






css提取数据
提取数据方法有很多,今天就来看看css如何提取数据
一、了解网页代码格式
想用css选择器提取数据,首先得了解网页html数据结构,如图

可以清楚的知道网页数据的布局,而相信有很多人看过相关资料,知道有父子标签,兄弟标签,爷孙标签等,下面先来讲一讲标签之间的的关系。
二、标签之间的关系
1.引入库
代码如下(示例):
"""
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p>css标签选择器的介绍</p>
<p>标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
父子标签:顾名思义,父亲底下就是儿子,如上方代码中
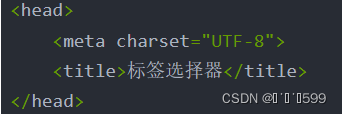
head标签与meta和title标签均为父子标签
兄弟标签:meta和title为兄弟标签
主要理解这两个就可以了,至于爷孙标签,不过是在儿子下还有标签。
最简单的判断级别方法,看缩进,同级别缩进相同。
三.css选择器
1.了解解析对象,导入相关模块
想要用css,xpath解析数据,数据必须是网页类型数据,而re则是解析文本数据类型的。
所以,在提取出文本数据的情况下,想要用css来解析,就必须格式转化。
import parsel # 第三方模块, pip install parsel 封装了css选择器, xpath, 正则
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p>css标签选择器的介绍</p>
<p>标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
selector = parsel.Selector(html) #转换数据对象, 对象才具有数据解析方法
# 根据语法解析<提取>数据, 得到的结果是一个列表, 列表里面是对象
# get() extract_first() 从selector对象里面提取第一个数据, 返回字符串类型
# getall() extract() 从selector对象里面提取所有数据, 返回列表类型
2.标签选择器
尖括号中第一个,例如html、span、p、div、a、img等等
import parsel
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p>css标签选择器的介绍</p>
<p>标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
selector = parsel.Selector(html)
# span 标签选择器, 直接给标签的名字
result = selector.css('span').extract_first() # 获取符合要求的第一个数据
print(result)
result2 = selector.css('span').extract() # 获取符合要求的所有数据,返回一个列表
print(result2)
3.类选择器
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID选择器</p>
<a class="top" href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
# 只要标签具有 class 类属性, 就可以使用类选择器进行定位
# . 提取标签的类属性<值>
# 如果多个标签有相同的类属性的值, 那么会全部提取到
# 类选择器就是通过标签的类属性 (class属性), 精确定位到想要的标签
result = selector.css('.top').getall()
print(result)
4.id选择器
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top" id="contend">css标签选择器的介绍</p>
<p class="top" id="contend">标签选择器、类选择器、ID选择器</p>
<a class="top" href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
# id 一般在html数据中是唯一的
# '#' 使用id选择器定位标签
# 具有相同的id属性的比起爱你都会被提取
# contend 指得是id属性值
result = selector.css('#contend').getall()
print(result)
5.组合选择器
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top" id="contend">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID选择器</p>
<a class="top" href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
# 组合选择器使用, 标签选择器放最前, 其他选择器随表放
result = selector.css('p.top#contend').getall() # 加了约束
print(result)
result = selector.css('.topp#contend').getall() # 不能这样写
print(result)
6.伪类选择器
可以用 : 指定选择想要提取的第几个标签。
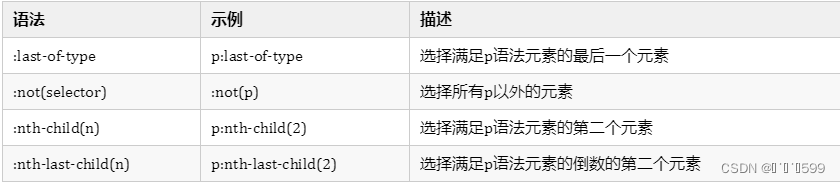
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top" id="content">css标签选择器的介绍</p>
<p class="top" id="content">标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
p = selector.css('p:nth-child(2)').getall() # 提取第二个p标签
print(p)
7.属性提取器
可以用 :: 提取标签包含的属性。
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top1" id="contend">css标签选择器的介绍</p>
<p class="top2">标签选择器、类选择器、ID选择器</p>
<a class="top" href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel # 第三方模块, pip install parsel 封装了css选择器, xpath, 正则
selector = parsel.Selector(html)
# :: 表示属性提取器, 当我们定位到标签以后想要去标签包含的文本内容或者某个属性值吗就需要使用属性提取器
# text 表示取标签包含的文本
p = selector.css('p::text').getall()
print(p)
# ::attr(class) 表示提取标签下的属性对应的值
# class 是属性名, 是根目属性名字取值的
p = selector.css('p::attr(class)').getall()
print(p)
#获取<a class="top" href="https://www.baidu.com">百度一下</a>里面的url
href = selector.css('a::attr(href)').getall() # 因为此处只有一个,我就用get(),而没有用getall(),否则会返回一个列表
print(href)
总结
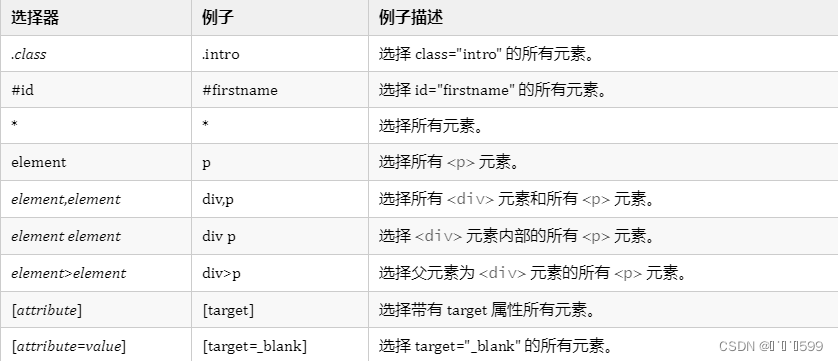
这里附上相关简便用法,有条件的来个双击么么哒。
了解更多点击一起讨论呐~
















 3394
3394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











