







目录
🚩前言
上篇博客我们讲到了进程地址空间 👉[传送门],大致了解了进程地址的一些特点。但实际上我们作为用户,对于地址空间只要有个大概的认知就足够了,我们会更加关心怎样去控制进程,来完成一些我们想要的操作。因此这篇博客我们就从进程控制的四大方面来学习:进程创建、进程终止、进程等待、进程程序替换。
🚩进程创建
对于用户来说,想要手动一点点的创建进程显然是不可能的。创建进程是操作系统的工作,过程极其复杂,首先要创建大量内核数据结构对象和数据,接着是完成他们的初始化,并把部分或全部数据加载到内存中去,之后建立映射关系(虚拟进程地址的创建),最后完成进程的结构拼装。
所以为了满足用户想要自己创建进程的需求,Linux中提供了fork()函数来创建子进程。
fork函数做了什么
fork函数在被调用后,操作系统会通过fork来使用父进程的结构数据,环境变量以及代码生成一个全新的子进程,并且子进程也拥有fork函数,这就会导致子进程的fork也有返回值。而由于子进程和父进程拥有一套虚拟地址空间,在读取fork函数的返回值时会访问同一虚拟地址,但对应访问了两个物理空间,这就导致fork函数返回值有两个值。事实上,父进程fork函数返回的是子进程的pid,子进程的forl函数返回的是0。

子进程从何处运行
既然子进程和父进程拥有一样的代码,那能不能从又开始运行呢?
答案是不可以!
子进程是从fork函数之后开始运行的。
代码测试
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
printf("进程开始!\n");
pid_t id=fork();
if(id==0)//子进程
{
while(1)
{
printf("子进程:pid:%d, ppid:%d\n",getpid(),getppid());
sleep(1);
}
}
else if(id>0) //父进程
{
while(1)
{
printf("父进程:pid:%d, ppid:%d\n",getpid(),getppid());
sleep(1);
}
}
else
{
//进程创建失败
}
return 0;
}
测试结果

可以看出进程开始语句只执行了一次,说明子进程确实是从fork之后开始执行的。
🔺原因:父进程在运行的时候,cpu中有一个变量eip叫做程序计数器,保存着正在执行命令的下一个指令,而子进程是在fork函数之后被创建的。因此,子进程在被调度的时候,同样是从fork函数之后开始运行。
写时拷贝的优点
我们在进程地址空间就已经了解到写时拷贝是在调用fork函数的时候,进行写入操作才会有的一种现象。
如果刚调用fork函数就一股脑地把数据全部拷贝到子进程中进去,浪费空间不说,还会影响fork的效率。而采用写时拷贝虽然拷贝的代价依然有,但不至于那么浪费空间和时间,并且空出来的内存空间可以给别的进程使用,也相当于变相的提高了内存利用率和效率。
同样的,进程之间的独立性也是通过写时拷贝实现的。
🚩进程终止
常见进程终止
我们知道有main函数的return 0,而除了return之外,还有exit和_exit两种退出方式(exit本身就表示退出的意思)。
我们无论使用上面的哪一种方式退出进程,都会有一个要求,那就是要有退出码!比如return 0中的0就是退出码,使用exit和_exit时,也要传退出码:exit(退出码)、_exit(退出码)
接下来我们就来谈一谈退出码。
进程退出码
在谈退出码之前,我先说一下进程终止的3种情况:
1.代码跑完,正常结束,运行结果正确
2.代码跑完,正常结束,运行结果不正确
3.代码没跑完,异常结束。(一般是用户干涉,中途杀掉进程)
进程只有在正常结束之后才会给出退出码,异常结束只会给出退出信号(下面再说)。退出码所传递的信息实际上就是进程是怎样样跑完的。用户可以使用库里写定的退出信息,也可以自己制定一套退出码对应的退出信息。
Linux中部分退出码:
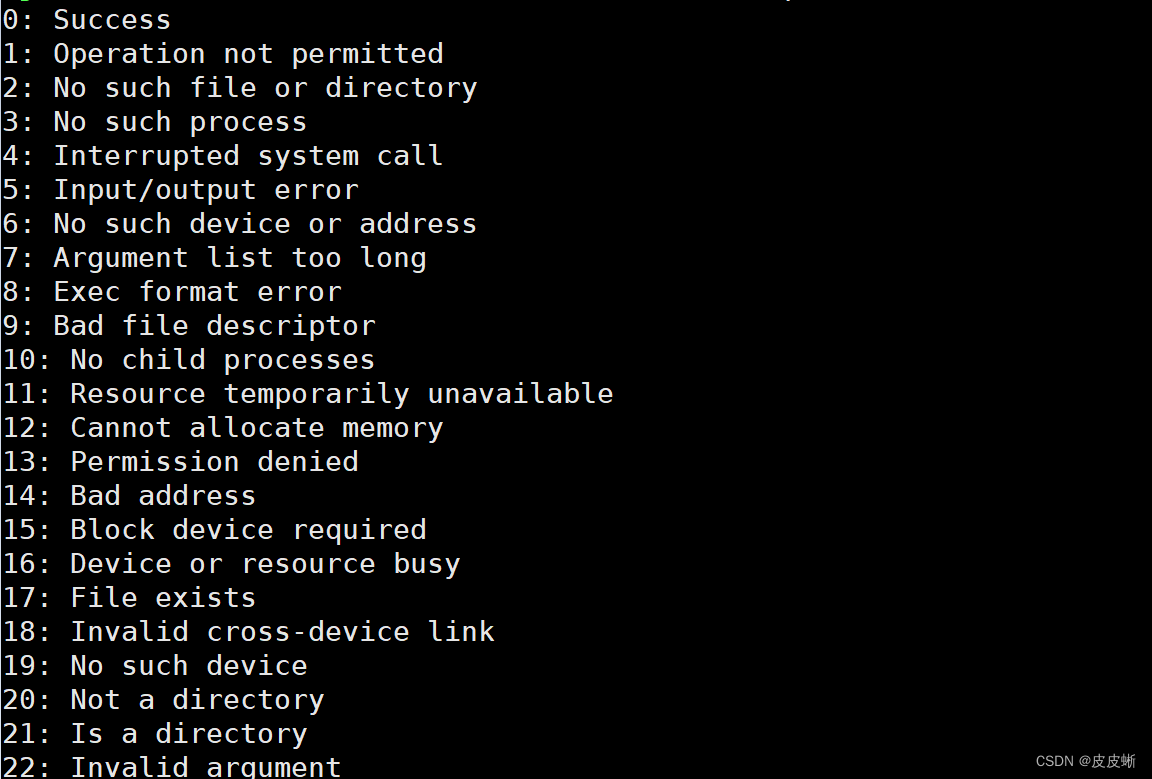
退出码查看:echo $?
echo $?是查看上一个进程的退出码。
代码测试
#include<stdio.h>
#include<stdlib.h>
int main()
{
printf("进程开始!\n");
exit(123);
}测试结果

第一次查看的确实是上一个进程的退出码,第二次查看的就是上一个echo $?进程的退出码了。
exit与_exit
两者都是退出进程的操作,不同于return,它们可以在代码的任意位置执行!不过有一点不同,_exit不会刷新缓冲区和关闭流。
进程结束os做了什么
进程=内核数据结构(task_struct mm_struct page_table)+ 代码和数据
一般情况下,操作系统会将代码和数据释放掉,但对于内核数据结构并不会进行释放,而是把内核数据结构放在一个死亡队列里面,而这个队列是在内核的数据结构缓冲池中,通过slab分派器给有需要的进程使用(比如新进程的创建)。
🚩进程等待
阻塞等待
进程能运行就一定能暂停,这在逻辑上是成立的。然而平常我们在写代码的时候很少碰见进程一直在等待的情况,原因在于很少碰到运行条件不满足的条件。不过也不是没有,比如我们打开输入流的时候(C++是cin C语言是scanf),只要我们没完成输入操作,进程就一直在等待用户。输入操作完成之后,满足了运行条件进程才会继续。
上述情况属于阻塞等待(一直卡在一个地方等待),与之伴随概念的还有非阻塞等待。
非阻塞等待
在有些情况下,进程虽然没有接收到自己需要的数据,但是并不妨碍它之后的运行。但我们可以进行循环检测,直到等待成功。在此期间,该进程可以一直做自己想要做的事情。这种操作叫做轮询检测!
我们后面会对阻塞等待和非阻塞等待进行模拟。
进程等待的原因
除了数据输入的情况下进程需要等待,当涉及到父子进程的时候,也会涉及到进程等待。比如子进程退出了,处于Z状态,这时父进程要了解子进程进行的运行结果,并且父进程可以选择性的进行阻塞等待和非阻塞等待。拿到信息之后,父进程就回收掉子进程,处理掉僵尸进程。
从上述描述中不难看出,进程等待至少有两种功能:
1.获取子进程退出状态(非必须)
2.释放僵尸状态的子进程(不是唯一方式)
因此,进程等待在某些情况下是可以很好的解决僵尸进程的处理难题。毕竟僵尸进程已经属于死掉的进程了,就不能通过kill命令杀死了。
怎样控制进程等待
用户要想实现进程等待控制,可以调用wait和waitpid两个函数来实现。在函数调用的地方进程会根据用户的选择来进行阻塞等待或非阻塞等待。具体的情况我们下面来分析一下。
waitpid与wait
我们通过man手册进行查看
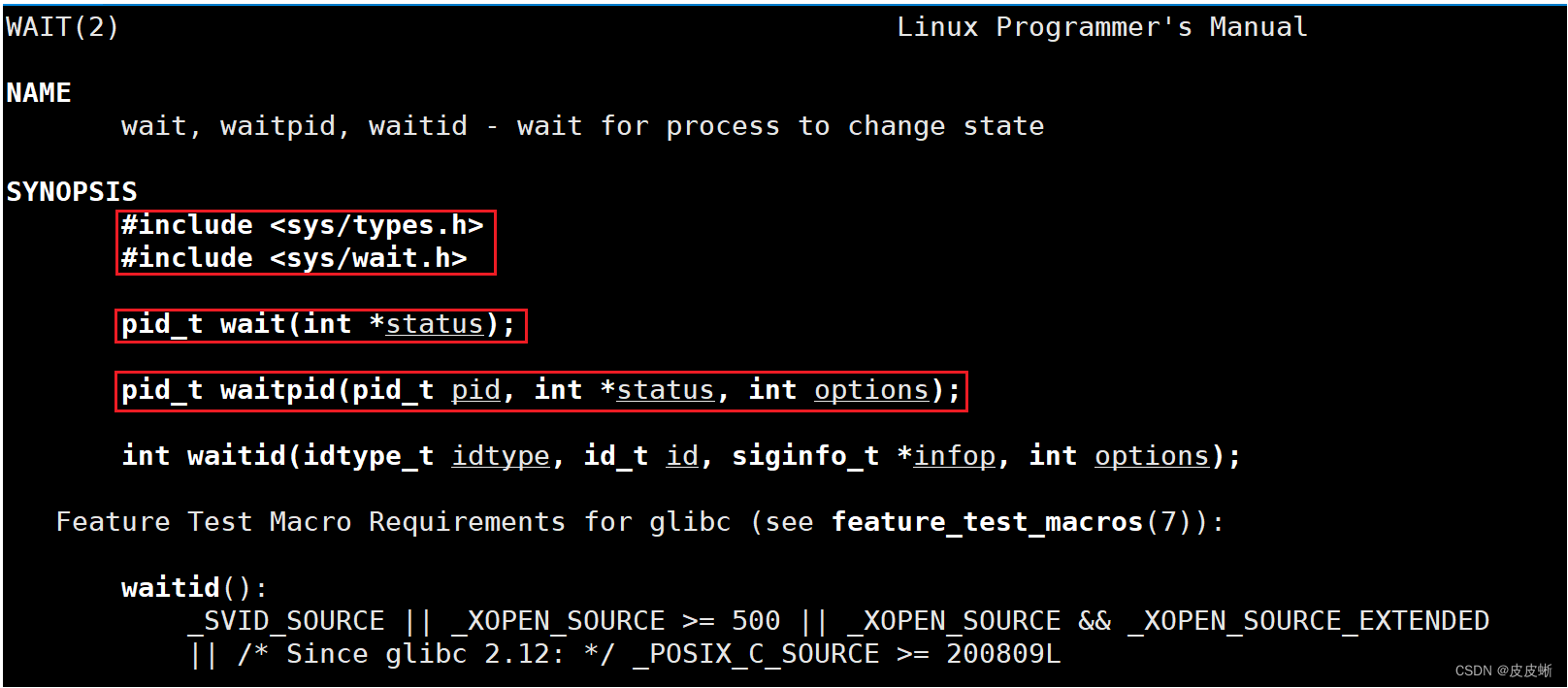
可以发现两者的参数略有不同。实际上,waitpid同样能实现wait的功能,因此这里我们就只展开对waitpid的探索。
waitpid的参数:
pid:指定等待子进程的pid,传-1时等待任意子进程,此时等价于wait。(函数属于系统调用,因此拿到子进程的pid很正常)
options:默认传0,表示阻塞等待(等待子进程的结束,属于软件等待,与进程阻塞态相关)。而传WNOHANG(Linux下的宏定义)表示是非阻塞等待。
status:输出型参数,调用时从函数内部拿出来特定的数据。也就是通过操作系统,从子进程的task_struct中拿到子进程的退出码(子进程的其他信息也可以通过这种方式提取)。不关心退出状态就传NULL。wait函数同样如此。
waitpid的返回值:
返回值>0:等待子进程成功,返回值就是子进程的pid
返回值==0:正在等待子进程退出
返回值<0:等待子进程失败。
参数中的status保留着进程退出的信息。指针指向一个整形空间(4字节),但实际上,信息只保留在低16bit位上(32位操作系统)。次低8bit位保存着退出状态(退出码),低7bit位保存着退出信号。至于第8bit位是啥,我们现在用不到,就不展开讨论了。
具体看下图:
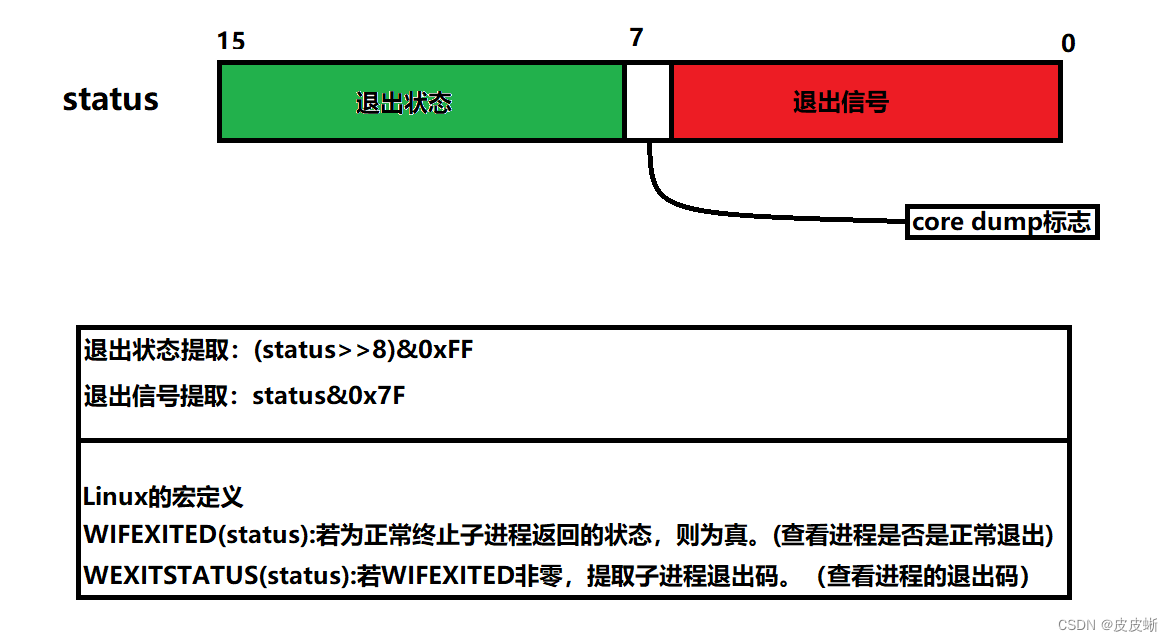
话不多说,我们直接上代码赶紧测试一下看看!
阻塞测试
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<stdlib.h>
int main()
{
printf("进程开始!\n");
pid_t id=fork();
if(id==0)//子进程
{
int cnt=3;
while(1)
{
if(!cnt)
{
exit(46);//退出码用户写为46
}
printf("子进程:pid:%d, ppid:%d, %dseconds left\n",getpid(),getppid(),cnt--);
sleep(1);
}
}
else if(id>0) //父进程
{
int status;
printf("父进程:pid:%d, ppid:%d\n",getpid(),getppid());
sleep(5);
pid_t ret=waitpid(-1,&status,0);//阻塞等待
//两种获取方式
if(ret>0)
{
printf("等待进程pid:%d, status:%d, sign:%d\n",ret,(status>>8)&0xFF,status&0x7F);
}
else
{
printf("等待失败\n");
}
if(WIFEXITED(status))
{
printf("等待进程pid:%d, status:%d\n",ret,WEXITSTATUS(status));
}
else
{
printf("等待失败\n");
}
sleep(2);
}
else
{
//进程创建失败
}
return 0;
}
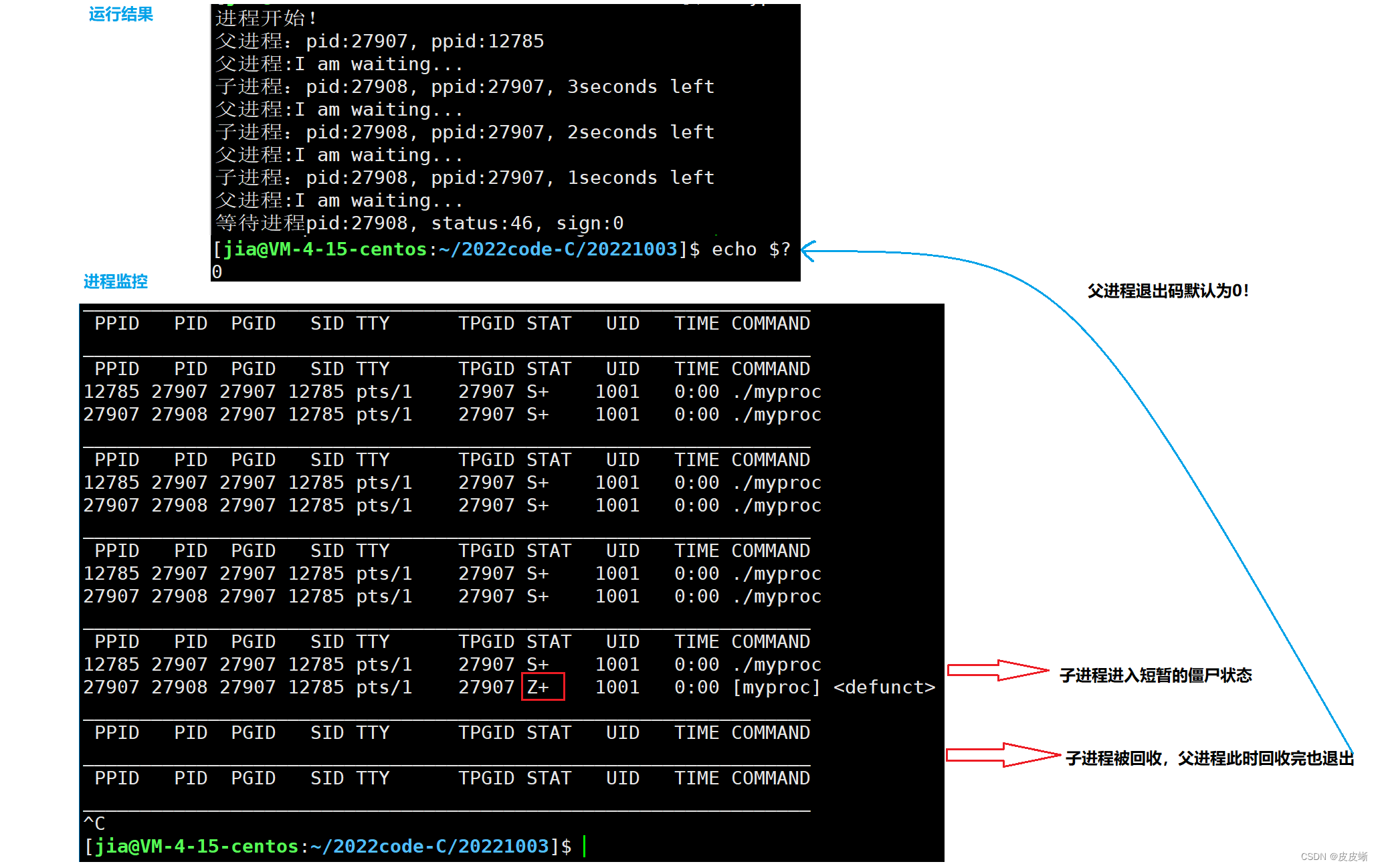
上面的代码表示子进程3秒之后退出,退出码为46,而父进程会等5秒再进行阻塞等待,这也就意味着子进程会有2秒钟的时间处于Z状态,2秒之后子进程被回收,父进程再等2秒结束。
测试结果
while :; do ps ajx | head -1 && ps ajx | grep myproc | grep -v grep; echo "________________________________________________________________"; sleep 1; done
监控进程的小脚本

上面的代码中的父进程等了5秒才执行阻塞等待,是为了观查子进程的僵尸状态。如果不等话父进程也会一直卡在waitpid函数那里,因为我们调用的是阻塞等待。有兴趣的小伙伴自己可以动手试一试。
非阻塞测试
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<stdlib.h>
int main()
{
printf("进程开始!\n");
pid_t id=fork();
if(id==0)//子进程
{
int cnt=3;
while(1)
{
if(!cnt)
{
exit(46);
}
printf("子进程:pid:%d, ppid:%d, %dseconds left\n",getpid(),getppid(),cnt--);
sleep(1);
}
}
else if(id>0) //父进程
{
int status;
printf("父进程:pid:%d, ppid:%d\n",getpid(),getppid());
while(1)//轮询检测
{
pid_t ret=waitpid(-1,&status,WNOHANG);//非阻塞等待
if(ret>0)
{
printf("等待进程pid:%d, status:%d, sign:%d\n",ret,(status>>8)&0xFF,status&0x7F);
break;//等待成功,跳出循环
}
else if(ret==0)//还在等待,但父进程可以做自己的事情
{
printf("父进程:I am waiting...\n");
sleep(1);
}
else
{
printf("等待失败\n");
}
}
}
else
{
//进程创建失败
}
return 0;
}
测试结果
进程异常退出测试
假如子进程是被用户杀死的,那么退出状态就没了,就只剩退出信号了。
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<stdlib.h>
int main()
{
printf("进程开始!\n");
pid_t id=fork();
if(id==0)//子进程
{
while(1)
{
printf("子进程:pid:%d, ppid:%d\n",getpid(),getppid());
sleep(1);
}
}
else if(id>0) //父进程
{
int status;
printf("父进程:pid:%d, ppid:%d\n",getpid(),getppid());
while(1)
{
pid_t ret=waitpid(-1,&status,WNOHANG);//非阻塞等待
if(ret>0)
{
printf("等待进程pid:%d, status:%d, sign:%d\n",ret,(status>>8)&0xFF,status&0x7F);
break;
}
else if(ret==0)
{
printf("父进程:I am waiting...\n");
sleep(1);
}
else
{
printf("等待失败\n");
}
}
}
else
{
//进程创建失败
}
return 0;
}
测试结果

异常退出时退出信号能反映进程到底是怎样退出的。
🚩进程程序替换
进程替换的概念
所谓进程替换,就是将一个进程换成另一个进程的操作。旧进程的用户空间代码和数据完全被新程序替换。
为什么要进行进程替换
有些时候我们创建子进程,并不只是为了让它执行父进程代码的片段,更是想要它执行在磁盘中的某些可执行文件,而且使用的编程语言和父进程可能与不一样,如果不进行程序替换,不同的编程语言根本不可能在同一编译器下同时编译。但是进行程序替换后,由于是直接完全替换,运行的是可执行文件,就不存在编译的过程了,此时就使得父进程和替换同时运行了。
程序替换原理
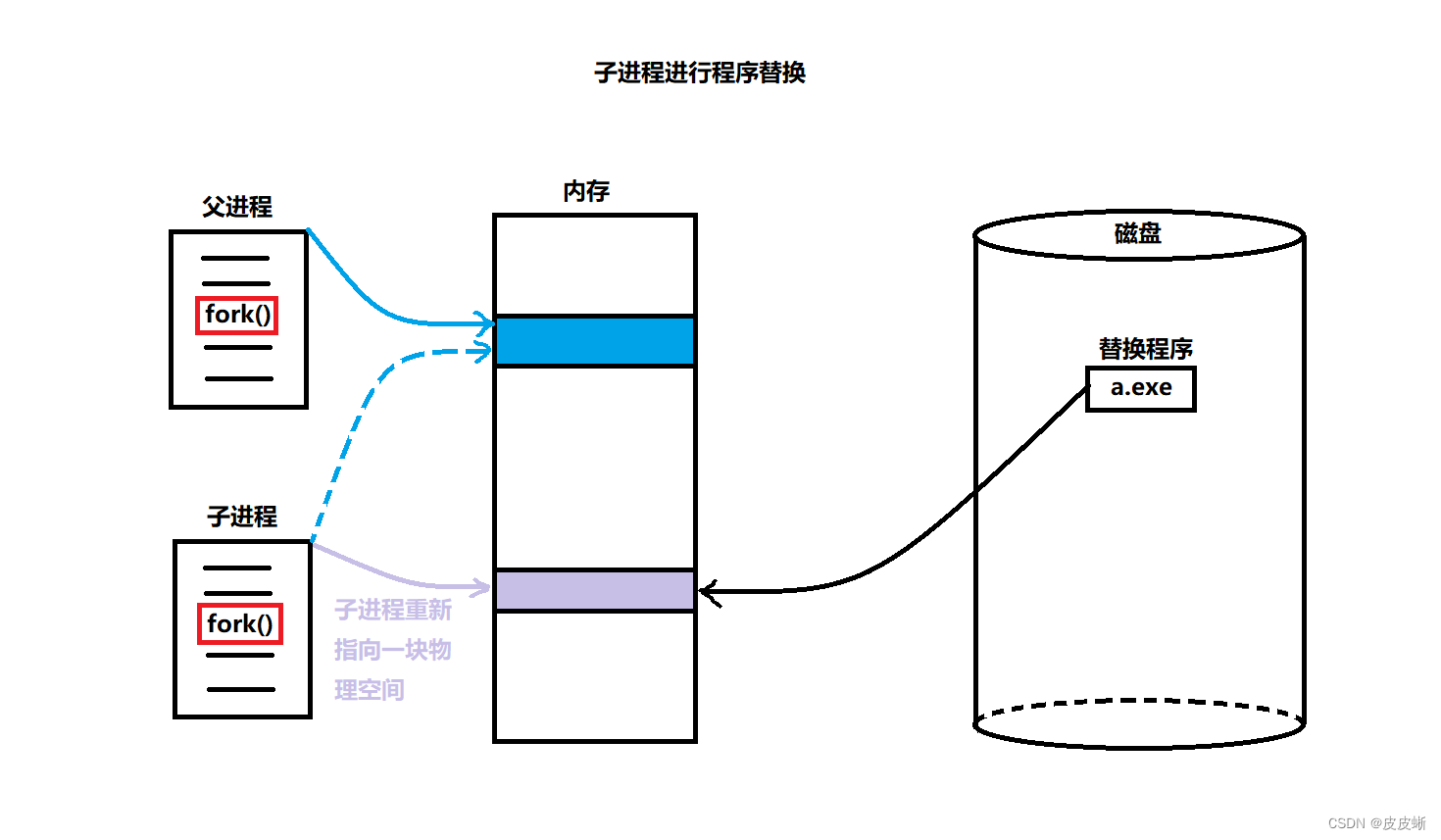
程序替换的原理:
1.将磁盘中的可执行文件加载到内存中。
2.谁进行程序替换,就重新建立谁的页表映射,重新开辟物理空间。
注:子进程和父进程完全分离,保证进程之间的独立性。
整个替换过程中并没有新进程的创建。
程序替换函数
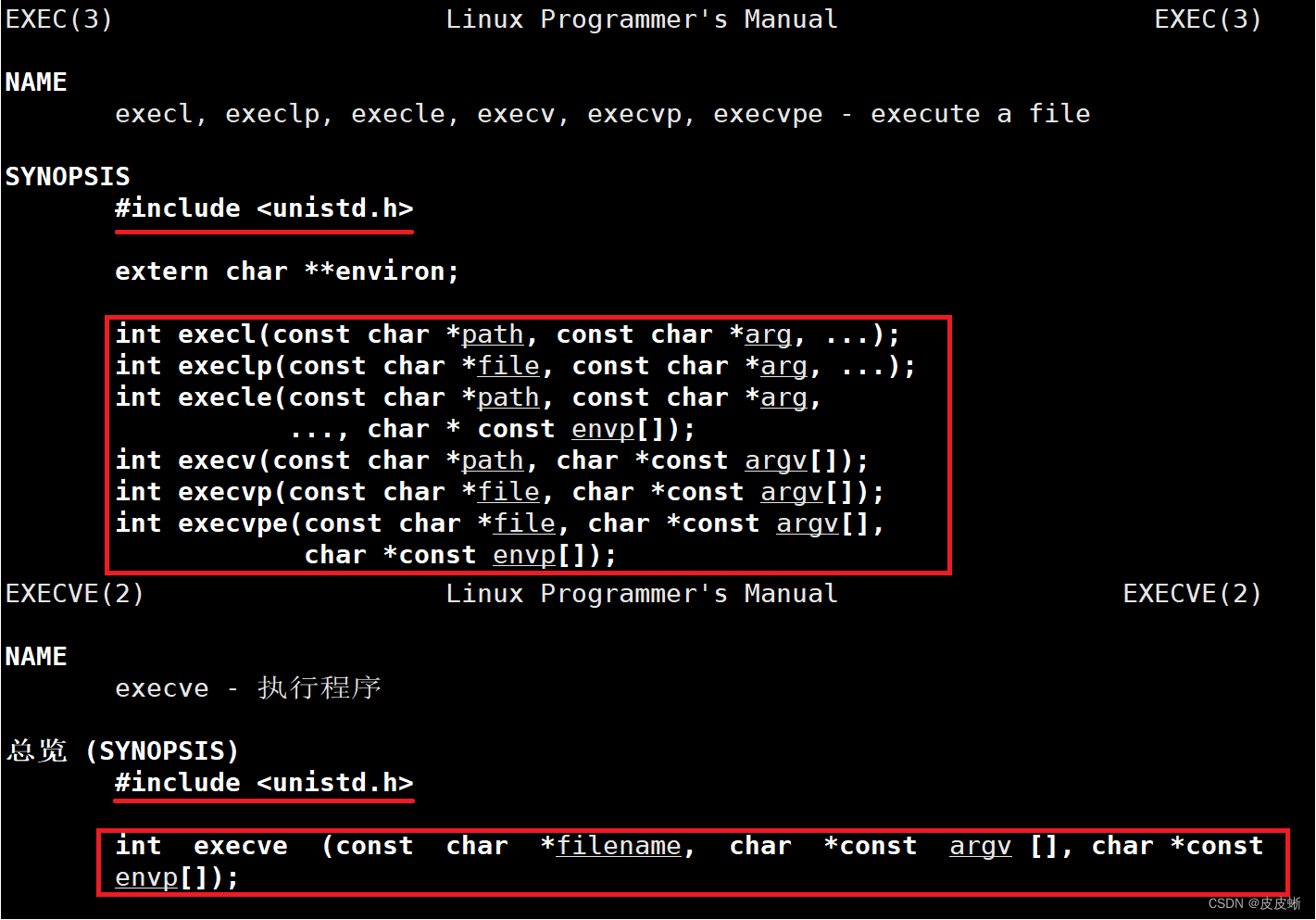
通过man查看,总共是有7个程序替换函数。其中上面六个函数是execve函数的嵌套实现。
接下来我们一个一个的来使用这些函数。
参数:
path:替换程序的绝对路径或相对路径
argv:指令,表示你想怎样运行替换的可执行程序
envp:环境变量
函数名exec***中的*号有'l','v','e',这分别代表不同的含义。
l(list) : 表示参数采用列表
v(vector) : 参数用数组
p(path) : 有p自动搜索环境变量PATH
e(env) : 表示自己维护环境变量
execl
#include<stdio.h>
#include<unistd.h>
#include<sys/wait.h>
#include<sys/types.h>
#include<stdlib.h>
int main()
{
printf("进程开始,pid:%d\n",getpid());
pid_t id=fork();
if(id==0)//子进程
{
printf("子进程,pid:%d\n",getpid());
execl("/usr/bin/ls","ls","-al",NULL);//程序替换
printf("进程替换失败!\n");
}
else if(id>0)//父进程
{
int status;
pid_t ret=waitpid(-1,&status,0);
if(WIFEXITED(status))
{
printf("等待进程pid:%d, status:%d\n",ret,WEXITSTATUS(status));
}
else
{
printf("进程等待失败!\n");
}
}
else//子进程创建失败
{
}
return 0;
}

execl中的"ls","-al","NULL"就是指令参数,以NULL结尾表示已经没有新的指令了,相当于命令行输入 ls -al !
execv
与execl的代码基本相同,但在调用替换函数的上面加了一个指针数组,然后作为参数传给execv的第二个参数。
char* const argv[]={
(char*)"ls",
(char*)"-al",
NULL
};
execv("/usr/bin/ls",argv);
也就是相当于把指令放在一个数组里面了。
execlp
同样与execl相似的代码,只不过第一个参数那里不再是绝对路径或相对路径了,而是文件名,表示自动在环境变量里去搜索文件所在路径。
execlp("ls","ls","-al",NULL);
execvp
与execv基本相同,把第一个参数换为文件名自动寻找路径。
execv("ls",argv);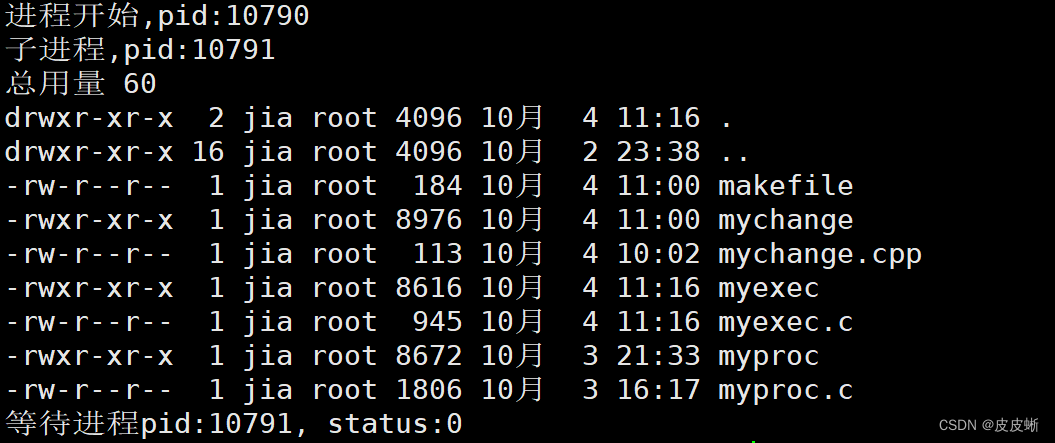
execle
这个函数带e表明是可以传环境变量的,并且要注意一点,这里的环境变量是覆盖式的, 在使用的时候要注意这一点!
//mychange.cpp
#include<iostream>
#include<stdlib.h>
using namespace std;
int main()
{
cout<<"PATH:"<<getenv("PATH")<<endl;
cout<<"________________________________________________________"<<endl;
cout<<"MYPATH:"<<getenv("MYPATH")<<endl;
cout<<"________________________________________________________"<<endl;
return 0;
}
extern char**environ;
execle("./mychange","mychange",NULL,environ);

execve
与execle相似,第二个参数使用数组传参就成。
char* const argv_[]={
(char*)"mychange",
NULL
};
execve("./mychange",argv_,environ);

execvpe
与上面的execve相似,只不过第一个参数传文件名就成。这里就不再赘述了。
🚩总结
进程控制的内容很多,并且有很多细节需要注意,涉及的基础知识也是很广泛:进程地址、环境变量、系统函数调用等等。这部分知识就先分享到这了,以后估计会有扩展的内容,那肯定是以后再讲啦。嘴贫到此结束,再见😋















 1963
1963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









