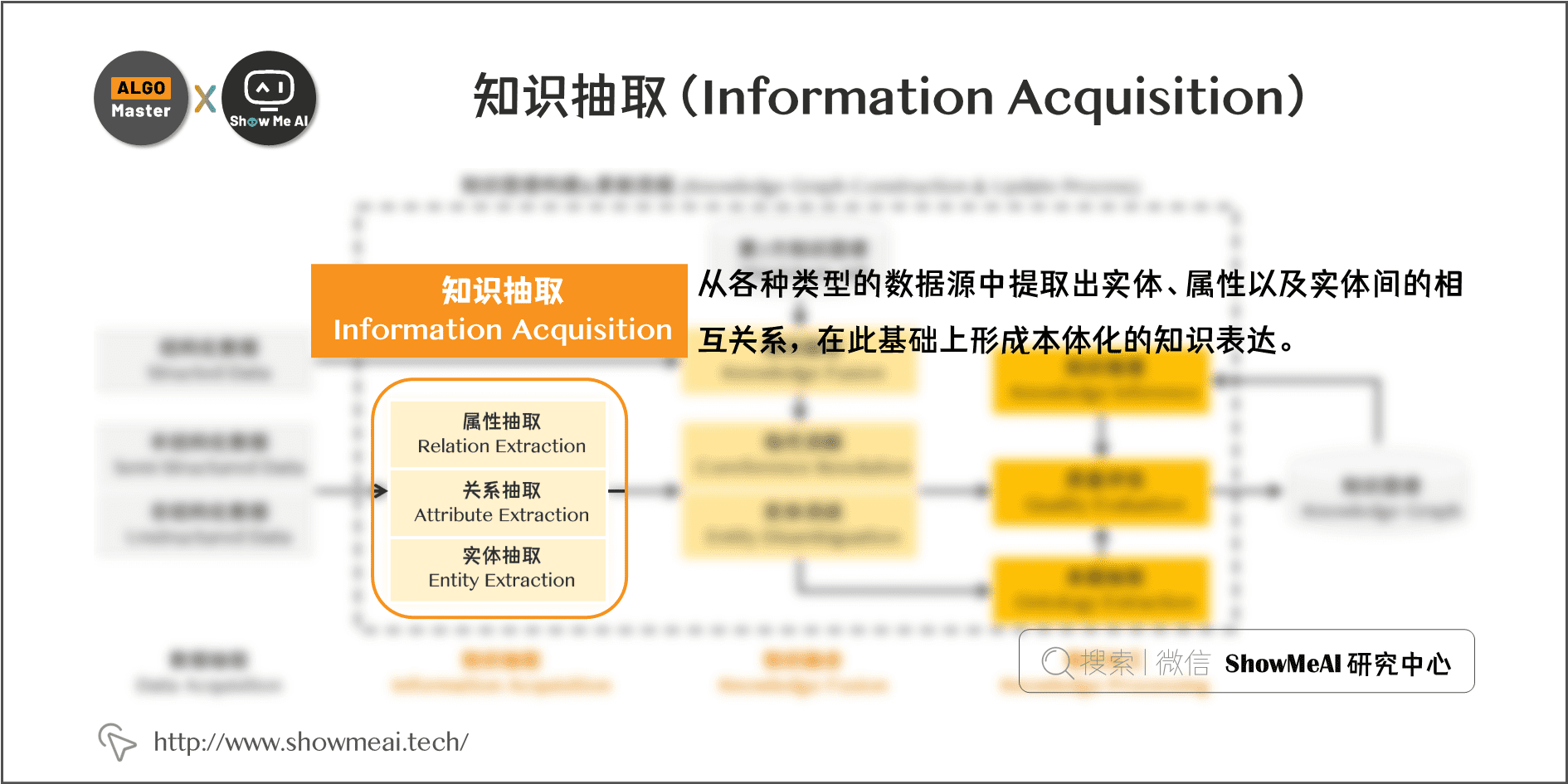
- 信息抽取:从各种类型的数据源中提取出实体、属性以及实体间的相互关系,在此基础上形成本体化的知识表达。
- 知识融合:在获得新知识之后,需要对其进行整合,以消除矛盾和歧义,比如某些实体可能有多种表达,某个特定称谓也许对应于多个不同的实体等。
- 知识加工:对于经过融合的新知识,需要经过质量评估之后(部分需要人工参与甄别),才能将合格的部分加入到知识库中,以确保知识库的质量。
4.1 知识抽取
知识抽取(infromation extraction)是知识图谱构建的第1步,其中的关键问题是:如何从异构数据源中自动抽取信息得到候选指示单元?
信息抽取是一种自动化地从半结构化和无结构数据中抽取实体、关系以及实体属性等结构化信息的技术。涉及的关键技术包括:实体抽取、关系抽取和属性抽取。
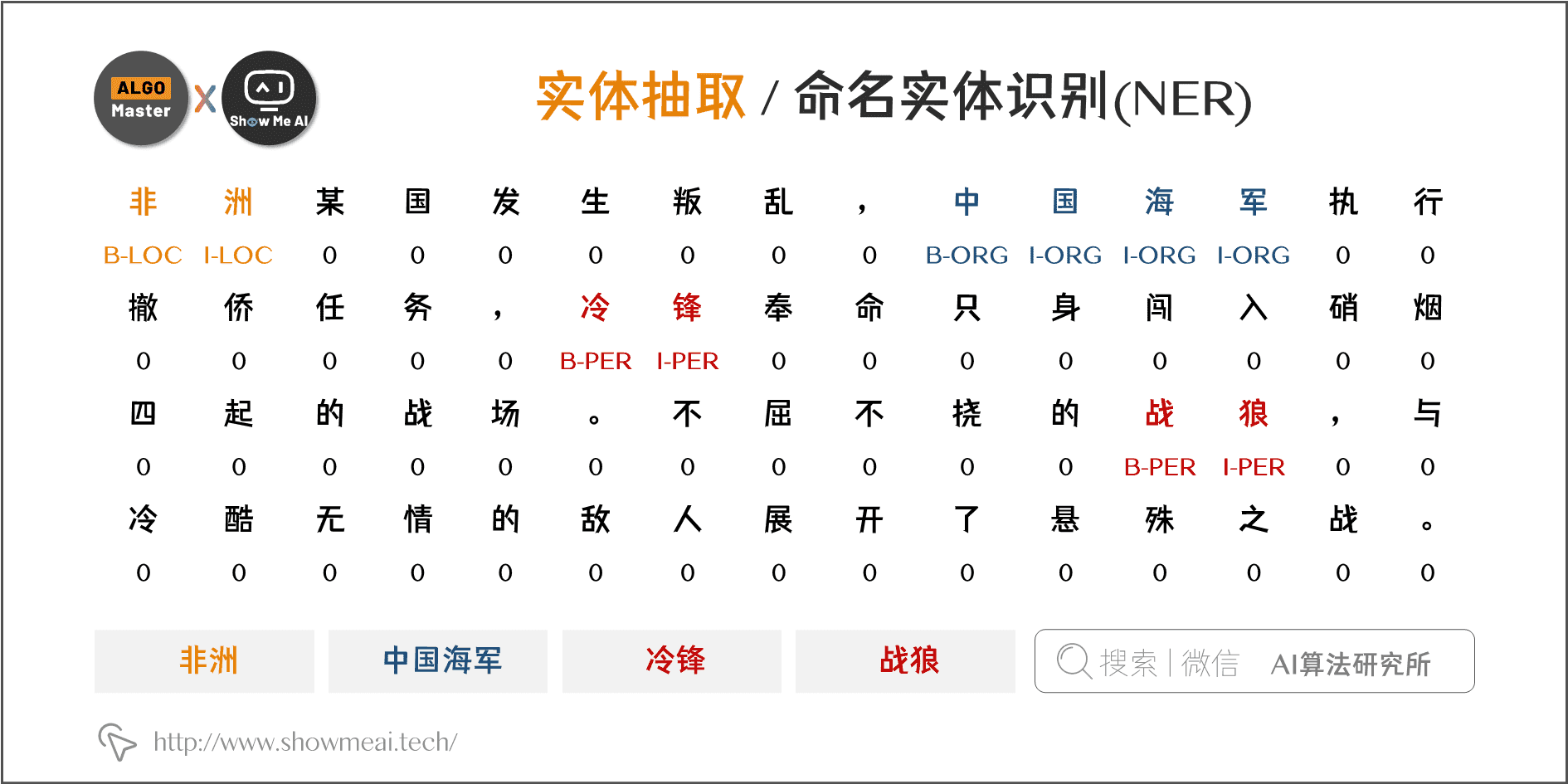
(1)实体抽取
实体抽取,也称为命名实体识别(named entity recognition,NER),是指从文本数据集中自动识别出命名实体。
图中,通过实体抽取我们可以从其中抽取出四个实体:“非洲”、“中国海军”、“冷锋”、“战狼”。
(2)关系抽取
文本语料经过实体抽取之后,得到的是一系列离散的命名实体。为了得到语义信息,还需要从相关语料中提取出实体之间的关联关系,通过关系将实体联系起来,才能够形成网状的知识结构。这就是关系抽取需要做的事,如下图所示。

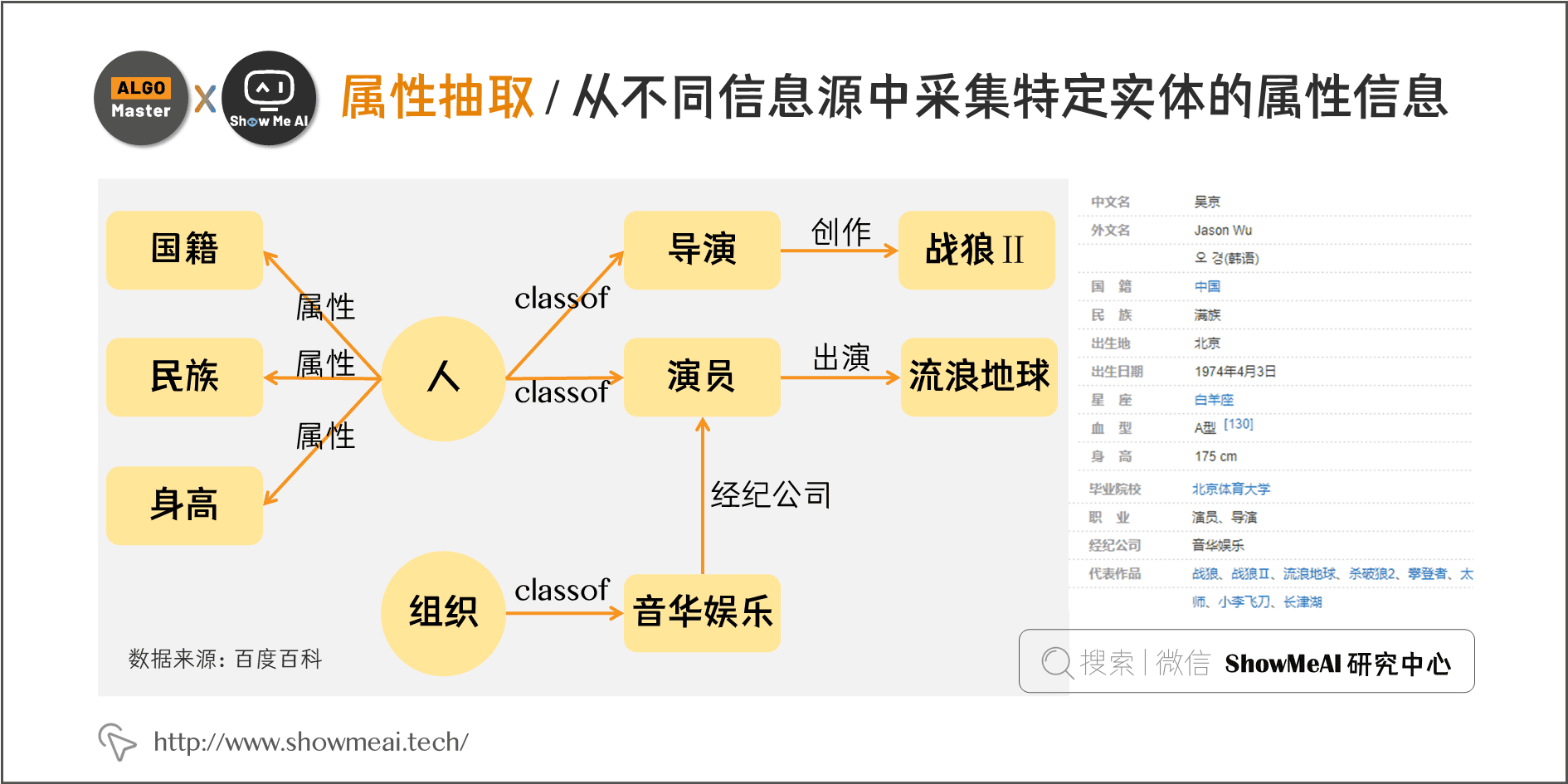
(3)属性抽取
属性抽取的目标是从不同信息源中采集特定实体的属性信息,如针对某个公众人物,可以从网络公开信息中得到其昵称、生日、国籍、教育背景等信息。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











