






①线性模型
现在来让我们做一个二分类任务假定在样本空间中可以找到一个超平面把不同类别的样本分开

//横轴是
x
1
x_1
x1,纵轴是
x
2
x_2
x2。
x
1
x_1
x1,
x
2
x_2
x2代表提取到的两个特征
根据观察我们好像可以找到一条直线划分整个区域,现在我们假设已经找到了一条直线:
w
1
x
1
+
w
2
x
2
+
b
=
0
w_1x_1+w_2x_2+b=0
w1x1+w2x2+b=0
对于新的测试数据,如果
w
1
x
1
+
w
2
x
2
+
b
>
0
w_1x_1+w_2x_2+b>0
w1x1+w2x2+b>0,他就属于类别一,反之,如果
w
1
x
1
+
w
2
x
2
+
b
<
0
w_1x_1+w_2x_2+b<0
w1x1+w2x2+b<0,他就属于类别二,那么现在我们就开始来讨论如何找到这么一组参数
(
w
1
,
w
2
,
b
)
(w_1,w_2,b)
(w1,w2,b)
②线性可分
首先我们用数学严格定义训练样本以及他们的标签
假设:我们有N个训练样本和他们的标签
{(X1,y1) , (X2,y2) , … , (XN,yN)}
其中 Xi=[xi1,xi2]T , yi={+1,-1}
当yi等于1时,xi属于1类别,等于-1时,xi属于2类别
所以也就是说有两种情况
(1)y=+1,则w1xi1+w2xi2+b≥0
(2)y=-1,则w1xi1+w2xi2+b<0
**注意:**我们现在讨论的是线性可分得情况(可以用一条直线划分区域)
如果我们向量形式来定义
假设:
X
i
=
[
x
i
1
x
i
2
]
X_i=\begin{bmatrix} x_i1\\ x_i2\\ \end{bmatrix}
Xi=[xi1xi2]
w
i
=
[
w
1
w
2
]
w_i~=\begin{bmatrix} w_1\\ w_2\\ \end{bmatrix}
wi =[w1w2]
(1)若yi=+1,则
w
T
X
i
+
b
≥
0
w^TX_i+b≥0
wTXi+b≥0
(2)若yi=-1,则
w
T
X
i
+
b
<
0
w^TX_i+b<0
wTXi+b<0
又∵在定义中,我们规定yi=+1 or -1
∴我们得到了线性可分定义的最简化形式
y
i
(
w
T
X
i
+
b
)
≥
0
y_i(w^TX_i+b)≥0
yi(wTXi+b)≥0
首先我先给大家介绍一个概念:间隔(Margin)
我们用一条直线不停去试探,向上移动触碰到第一个散点时停止,向下相同,这两条直线之间的距离叫做Margin,触碰到的第一个散点叫支持向量。
而SVM寻找的最优分类直线应满足:
(1)直线可以分开两类。
(2)最大化Margin。
(3)该直线位于Margin的中间,到所有支持向量距离相等。
那么接下来我们就要开始推导一个数学表达式来最大化Margin,并满足限制条件。
首先我们知道点到直线的距离公式是
∣
A
x
+
B
y
+
C
∣
a
2
+
b
2
\frac {|Ax+By+C|}{\sqrt {a^2+b^2}}
a2+b2∣Ax+By+C∣
接下来我们拓展到n维空间,点x=(x1,x2,…,xN)到直线
w
T
X
i
+
b
=
0
w^TX_i+b=0
wTXi+b=0的距离是
d
=
∣
w
T
X
+
b
∣
∣
∣
w
∣
∣
d=\frac {|w^TX+b|}{||w||}
d=∣∣w∣∣∣wTX+b∣
根据Margin的定义,我们可以知道,这里的点x实际上就是支持向量!
我们知道一个事实
w
T
X
i
+
b
=
0
w^TX_i+b=0
wTXi+b=0 与
(
a
w
T
)
X
i
+
(
a
b
)
=
0
(aw^T)X_i+(ab)=0
(awT)Xi+(ab)=0是同一个超平面,也就是说我们可以用a去缩放(w,b)
最终使得在支持向量下满足
∣
w
T
X
+
b
∣
=
1
|w^TX+b|=1
∣wTX+b∣=1
而非支持向量下满足
∣
w
T
X
+
b
∣
>
1
|w^TX+b|>1
∣wTX+b∣>1 (w与b为变换后的,但是超平面不变)
这个时候因为点x是支持向量,那么距离d的分母就会为1则
d
=
1
∣
∣
w
∣
∣
d=\frac {1}{||w||}
d=∣∣w∣∣1
那么最大化Margin的问题变成了 最小化
∣
∣
w
∣
∣
||w||
∣∣w∣∣的问题,实际上我们最小化的目标是
1
2
∣
∣
w
2
∣
∣
\frac {1}{2} ||w^2||
21∣∣w2∣∣,两者是等价的,只不过后者可以在后续中更加方便的求导。
∵我们可以得到
∣
w
T
X
+
b
∣
≥
1
|w^TX+b|≥1
∣wTX+b∣≥1,而yi∈{-1,1},∴我们可以得到
y
i
(
w
T
X
i
+
b
)
≥
1
y_i(w^TX_i+b)≥1
yi(wTXi+b)≥1, (i=1~N)
综上,在线性可分的情况下,SVM寻找最佳超平面的优化问题可以表四为:
最小化:
1
2
∣
∣
w
2
∣
∣
\frac {1}{2} ||w^2||
21∣∣w2∣∣
限制条件:
y
i
(
w
T
X
i
+
b
)
≥
1
y_i(w^TX_i+b)≥1
yi(wTXi+b)≥1 , ( i=1~N)
在这里我们先不继续介绍如何求解,先来看看别的情况,如果训练样本是线性不可分的,我们又该如何求解呢?接下来让我们继续看看
③线性不可分
很显然线性不可分的条件比线性可分的更加严苛,那么我们能否适当的放松限制条件呢。我们尝试对每个训练样本及标签(Xi,Yi)引入松弛变量δi
那么我们再来改写我们的优化问题为:
最小化:
1
2
∣
∣
w
2
∣
∣
+
C
∑
i
=
1
n
δ
i
\frac {1}{2} ||w^2||+C\sum_{i=1}^nδ_i
21∣∣w2∣∣+C∑i=1nδi 或者
1
2
∣
∣
w
2
∣
∣
+
C
∑
i
=
1
n
δ
i
2
\frac {1}{2} ||w^2||+C\sum_{i=1}^nδ_i^2
21∣∣w2∣∣+C∑i=1nδi2
限制条件:(1)
y
i
(
w
T
X
i
+
b
)
≥
1
−
δ
i
y_i(w^TX_i+b)≥1-δ_i
yi(wTXi+b)≥1−δi , ( i=1~N)
(2)
δ
i
≥
0
δ_i≥0
δi≥0,(i=1~N)
这里是C是比例因子,调节两项的比例,实际上这里的C是一个超参数,需要人为设定。
但是仅仅引入一个δi真的能够解决线性不可分问题吗?

在这里我们看到,我们将近分错了一半的散点,这是因为什么呢?
很明显在这里我们使用的仍然是线性模型,无论我们取什么样的直线都无法很好的分开两类。那么我们到底该如何解决呢?
现在我们引入一个异或问题,如图,这也是一个线性不可分的例子

接下来我们构造一个从二维到五维的映射φ(x)
φ(x):
x
=
[
a
b
]
x=\begin{bmatrix} a\\ b\\ \end{bmatrix}
x=[ab] ➡
φ
(
x
)
=
[
a
2
b
2
a
b
a
b
]
φ(x)=\begin{bmatrix} a^2\\ b^2\\ a\\ b\\ ab\\ \end{bmatrix}
φ(x)=⎣⎢⎢⎢⎢⎡a2b2abab⎦⎥⎥⎥⎥⎤
将xi代入φ(x)我们可以得到

这时候我们随便设
w
=
[
−
1
−
1
−
1
−
1
6
]
w=\begin{bmatrix} -1\\ -1\\ -1\\ -1\\ 6\\ \end{bmatrix}
w=⎣⎢⎢⎢⎢⎡−1−1−1−16⎦⎥⎥⎥⎥⎤,
b
=
1
b=1
b=1,接下来我们发现一个神奇的事情

这个式子不就是线性模型吗,我们居然用一个线性模型表达出了线性不可分的情况。
也就是说我们用了一个低维到高维的映射,将线性不可分的数据集变成了线性可分的数据集,接下来我们说一个更一般的结论
假设:在一个M维空间上随机取N个训练样本,随机对每一个训练样本赋予标签+1或-1,这些训练样本线性可分的概率为P(M),则当M趋于无穷大时 P(M)=1
由此之前的操作看起来似乎就有理可循了。
现在我们假设φ(x)已经确定,那么我们的优化问题就可以写成:
最小化:
1
2
∣
∣
w
2
∣
∣
+
C
∑
i
=
1
n
δ
i
\frac {1}{2} ||w^2||+C\sum_{i=1}^nδ_i
21∣∣w2∣∣+C∑i=1nδi 或者
1
2
∣
∣
w
2
∣
∣
+
C
∑
i
=
1
n
δ
i
2
\frac {1}{2} ||w^2||+C\sum_{i=1}^nδ_i^2
21∣∣w2∣∣+C∑i=1nδi2
限制条件:(1)
y
i
(
w
T
φ
(
x
i
)
+
b
)
≥
1
−
δ
i
y_i(w^Tφ(x_i)+b)≥1-δ_i
yi(wTφ(xi)+b)≥1−δi , ( i=1~N)
(2)
δ
i
≥
0
δ_i≥0
δi≥0,(i=1~N)
也就是所有的Xi被φ(xi)替代,在这里要注意这个时候
w
w
w的维度与
φ
(
x
i
)
φ(x_i)
φ(xi)相同!
接下来我们将探究φ(x)的形式,我们引入一个新概念:核函数,
K
(
X
1
,
X
2
)
=
φ
(
X
1
)
T
φ
(
X
2
)
K(X_1,X_2)=φ(X_1)^Tφ(X_2)
K(X1,X2)=φ(X1)Tφ(X2)

那么我们为什么要引入核函数呢,其实我们只要知道核函数,即使不知道φ(x)的具体形式,但是问题仍能求解。
接下来我们先介绍最优化理论中原问题和对偶问题的定义,为后续继续推导做准备。

接下来我们来该原问题的对偶问题,首先我们需要定义一个函数:

在定义了函数
L
(
w
,
α
,
β
)
L(w,α,β)
L(w,α,β)的基础上,对偶问题如下:
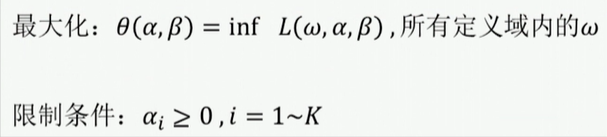
i
n
f
,
L
(
w
,
α
,
β
)
,
所
有
定
义
域
内
的
w
inf , L(w,α,β),所有定义域内的w
inf,L(w,α,β),所有定义域内的w的意思是遍历所有
w
w
w,求最小值
综合原问题与对偶问题的定义得到:
定理1:如果
w
∗
w^*
w∗是原问题的解,
(
α
∗
,
β
∗
)
(α^*,β^*)
(α∗,β∗)是对偶问题的解,则有
f
(
w
∗
)
≥
θ
(
α
∗
,
β
∗
)
f(w^*)≥θ(α^*,β^*)
f(w∗)≥θ(α∗,β∗)
我们把
f
(
w
∗
)
−
θ
(
α
∗
,
β
∗
)
f(w^*)-θ(α^*,β^*)
f(w∗)−θ(α∗,β∗)定义为对偶差距,对偶差距大于等于0。
强对偶定理:若
f
(
w
)
f(w)
f(w)为凸函数,且
g
(
w
)
=
A
w
+
b
g(w)=Aw+b
g(w)=Aw+b,
h
(
w
)
=
C
w
+
d
h(w)=Cw+d
h(w)=Cw+d,则对偶差距为0。即
f
(
w
∗
)
=
θ
(
α
∗
,
β
∗
)
f(w^*)=θ(α^*,β^*)
f(w∗)=θ(α∗,β∗)
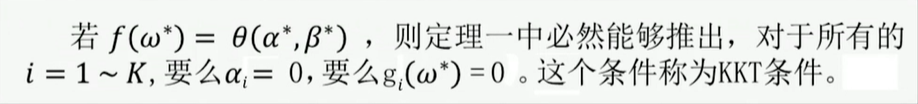
首先我们要证明SVM的原问题满足强队偶原理
首先将
δ
i
≥
0
δ_i≥0
δi≥0,(i=1~N)转换成
δ
i
≤
0
δ_i≤0
δi≤0
得到:最小化:
1
2
∣
∣
w
2
∣
∣
−
C
∑
i
=
1
n
δ
i
\frac {1}{2} ||w^2||-C\sum_{i=1}^nδ_i
21∣∣w2∣∣−C∑i=1nδi
限制条件:(1)
y
i
(
w
T
φ
(
x
i
)
+
b
)
≥
1
+
δ
i
y_i(w^Tφ(x_i)+b)≥1+δ_i
yi(wTφ(xi)+b)≥1+δi , ( i=1~N)
(2)
δ
i
≤
0
δ_i≤0
δi≤0,(i=1~N)
再整理一下:

由此可以发现,恰好满足原问题的形式。
将对偶问题写成如下的形式:

这里的αi,βi相当于原问题定义中的α,并没有β。
对
(
w
,
b
,
δ
i
)
(w,b,δ_i)
(w,b,δi)求导并令导数为0。

经过代入化简,我们可以将支持向量机的原问题化为对偶问题:
最大化:
θ
(
α
)
=
∑
i
=
1
N
α
i
−
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
K
(
X
i
,
X
j
)
θ(α)=\sum_{i=1}^Nα_i-\frac {1}{2}\sum_{i=1}^N\sum_{j=1}^Nα_iα_jy_iy_jK(X_i,X_j)
θ(α)=∑i=1Nαi−21∑i=1N∑j=1NαiαjyiyjK(Xi,Xj)
限制条件:(1)
0
≤
α
i
≤
C
0≤α_i≤C
0≤αi≤C ,(i=1~N)
(2)
∑
i
=
1
N
α
i
y
i
=
0
\sum_{i=1}^Nα_iy_i=0
∑i=1Nαiyi=0
这种凸优化问题可以用SMO算法来解决
④SVM算法流程
1)训练流程:
输入{(xi,yi)},i=1~N
解优化问题:
最大化:
θ
(
α
)
=
∑
i
=
1
N
α
i
−
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
K
(
X
i
,
X
j
)
θ(α)=\sum_{i=1}^Nα_i-\frac {1}{2}\sum_{i=1}^N\sum_{j=1}^Nα_iα_jy_iy_jK(X_i,X_j)
θ(α)=∑i=1Nαi−21∑i=1N∑j=1NαiαjyiyjK(Xi,Xj)
限制条件:(1)
0
≤
α
i
≤
C
0≤α_i≤C
0≤αi≤C ,(i=1~N)
(2)
∑
i
=
1
N
α
i
y
i
=
0
\sum_{i=1}^Nα_iy_i=0
∑i=1Nαiyi=0
算b,取一个0<αi<C,
b
=
1
−
y
i
∑
j
=
1
N
α
j
y
j
K
(
X
i
X
j
)
y
i
b=\frac {1-y_i\sum_{j=1}^Nα_jy_jK(X_iX_j)}{y_i}
b=yi1−yi∑j=1NαjyjK(XiXj)
2)测试流程
输入测试样本X
若
∑
i
=
1
N
α
i
y
i
K
(
x
i
,
x
)
+
b
≥
0
\sum_{i=1}^Nα_iy_iK(x_i,x)+b≥0
∑i=1NαiyiK(xi,x)+b≥0,则
y
=
+
1
y=+1
y=+1
若
∑
i
=
1
N
α
i
y
i
K
(
x
i
,
x
)
+
b
<
0
\sum_{i=1}^Nα_iy_iK(x_i,x)+b<0
∑i=1NαiyiK(xi,x)+b<0,则
y
=
−
1
y=-1
y=−1
⑤SVM内核总结
线性内核:
K
(
x
,
y
)
=
x
T
y
K(x,y)=x^Ty
K(x,y)=xTy
多项式核:
K
(
x
,
y
)
=
(
x
T
y
+
1
)
d
K(x,y)=(x^Ty+1)^d
K(x,y)=(xTy+1)d
高斯核:
K
(
x
,
y
)
=
e
−
∣
∣
x
−
y
∣
∣
2
σ
2
K(x,y)=e^-\frac{||x-y||^2}{σ^2}
K(x,y)=e−σ2∣∣x−y∣∣2
Tanh核:
K
(
x
,
y
)
=
t
a
n
h
(
β
x
T
y
+
b
)
K(x,y)=tanh(βx^Ty+b)
K(x,y)=tanh(βxTy+b)
//此文只用作个人学习记录















 26万+
26万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









