






libcurl返回中文信息出现乱码问题的解决
-
问题发现
在代码使用过程中发现使用curl库在发送和接收数据过程中收发中文数据会出现乱码,而英文不会(图1-1、图1-2)。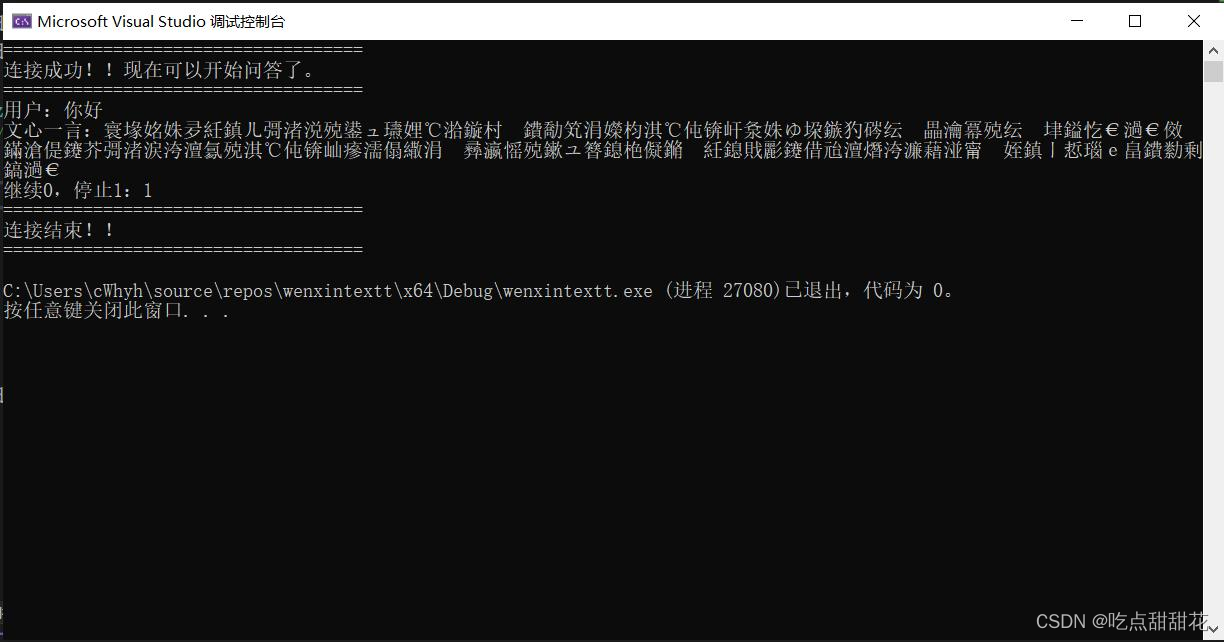
图1-1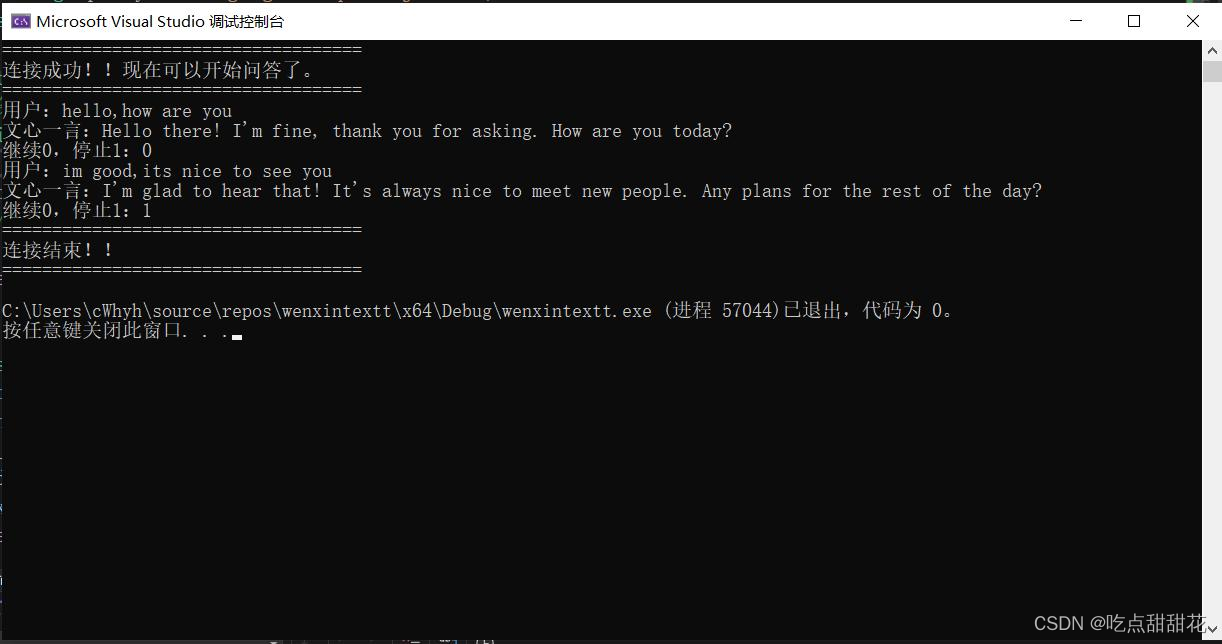
图1-2
经过多次测试,最终确定是本地在某处处理中文字符时出现了问题。经过导师询问专业人士后,怀疑是在对返回的数据进行处理时候出现的问题。经过研究发现返回的数据编码为utf8,它包含的中文字符占字节数大于1,上网查阅资料可知要正常输出utf8中的中文字符需要现将其转化为长字节(wchar),为此编写了一段代码查看其中每个字节的数据,其中message_size为有效的字节长度,data为服务器返回的数据指针:
size_t message_size = size * num;
for (size_t i = 0; i < message_size; ++i) {//检查字符
unsigned char c = static_cast<unsigned char*>(data)[i];
//这里使用无符号字节(unsigned char)避免了在识别utf8编码时出现问题
if (std::isprint(c)) { // 检查字符是否可打印
std::cout << c ;
}
else {
std::cout << "\\x" << std::hex << std::setw(2) << std::setfill('0') << static_cast<int>(c);
//hex设置流为16进制输出模式,setw(2)设置一个字段宽2字符
//setfill('0')设置输出只有一个字符时用0填充,最后转化为int类型输出c
}
}
std::cout << std::endl;由于中文占两个字符,所以在下面的else中输出数据以判断其是否为中文数据。测试代码效果如图1-3。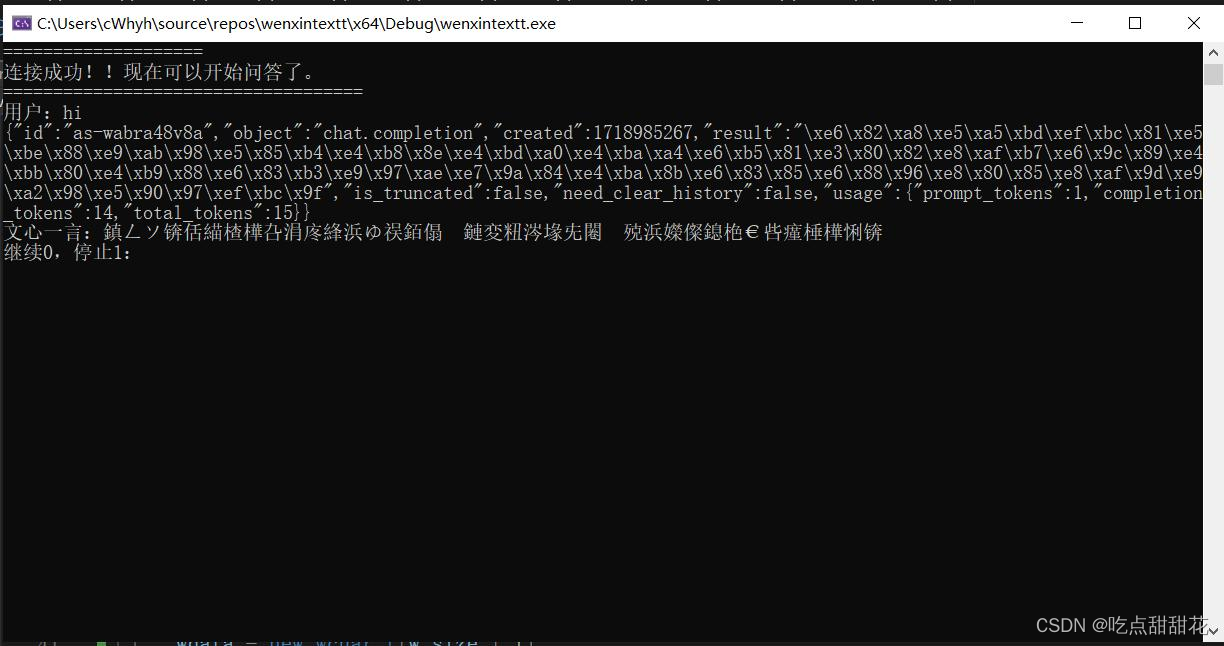
图1-3
其中内容为
“\xe6\x82\xa8\xe5\xa5\xbd\xef\xbc\x81\xe5\xbe\x88\xe9\xab\x98\xe5\x85\xb4\xe4\xb8\x8e\xe4\xbd\xa0\xe4\xba\xa4\xe6\xb5\x81\xe3\x80\x82\xe8\xaf\xb7\xe6\x9c\x89\xe4\xbb\x80\xe4\xb9\x88\xe6\x83\xb3\xe9\x97\xae\xe7\x9a\x84\xe4\xba\x8b\xe6\x83\x85\xe6\x88\x96\xe8\x80\x85\xe8\xaf\x9d\xe9\xa2\x98\xe5\x90\x97\xef\xbc\x9f”,使用文心一言分析该数据(图1-4):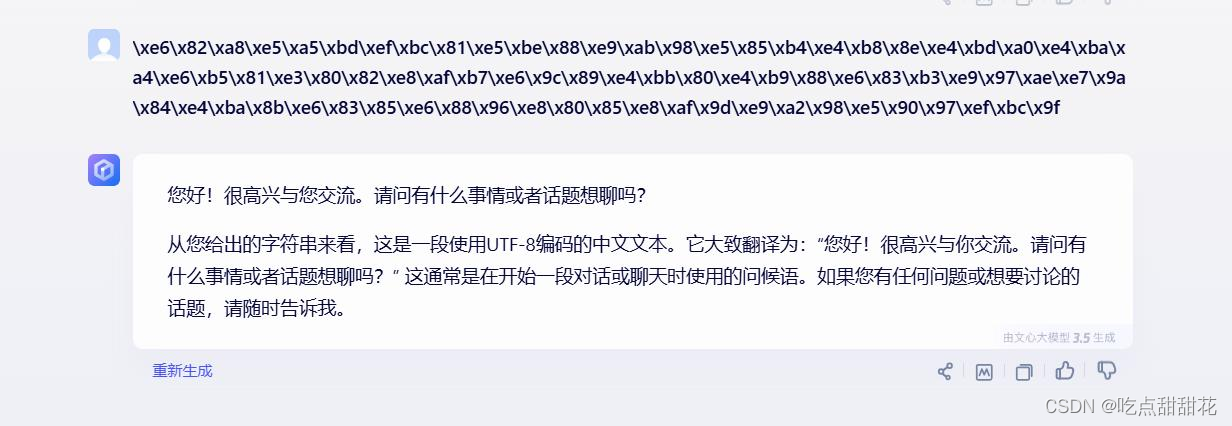
图1-4
得知服务器传回的数据没有问题,问题出现在数据的转换上。我在代码中编写的转换为:
localstr->append(static_cast<char*>(data), message_size);这其中localstr为我要存储数据的字符串指针,data为服务器返回的数据指针,message_size为数据有效长度,这里直接将服务器返回的数据拼接到我的localstr上。
由于utf8编码当中中文的字节数长短不一,有1~4个字节,导致拼接时混淆了不同字节之间的界线,比如服务器传回的数据为“你好”,这两个字符的utf8编码分别为e4bda和e5a5bd,如果直接拼接到程序的string或者char[]后面,结果会变为e4bdae5a5bd,系统在读取时可能会读e4bdae5和a5bd,这样得出的结果就可能导致乱码;而英文字符都只占一个字符,所以不会出现这个问题。
在导师询问专业人士后可知windows提供的api函数MultiByteToWideChar和WideCharToMultiByte可以有效解决这个问题。
-
解决
MultiByteToWideChar和WideCharToMultiByte这两个函数是window提供的api接口函数,要使用它们需要再头部加上#include<Windows.h>才能使用。它们的作用是将数据在wchar_t[]类型和char[]类型之间转换,并且在转换过程中可以更改编码类型。
--函数介绍:
MultiByteToWideChar(CP_ACP, 0, sdata.c_str(), -1, wdata, s_size + 1)这个函数的作用为按照设置的编码参数读取wchar_t类型的数据并将其转化为char类型。在参数前面有被”_..._”包括的信息,这是SAL注释,是用于函数参数的注释。按住ctrl左键函数查看其声明,可见其中各个参数为:
·_In_ UINT CodePage
_in_表示读取数据但不修改。该参数作为转码依据,如上面写的CP_ACP(ANSI代码页)与GBK编码相似,windows没有明确的代码页表示GBK编码,所以使用它代替。它表示转换完后结果的编码方式,即上述中放入wdata的字符的编码。
·_In_ DWORD dwFlags
指定转换选项,用于应对特殊转换。可以填写为0,表示默认转换选项。
·_In_NLS_string_(cbMultiByte) LPCCH lpMultiByteStr
_In_NLS_string_是更具体的注释,表示这是个字符串,且长度由cbMultiByte指定;而NLS与语言有关,表示国家语言支持。指向将要被转换的char[]。
·_In_ int cbMultiByte
被转换的字符中有效长度。这里可以填-1表示整段长度,到空字符’\0’为止,效果为计算填入的char[]的长度。
·_Out_writes_to_opt_(cchWideChar,return) LPWSTR lpWideCharStr
_Out_writes_to_opt_表示函数会向缓冲区写入数据。这是指向wchar_t的缓冲区的指针,用于接收转换完成的数据。
·_In_ int cchWideChar
缓冲区大小,如果此值小于转换后的宽字符字符串所需的长度,函数将失败并返回所需的大小。一般在第一次调用该函数时在这一项填写为0使之输出需要的大小,在第二次调用时填写正确大小+1(防止数据溢出),这时输出的值为由 lpWideCharStr 指向的缓冲区中写入的宽字符数。
函数返回值为0时调用失败,
WideCharToMultiByte(CP_ACP, 0, wdata, -1, cdata, d_size + 1, nullptr, nullptr);这个函数作用与上面MultiByteToWideChar相似,但是转换的数据类型相反,它也按照设置的编码参数读取数据并且将其转化:
·_In_ UINT CodePage
转换的编码依据,指定待转换的数据要用何种编码读取,即上述wdata编码方式。
·_In_ DWORD dwFlags
指定转换选项,用于应对特殊转换。可以填写为0,表示默认转换选项。
·_In_NLS_string_(cchWideChar) LPCWCH lpWideCharStr
指向将要被转换的wchar_t[]。
·_In_ int cchWideChar
被转换的字符中有效长度。这里可以填-1表示整段长度,到空字符L’\0’为止,效果为计算填入的wchar_t[]的长度。
·_Out_writes_bytes_to_opt_(cbMultiByte,return) LPSTR lpMultiByteStr
这是指向char的缓冲区的指针,用于接收转换完成的数据。
·_In_ int cbMultiByte
缓冲区大小,如果此值小于转换后的宽字符字符串所需的长度,函数将失败并返回所需的大小。一般在第一次调用该函数时在这一项填写为0使之输出需要的大小,在第二次调用时填写正确大小+1(防止数据溢出),这时输出的值为由lpMultiByteStr指向的缓冲区中写入的宽字符数。
·_In_opt_ LPCCH lpDefaultChar
指向默认字符的指针,用于处理无法转换的字符。如果没有这个需要可以填空指针nullptr。
·_Out_opt_ LPBOOL lpUsedDefaultChar
指向一个BOOL类型的变量,用于标识是否使用了默认字符。如果没有这个需要可以填空指针nullptr。
上面只简单介绍了用法和参数,需要详细信息和明确其它参数可以在官网上查阅:MultiByteToWideChar 函数 (stringapiset.h) - Win32 apps | Microsoft Learn、WideCharToMultiByte 函数 (stringapiset.h) - Win32 apps | Microsoft Learn。
根据上述信息,我编写了简单函数处理utf8数据:
std::string utf8ToString(void* utf8_data, int data_size) {
wchar_t* wdata = NULL;
int w_size,skis;
w_size = MultiByteToWideChar(CP_UTF8, MB_PRECOMPOSED, static_cast<char*>(utf8_data), data_size, nullptr, 0);
//这里需要先获取需要生成的缓冲区大小,所以先调用一次mbtwc函数,使用的也是空指针nullptr
wdata = new wchar_t[w_size + 1];
skis = MultiByteToWideChar(CP_UTF8, MB_PRECOMPOSED, static_cast<char*>(utf8_data), data_size, wdata, w_size + 1);
//这一次才是正常处理数据
wdata[w_size] = L'\0';//这里要注意,宽字符需要以'\0'结尾,否则会导致输出错误
std::wcout << L"转码:" << wdata << std::endl;
delete[] wdata;
return "0";
}运行代码进行测试(图2-1)发现仍然为乱码: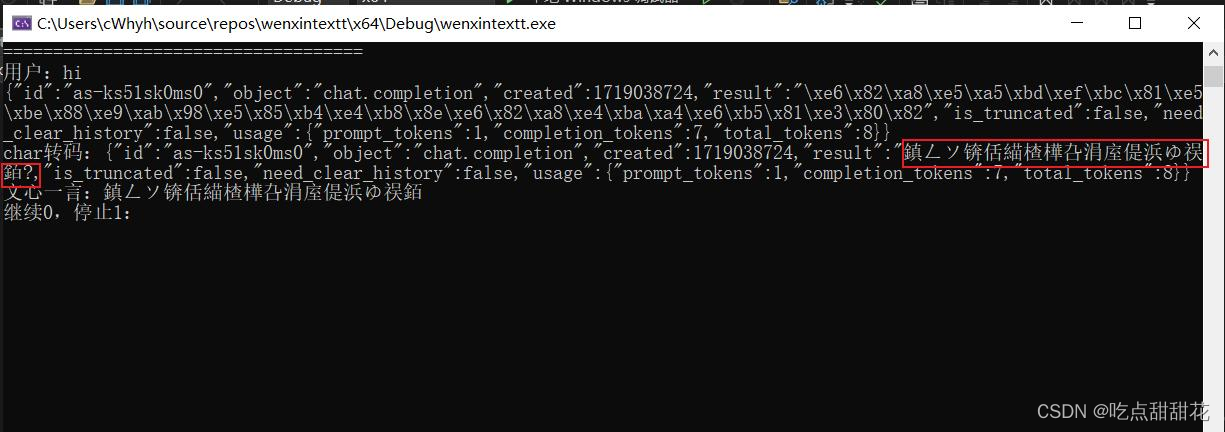
图2-1
经过查阅长字符的相关信息,在一篇文章中得知要在前面设置wcout的输出方式,原文地址:【c++】wchar_t的详细教程,关于wchar_t使用wcout编译运行输出结果为空以及为乱码类似O的解决办法...._wcout输出中文乱码-CSDN博客
std::wcout.imbue(std::locale("chs"));//载入中文字符输入方式现在再次运行代码测试图2-2: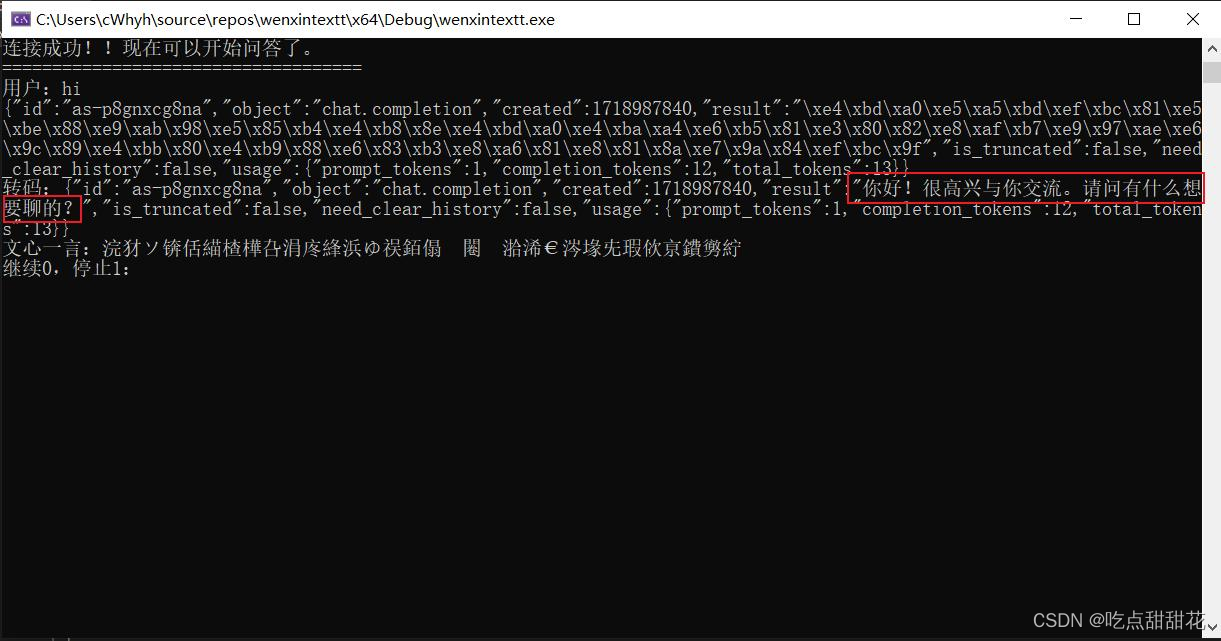
图2-2
可见猜想正确,这里也能成功输出。但这种方式将utf8编码的数据转化为了长字符,要想正常使用还需要将其转化为string或者char[]类型。这里我尝试了另一个函数WideCharToMultiByte(),它输出的中文依然是乱码,可见出现了上面一开始处理数据时候的相同错误,代码为:
d_size = WideCharToMultiByte(CP_UTF8, 0, wdata, -1, nullptr, 0, nullptr, nullptr);
//这里的wctmb和上面mbtwc用法类似,只是转换的数据类型不同,其中nullptr用法也与上面相同
cdata = new char[d_size + 1];
sksis = WideCharToMultiByte(CP_UTF8, 0, wdata, -1, cdata, d_size + 1, nullptr, nullptr);
cdata[d_size] = '\0';
std::cout << "转换为char[]:" << cdata << std::endl;运行效果如图2-3: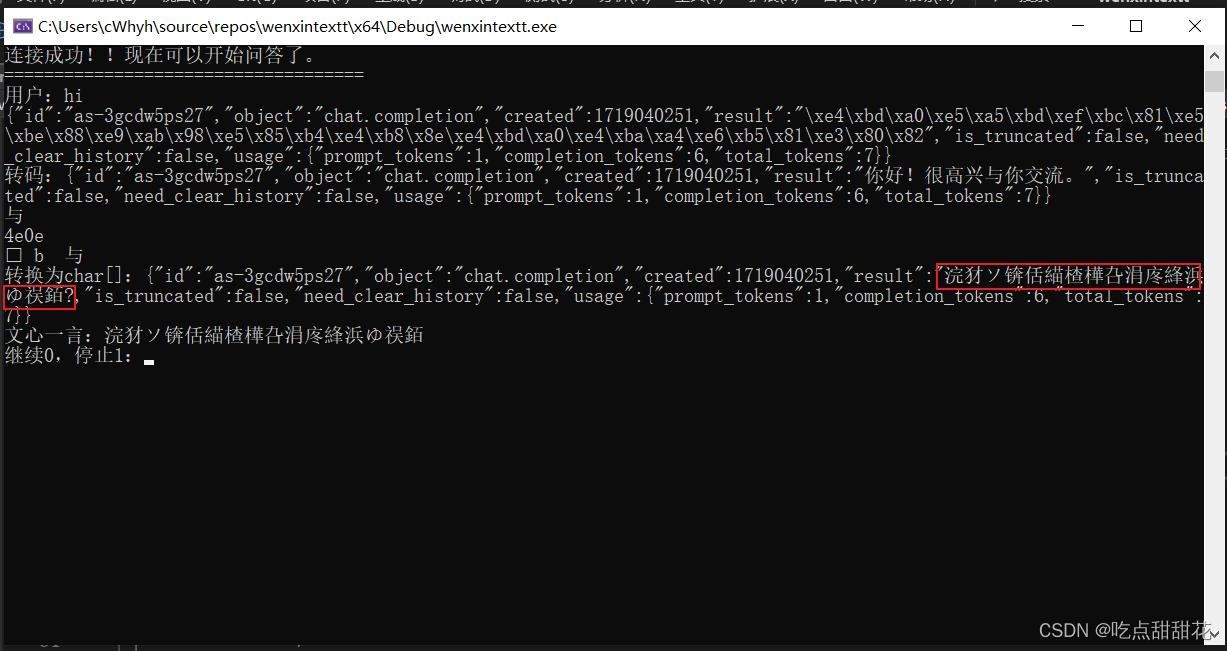
图2-3
查阅网站,发现是参数设置错误,第一个参数为要转换为的字符的编码,即上面参数中cdata中的编码,而不是源字符(wdata)编码,与上面MultiByteToWideChar()不同,我先入为主了,这里string的编码为GBK编码,所以参数应该设置为CP_ACP,现在再次运行程序后数据正确(图2-4):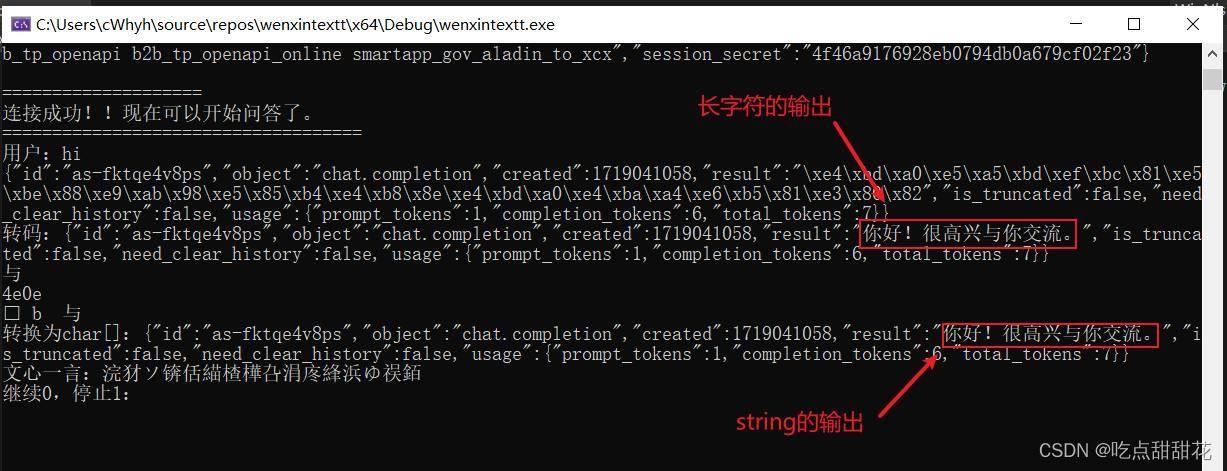
图2-4
将其放入curl的回调函数中测试效果,运行后如图2-5:
size_t loaddata(void* data, size_t size, size_t num, std::string* localstr)
{//服务器返回的数据、单个数据块字节大小、数据字节数目、你要存储的地址指针
size_t message_size = size * num;
localstr->append(utf8ToString(data, (int)message_size));
return message_size;//返回数据总大小
}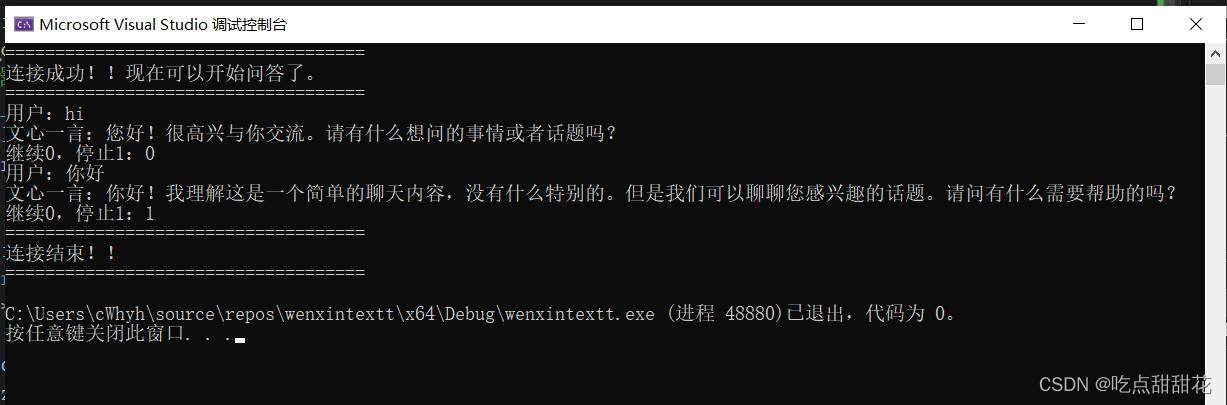
图2-5
到此所有字符乱码问题基本已经解决,接下来只需要把发送时的数据经过处理转化为utf8编码即可正确调用文心一言api服务。
根据上述我编写了字符串转换为utf8编码的函数:
std::string stringToutf8(std::string sdata) {
wchar_t* wdata = NULL;
char* u8data = NULL;
int s_size, sksis;
s_size = MultiByteToWideChar(CP_ACP, MB_PRECOMPOSED, sdata.c_str(), -1, nullptr, 0);
if (s_size == 0) throw "string获取转换长度失败啦!!";
wdata = new wchar_t[s_size + 1];
sksis = MultiByteToWideChar(CP_ACP, MB_PRECOMPOSED, sdata.c_str(), -1, wdata, s_size + 1);
if (sksis == 0) throw "string转换失败啦!!";
wdata[s_size] = L'\0';//给最后一位赋值避免错误
s_size = WideCharToMultiByte(CP_UTF8, 0, wdata, -1, nullptr, 0, nullptr, nullptr);
if (s_size == 0) throw "长字节获取转换长度失败啦!!";
u8data = new char[s_size + 1];
sksis = WideCharToMultiByte(CP_UTF8, 0, wdata, -1, u8data, s_size + 1, nullptr, nullptr);
if (sksis == 0) throw "长字节转换失败啦!!";
u8data[s_size] = '\0';
sdata = u8data;
delete[] wdata, u8data;
return sdata;
}它可以将输入的字符串转化为utf8编码后输出为字符串。将它拼接到访问服务器的代码当中尝试效果(图2-6):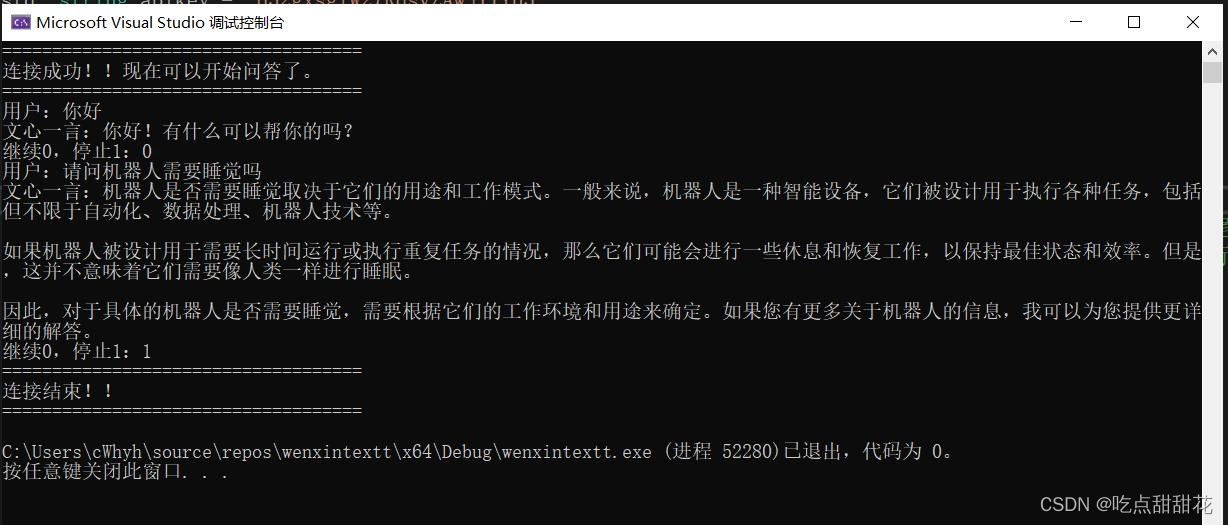
图2-6
对比文心一言测试数据(图2-7)可见回复的内容没有太大差异,这表面到这里程序已经较为完善,可以正常使用了。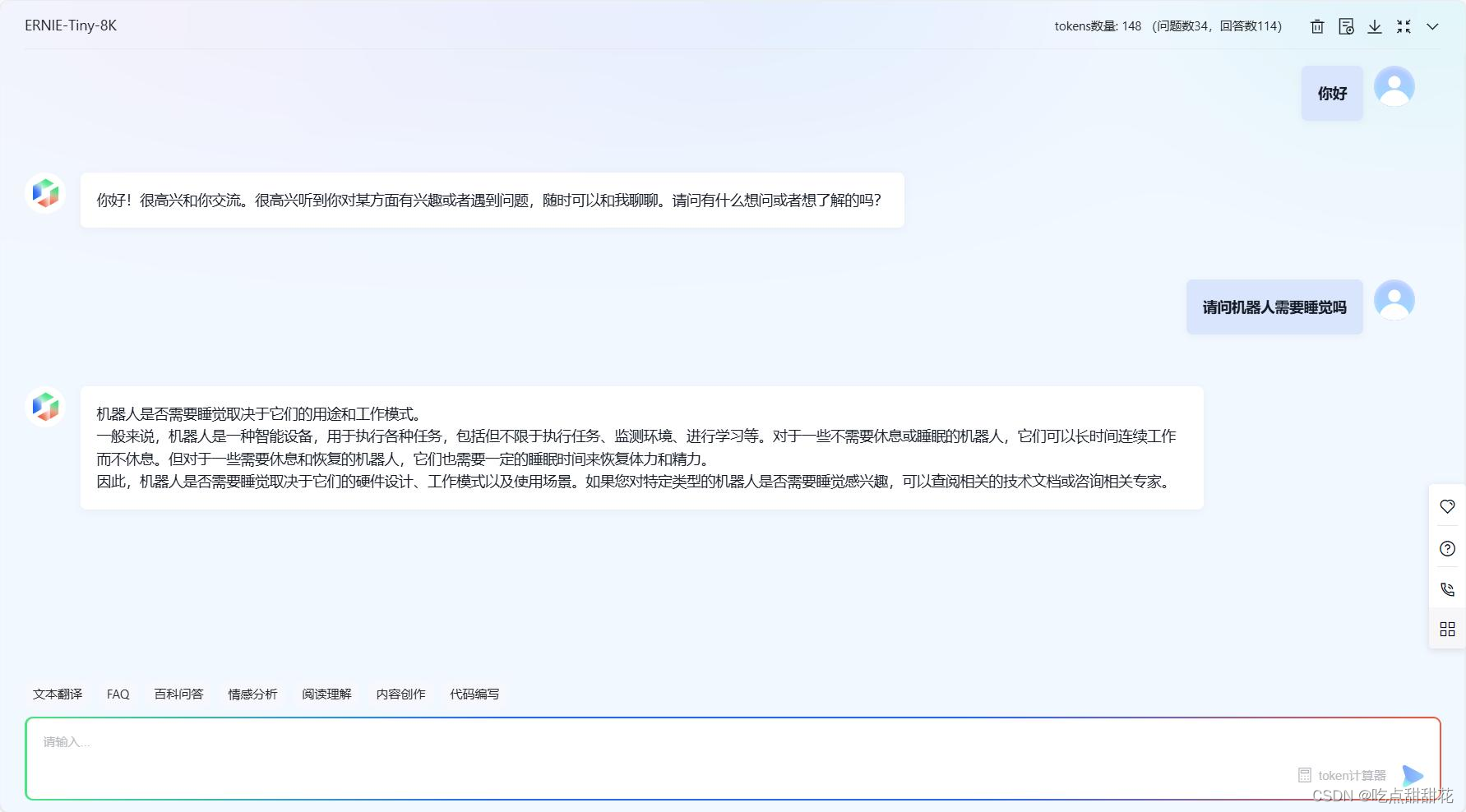
图2-7
需要注意的是,我编写的字符串编码转换的函数只能用于转换中文字符,若是直接用它转换上传给服务器的其他参数会导致错误,最好的用法是在用户输入时直接将内容转换,然后再将转换完成的字符串拼接在上传的数据当中。
此外,还有一些专门用于字符数据转换的库如ICU可以使用,最终效果也可用。
文章性质为本人学习后做的笔记,如有侵权请联系本人删除。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









