






前言
讲过了css提取器,大家应该对提取数据有一定了解了,今天就来讲解第二种提取数据方法——xpath提取
一、什么是xpath
XPath(XML Path Language) 是一门在 HTML\XML 文档中查找信息的语言,可用来在 HTML\XML 文档中对元素和属性进行遍历
二、xpath节点关系

点击此处开辟新世界了解更多相关内容。

二.语法
1.语法
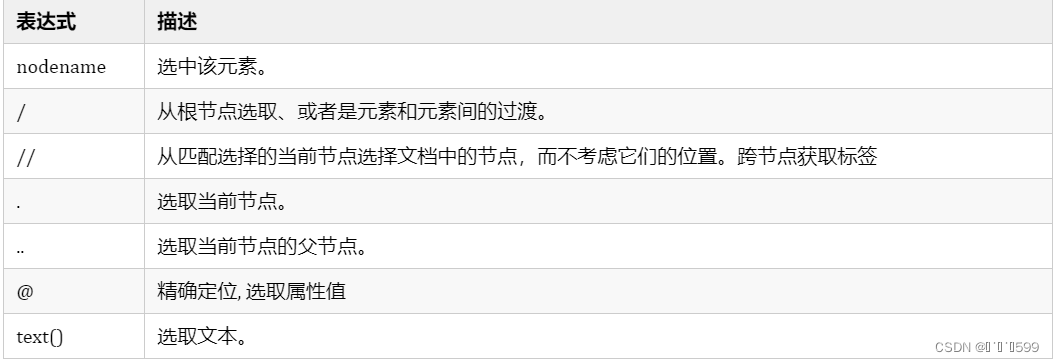

2.案例
import parsel # str --> Selector对象 具有xpath方法 提取到的数据返回一个列表
html_str = """
<div>
<ul>
<li class="item-1">
<a href="link1.html">第一个</a>
</li>
<li class="item-2">
<a href="link2.html">第二个</a>
</li>
<li class="item-3">
<a href="link3.html">第三个</a>
</li>
<li class="item-4">
<a href="link4.html">第四个</a>
</li>
<li class="item-5">
<a href="link5.html">第五个</a>
</li>
</ul>
</div>
"""
# 1、转换数据类型
# data = parsel.Selector(html_str).extract() # parsel能够把缺失的html标签补充完成
data = parsel.Selector(html_str) # parsel能够把缺失的html标签补充完成
# 2、解析数据--list类型
# print(data)
# 2、1 从根节点开始,获取所有<a>标签
result = data.xpath('/html/body/div/ul/li/a').extract()
# 2、2 跨节点获取所有<a>标签
result = data.xpath('//a').extract()
# 2、3 选取当前节点 使用场景:需要对选取的标签的下一级标签进行多次提取
result = data.xpath('//ul')
result2 = result.xpath('./li').extract() # 提取当前节点下的<li>标签
result3 = result.xpath('./li/a').extract() # 提取当前节点下的<a>标签
# 2、4 选取当前节点的父节点,获取父节点的class属性值
result = data.xpath('//a')
result4 = result.xpath('../@class').extract()
# 2、5 获取第三个<li>标签的节点(两种方法)
result = data.xpath('//li[3]').extract()
result = data.xpath('//li')[2].extract()
# 2、6 通过定位属性的方法获取第四个<a>标签
result = data.xpath('//a[@href="link4.html"]').extract()
# 2、7 用属性定位标签,获取第四个<a>标签包裹的文本内容
result = data.xpath('//a[@href="link4.html"]/text()').extract()
# 2、8 获取第五个<a>标签的href属性值
result = data.xpath('//li[5]/a/@href').extract()
# 了解 模糊查询
result = data.xpath('//li[contains(@class,"it")]').extract()
# 同时获取<li>标签的属性以及<a>标签的文本
# result = data.xpath('//li/@class|//a/text()').extract()
print(result)
3.如何选取多个标签?
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。(逻辑运算符)
–
总结
- xpath的概述XPath (XML Path Language),解析查找提取信息的语言
- xpath的节点关系:根节点,子节点,同级节点
- xpath的重点语法获取任意节点:
// - xpath的重点语法根据属性获取节点:
标签[@属性 = '值'] - xpath中获取节点的文本:
text() - xpath的获取节点属性值:
@属性名
















 2122
2122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











