







上一篇博客,为大家详细得讲解了进程,那么本篇,主要就开始研究线程,以及在Java中是如何进行多线程并发编程的.
本篇博客目标在于带大家理解和认识多线程,然后进一步掌握多线程程序的编写和状态,认识什么是线程不安全,以及其对应的解决思路,灾后掌握一系列的关键字
线程是啥?!(Thread)
OK,为了保持本篇博客的严谨性,我们先来非常offensive一下,去查一查官方的解释
给大家总结一下.
线程是程序运行的基本执行单元。当操作系统(不包括单线程的操作系统,如微软早期的DOS)在执行一个程序时,会在系统中建立一个进程,而在这个进程中,必须至少建立一个线程(这个线程被称为主线程)来作为这个程序运行的入口点。因此,在操作系统中运行的任何程序都至少有一个主线程。
进程和线程是现代操作系统中两个必不可少的运行模型。在操作系统中可以有多个进程,这些进程包括系统进程(由操作系统内部建立的进程)和用户进程(由用户程序建立的进程);一个进程中可以有一个或多个线程。进程和进程之间不共享内存,也就是说系统中的进程是在各自独立的内存空间中运行的。而一个进程中的线可以共享系统分派给这个进程的内存空间。
线程不仅可以共享进程的内存,而且还拥有一个属于自己的内存空间,这段内存空间也叫做线程栈, 是在建立线程时由系统分配的,主要用来保存线程内部所使用的数据,如线程执行函数中所定义的变量。
注意:任何一个线程在建立时都会执行一个函数,这个函数叫做线程执行函数。也可以将这个函数看做线程的入口点(类似于程序中的main函数)。无论使用什么语言或技术来建立线程,都必须执行这个函数(这个函数的表现形式可能不一样,但都会有一个这样的函数)。如在Windows中用于建立线程的API函数CreateThread的第三个参数就是这个执行函数的指针。
在操作系统将进程分成多个线程后,这些线程可以在操作系统的管理下并发执行,从而大大提高了程序的运行效率。虽然线程的执行从宏观上看是多个线程同时执行,但实际上这只是操作系统的障眼法。由于一块CPU同时只能执行一条指令,因此,在拥有一块CPU的计算机上不可能同时执行两个任务。而操作系统为了能提高程序的运行效率,在一个线程空闲时会撤下这个线程,并且会让其他的线程来执行,这种方式叫做线程调度。我们之所以从表面上看是多个线程同时执行,是因为不同线程之间切换的时间非常短,而且在一般情况下切换非常频繁。假设我们有线程A和B。在运行时,可能是A执行了1毫秒后,切换到B后,B又执行了1毫秒,然后又切换到了A,A又执行1毫秒。由于1毫秒的时间对于普通人来说是很难感知的,因此,从表面看上去就象A和B同时执行一样,但实际上A和B是交替执行的。
以上便是整理出的线程概念,初学的小白可能很难看得明白
那么现在我们就对这些非常官方的东西做一些比较人性化的解释
首先,线程和进程之间有一定的练习,那么为什么要有多个进程呢?
答:是为了并发编程!但是CPU单个核心已经发展到了极致,如果想要提升算力,就得使用多个核心,那么我们引入并发编程,最大的目的就是为了能够充分的利用好CPU的多核资源.
使用多进程这种编程模型,是完全可以做到并发编程的,并且也能够使CPU多核被充分利用.但是在有些场景下,又会产生一些问题:如果需要频繁地创建/销毁进程,这个时候就会比较低效.
那么创建和销毁进程有什么应用背景呢?比如,你写了一个服务器程序,服务器要同一时刻给很多客户端提供服务,这个时候就需要并发编程了,典型地做法,就是每个客户端分配一个进程,提供一对一的服务
创建/销毁进程,本身就是一个比较低效的操作:
- 创建PCB
- 分配系统资源(尤其是内存资源)<–这一步比较消耗时间
- 把PCB加入到内核的双向链表中
为了提高这个场景下的效率,我们就引入了"线程",线程其实也叫做"轻量级进程"
一个线程其实是包含在进程中的,一个进程里面可以有很多个线程.每个线程也有自己的PCB(一个进程里面可能就对应多个PCB)同一个进程里面的多个线程之间,共用一份系统资源,这就意味着,新创建的线程,可以不必重新给他分配系统资源,只需要复用之前的就可以了.
因此创建线程只需要:
- 创建PCB
- 把PCB加入到内核的链表当中
这就是线程相对于进程做出的重大改进,也就是线程更加轻量的原因
进程是系统分配资源的最小单位,线程是系统调度的最小单位.
Java的线程与操作系统线程的关系
操作系统线程模型
线程-在用户空间下实现
当线程在用户空间下实现的时候,操作系统对线程的存在并不知晓,操作系统只能看到进程,而不能看到进程.所有的线程都是在用户控件实现的.在操作系统看来,每一个进程只有一个线程,过去的操作系统大部分是这种实现方式,这种方式的好处之一是即使操作系统不支持线程,也可以通过库函数来支持线程.
那么我们用更通俗的方式来讲解这段话.在这种模型下,程序员需要自己实现线程的数据结构,创建销毁和调度维护.也就相当于需要实现一个自己的线程调度内核,而同时这些线程运行在操作系统的一个进程内,最后操作系用直接对进程进行调度

这样做是由一些有点的,首先就是确实在操作系统种实现了真实的多线程,其次线程的调度只是在用户态,减少了操作系统从内核态到用户态的切换开销
当然,缺点也是很明显的.
这种模式最致命的缺点也是由于操作系统不知道线程的存在,因此当一个进程中的某一个线程进行系统调用时,比如缺页中断而导致线程阻塞,此时操作系统会阻塞整个进程,即使这个进程中其它线程还在工作。还有一个问题是假如进程中一个线程长时间不释放CPU,因为用户空间并没有时钟中断机制,会导致此进程中的其它线程得不到CPU而持续等待。
线程实现在操作系统内核中
内核线程就是直接由操作系统内核支持的线程,这种线程由内核来完成内核切换,内核通过操纵调度器队线程进行调度,并负责将线程的任务映射在各个处理器上.每个内核线程可以视为内核的一个分身,这样操作系统就有能力同时处理多件事情,支持多线程的内核就叫做多线程内核
通俗的讲,程序员直接使用操作系统中已经实现的线程,而线程的创建,销毁,调度,和维护,都是靠操作系统(准确的说是内核)来实现,程序员只需要使用系统调用,而不需要自己设计线程的调度算法和线程队CPU资源的抢占使用
轻量级进程(LWP)是建立在内核之上并由内核支持的用户线程,它是内核线程的高度抽象,每一个轻量级进程都与一个特定的内核线程关联.内核线程只能由内核管理并像普通进程一样被调度
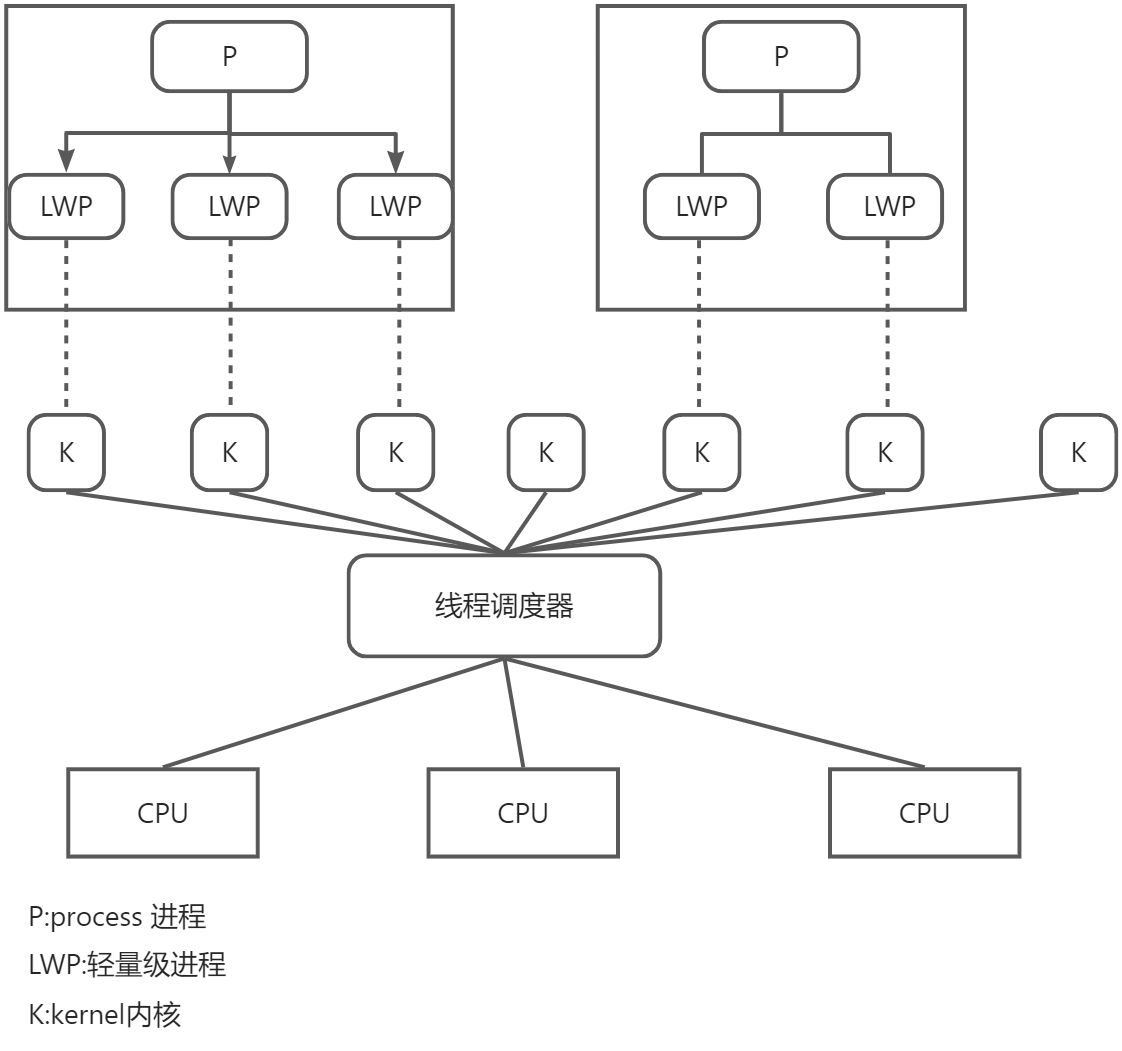
这种轻量级进程与内核线程之间1:1的 关系就称为一对一的线程模型
使用用户线程更加轻量级进程混合实现
在这种混合实现下,即存在用户线程,也存在轻量级线程.用户线程还是可以完全建立在用户空间中,因此用户线程的创建,切换,析构等操作依然十分廉价,并且可以支持大规模的用户线程并发.而操作系统提供支持的轻量级进程则作为用户线程和内核线程之间的桥梁,这样可以使用内核提供的线程线程调度共嗯那个及处理器映射,并且用户线程的系统调用要通过轻量级进程来完成,大大降低了整个进程被完全阻塞的风险.在这种混合模式中,用户线程与轻量级进程的数量比是不定的
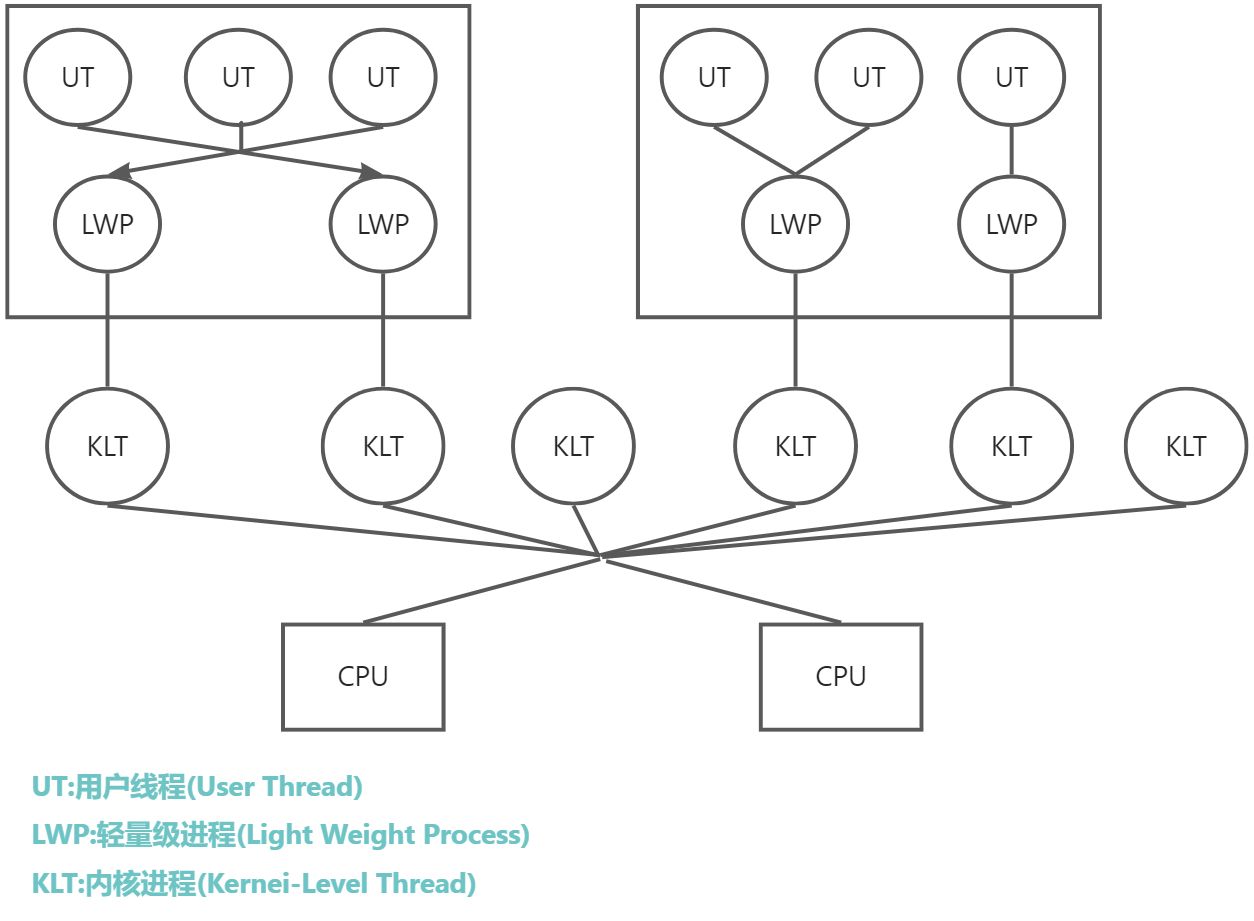
明白了前面两种模型,就很好理解这种线程模型了,但实际上现在主流的操作系统已经不太常用这种线程模型了
Java线程
Java线程在操作系统上本质
Java线程在JDK1.2之前,是基于称为绿色线程的用户线程实现的,而在JDK1.2中,线程模型替换为基于操作系统原生线程模型来实现.因此,在目前的我JDK版本中,操作系统支持怎样的线程模型,在很大程度上决定了Java虚拟机的线程是怎样映射的,这单在不同的平台没有办法达成一致,虚拟机规范中也并未限定Java线程需要使用哪种线程模型来实现.线程模型支队线程的并发规模和操作成本产生影响,队Java程序的编码和运行过程来说,这些差异都是透明的.
也就是说程序员们为JVM开发了自己的一个线程调度内核,而到操作系统层面就是用户空间内的线程实现.而到了JDK1.2以后,JVM选择了更加稳健且方便使用的操作系统原生的线程模型,通过系统调用,将程序的线程交给了操作系统内核进行调度
也就是说,现在的Java中线程的本质,也就是操作系统中的线程,Linux下是基于pthread库实现的轻量级进程,Windows下是原生的系统win32API提供系统调用从而实现多线程
Java中的线程
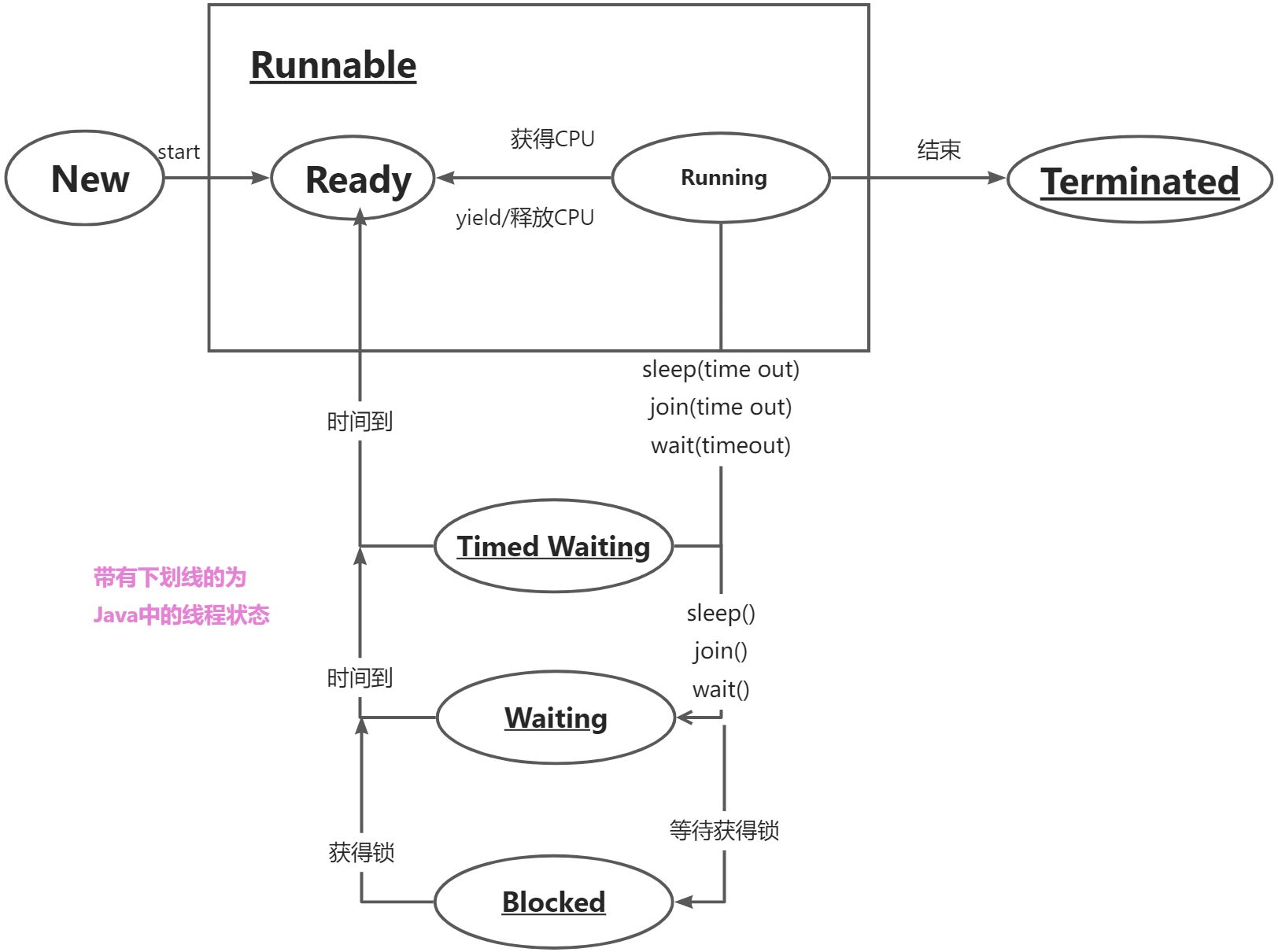
特别注意:这些线程的状态时JVM中的线程状态!不是操作系统中的线程状态。
操作系统中的进程(线程)状态(区分和JVM中的线程状态)
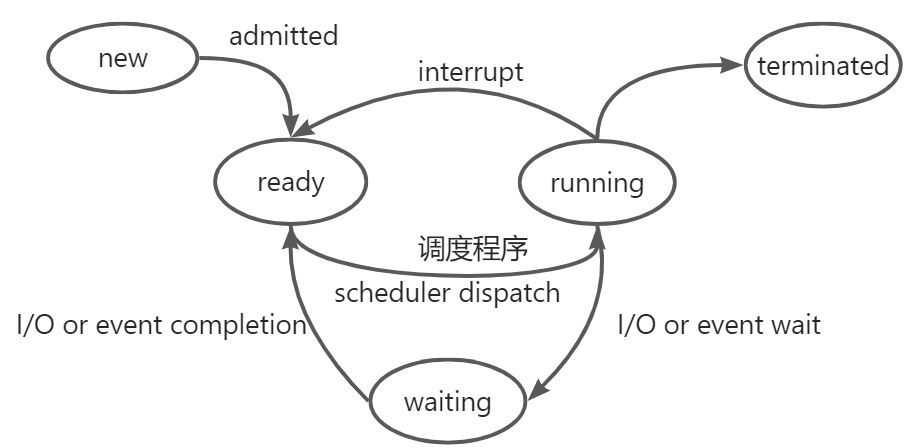
这里需要着重解释一点,再现在的操作系统中,因为线程依旧被视为轻量级进程,所以操作系统中线程的状态实际上和进程状态时一致的模型
操作系统中线程和Java线程状态的关系
从实际意义上来讲,操作系统中的线程除去new和terminated状态,一个和线程真实存在的状态,只有
- ready:表示线程已经被创建,正在等待系统调度分配CPU使用权
- running:表示线程获得了CPU使用权,正在运行
- waiting:表示线程等待(或者说挂起),让出CPU资源给其他线程使用
那么为什么除去new和terminated状态呢?是因为这两种状态实际上并不存在于线程运行中,所以也没什么实际讨论的意义
对于Java中的线程状态:
无论是Timed Waiting ,Waiting还是Blocked,对应的都是操作系统线程的waiting(等待)状态
而Runnable状态,则对应了操作系统中的ready和running状态
而对不同的操作系统,由于本身设计思路不一样,对于线程的设计也存在差异,所以JVM在设计的时候已经声明:虚拟机中的线程状态,不反应任何操作系统线程状态.
为哈要有线程?
进程属于在CPU和系统资源等方面提供的抽象,能够有效提高CPU的利用率。
线程是在进程这个层次上提供的一层并发的抽象:
- 能够使系统在同一时间能够做多件事情;
- 当进程遇到阻塞时,例如等待输入,线程能够使不依赖输入数据的工作继续执行
- 可以有效地利用多处理器和多核计算机,在没有线程之前,多核并不能让一个进程的执行速度提高
进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率。很多人就不理解了,既然进程这么优秀,为什么还要线程呢?其实,仔细观察就会发现进程还是有很多缺陷的,主要体现在两点上:
进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
如果这两个缺点理解比较困难的话,举个现实的例子也许你就清楚了:如果把我们上课的过程看成一个进程的话,那么我们要做的是耳朵听老师讲课,手上还 要记笔记,脑子还要思考问题,这样才能高效的完成听课的任务。而如果只提供进程这个机制的话,上面这三件事将不能同时执行,同一时间只能做一件事,听的时 候就不能记笔记,也不能用脑子思考,这是其一;如果老师在黑板上写演算过程,我们开始记笔记,而老师突然有一步推不下去了,阻塞住了,他在那边思考着,而 我们呢,也不能干其他事,即使你想趁此时思考一下刚才没听懂的一个问题都不行,这是其二。
现在你应该明白了进程的缺陷了,而解决的办法很简单,我们完全可以让听、写、思三个独立的过程,并行起来,这样很明显可以提高听课的效率。而实际的操作系统中,也同样引入了这种类似的机制——线程。
线程的优点
因为要并发,我们发明了进程,又进一步发明了线程。只不过进程和线程的并发层次不同:进程属于在处理器这一层上提供的抽象;线程则属于在进程这个层 次上再提供了一层并发的抽象。如果我们进入计算机体系结构里,就会发现,流水线提供的也是一种并发,不过是指令级的并发。这样,流水线、线程、进程就从低 到高在三个层次上提供我们所迫切需要的并发!
除了提高进程的并发度,线程还有个好处,就是可以有效地利用多处理器和多核计算机。现在的处理器有个趋势就是朝着多核方向发展,在没有线程之前多核并不能让一个进程的执行速度提高,原因还是上面所有的两点限制。但如果讲一个进程分解为若干个线程,则可以让不同的线程运行在不同的核上,从而提高了进 程的执行速度。
进程和线程的区别
- 进程是具有一定独立功能的而程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位
- 线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位,线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源
- 一个线程可以创建和撤销另一个线程,同一个进程中的多个线程之间可以并发执行
进程和线程的主要差别在于他们是不同的操作系统资源管理方式.进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其他进程产生影响,而线程只是一个进程中的不同执行路径.线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些.但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程.
创建一个多线程程序
package thread;
/**
* @author Gremmie102
* @date 2022/7/21 9:15
* @purpose : 关于多线程的一些代码,创建线程的第一种方法
*/
class MyThread extends Thread{
public void run(){
//这个run方法重写的目的,是为了明确,咱们新创建出来的线程要干啥活
while(true){
System.out.println("hello thread!");
try{
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Demo1 {
public static void main(String[] args) {
//创建一个线程
//Java中创建线程,离不开一个关键的类.Thread
//其中一种比较朴素的创建方式,是写一个子类,继承Thread,重写其中的run方法
//光创建了这个类,还不算创建线程,还得创建实例
Thread t = new MyThread();//向上转型的写法,可写可不写
t.start();//这才是真正开始创建线程
//(在操作系统内核中,创建出对应线程的PCB,然后让这个PCB加入到系统链表中,参与调度)
//在这个代码中,虽然先启动的线程,后打印的hello main
//但是实际执行的时候,看到的确是,先打印了hello main ,后打印了hello thread!
//这是因为:
// 1.每个线程是独立的执行流,
//main对应的线程是一个执行流,MyThread是另一个执行流.
//这两个执行流之间是并发的执行关系(并发+并行)
//2.此时两个线程执行的先后顺序,取决于操作系统调度器具体实现
//(程序员可以把这里的调度规则,简单得视为"随机调度")
//System.out.println("hello main");
//虽然反复运行了多次,好像结果都是一样的,但我们的顺序仍然是不可确定的
//当前看到的先打印main,大概率是受到创建线程自身的开销影响的.
//哪怕连续运行1000次main在前,也不能保证1001次的时候不出现thread在前!
//*编写多线程代码的时候,一定要注意到!
//默认情况下,多个线程的执行顺序,是"无序",是"随机调度"的
//进程的退出码为:exit code 0
//操作系统中用进程的退出码来表示"进程的运行结果"
//使用0表示进程执行完毕.结果正确
//使用非0表示进程执行完毕,结果不正确
//还有个别情况main还没返回呢,进程就崩溃,此时返回的值很可能是一个随机值
//我们可以想办法让这个进程别结束得那么快,好看清楚这个进程
//我们可以搞两个si循环
while(true){
System.out.println("hello main");
try{
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//运行之后我们就可以发现,main和thread交替打印
//每一波打印机个,切换到下一波是什么时候,都是不确定的,都是由调度器控制的
//在JDK里提供了一个jconsole这样的工具,可以看到Java进程里的线程详情.
//在jdk/bin/jconsole.exe
//启动之后先选择我们要看哪个Java进程
//少数情况打开jconsle时,可能不显示这里的进程列表.
//这个时候退出,然后右键管理员运行.
//在标签页中选择线程,往下翻,在左下角部分可以查询到当前Java进程中的线程信息了
//刚才的死循环代码,打印的太多太快
//有的时候不希望它们打印的这么快(不方便来观察)
//我们可以用sleep()来让线程适当的"休息一下"-->指定让线程摸一会鱼,不要上cpu干活
//使用Thread.sleep();的方法进行休眠
//sleep时Thread的静态成员方法
//sleep的参数是一个时间,单位是ms
//计算机算的快,常用的就是ms,us,ns这结果单位
//sleep(1000)就是要休眠1000ms,除非遇到一些异常打断休眠,
//所以为了防止这样的情况发生,我们要套上try catch的壳
//这里还有一个经典面试题:谈谈Thread的run和start的区别
//使用run,可以看到只是在打印thread,没有打印main
//直接调用run,并没有创建新的线程,而是在之前的线程中,执行了run里的内容
//使用start,则是创建新的线程,新的线程里面会调用run,新线程和旧线程之间是并发执行的关系
}
}
普通程序一般都是按照代码执行的顺序,所以一般会卡在第一个死循环的地方,然后一直在那个地方运行
我们写一个简单的main方法的时候
class MyThread extends Thread{
public static void main(){
System.out.println("我叫葛玉礼");
}
}
这里虽然我们并没有手动创建其他线程,但是Java进程在运行的时候,内部也会创建出多个线程.
运行这个程序,操作系统就会创建一个Java进程,在这个Java进程里就会有一个线程调用main方法,这个这个线程我们就称为主线程
谈到多进程的时候,我们经常会谈到"父进程"“子进程”
进程A里面创建了进程B
A是B的进程,B是A的子进程
但是,在多线程里面,没有"父线程""子线程"这种说法
但是仍然认为线程之间的地位是对等的
创建线程
法一-创建Thread子类
- 继承Thread类
class MyThread extends Thread {
public void run(){
System.out.println("此处为线程执行的语句");
}
}
首先我们要继承Thread类,并且重写其中的run方法,在这个run方法中,就描述着我们的线程要执行的内容.
- 创建该线程的实例
Thread t = new MyThread();//向上转型
我们创建一个线程实例出来,但此时,该线程还没有塞入任务链表中参与系统调度,我们还差最后一步
- 调用Thread中的start方法启动线程
t.start();//线程此时开始运行
法二-实现Runnable接口
- 实现Runnable接口
class MyRunnable implements Runnable {
public void run(){
System.out.println("这里是线程运行的代码")
}
}
- 创建Thread的实例,并且在调用Thread的构造方法时将实现Runnable接口的MyRunnable对象作为target的参数.
Thread t = new Thread(new MyRunnable());
- 调用start方法
t.start//线程开始运行.
我们继承Thread类,可以直接使用this来表示当前线程对象的引用.
但是实现Runnable接口的话,this表示的就是MyRunnable的引用.需要使用Thread.currentThread()来表示当前线程对象的引用.
法三-匿名内部类创建Thread子类对象
//使用匿名内部类创建Thread子类对象
Thread t1 = new Thread() {
public void run(){
System.out.println("使用匿名内部类创建Thread子类对象");
}
};
法四-匿名内部类创建Runnable子类对象
Thread t2 = new Thread(new Runnbale() {
public void run(){
System.out.println("使用匿名内部类创建Runnbale子类对象");
}
});
法五-lambda表达式创建Runnable子类对象
Thread t2 = new Thread(() -> {
System.out.println("使用匿名内部类创建Thread子类对象");
});
Thread的run和start的区别
package thread;
/**
* @author Gremmie102
* @date 2022/7/21 9:15
* @purpose : 关于多线程的一些代码,创建线程的第一种方法
*/
class MyThread extends Thread{
public void run(){
//这个run方法重写的目的,是为了明确,咱们新创建出来的线程要干啥活
while(true){
System.out.println("hello thread!");
try{
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Demo1 {
public static void main(String[] args) {
//创建一个线程
//Java中创建线程,离不开一个关键的类.Thread
//其中一种比较朴素的创建方式,是写一个子类,继承Thread,重写其中的run方法
//光创建了这个类,还不算创建线程,还得创建实例
Thread t = new MyThread();//向上转型的写法,可写可不写
t.start();//这才是真正开始创建线程
//(在操作系统内核中,创建出对应线程的PCB,然后让这个PCB加入到系统链表中,参与调度)
//在这个代码中,虽然先启动的线程,后打印的hello main
//但是实际执行的时候,看到的确是,先打印了hello main ,后打印了hello thread!
//这是因为:
// 1.每个线程是独立的执行流,
//main对应的线程是一个执行流,MyThread是另一个执行流.
//这两个执行流之间是并发的执行关系(并发+并行)
//2.此时两个线程执行的先后顺序,取决于操作系统调度器具体实现
//(程序员可以把这里的调度规则,简单得视为"随机调度")
//System.out.println("hello main");
//虽然反复运行了多次,好像结果都是一样的,但我们的顺序仍然是不可确定的
//当前看到的先打印main,大概率是受到创建线程自身的开销影响的.
//哪怕连续运行1000次main在前,也不能保证1001次的时候不出现thread在前!
//*编写多线程代码的时候,一定要注意到!
//默认情况下,多个线程的执行顺序,是"无序",是"随机调度"的
//进程的退出码为:exit code 0
//操作系统中用进程的退出码来表示"进程的运行结果"
//使用0表示进程执行完毕.结果正确
//使用非0表示进程执行完毕,结果不正确
//还有个别情况main还没返回呢,进程就崩溃,此时返回的值很可能是一个随机值
//我们可以想办法让这个进程别结束得那么快,好看清楚这个进程
//我们可以搞两个si循环
while(true){
System.out.println("hello main");
try{
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//运行之后我们就可以发现,main和thread交替打印
//每一波打印机个,切换到下一波是什么时候,都是不确定的,都是由调度器控制的
//在JDK里提供了一个jconsole这样的工具,可以看到Java进程里的线程详情.
//在jdk/bin/jconsole.exe
//启动之后先选择我们要看哪个Java进程
//少数情况打开jconsle时,可能不显示这里的进程列表.
//这个时候退出,然后右键管理员运行.
//在标签页中选择线程,往下翻,在左下角部分可以查询到当前Java进程中的线程信息了
//刚才的死循环代码,打印的太多太快
//有的时候不希望它们打印的这么快(不方便来观察)
//我们可以用sleep()来让线程适当的"休息一下"-->指定让线程摸一会鱼,不要上cpu干活
//使用Thread.sleep();的方法进行休眠
//sleep时Thread的静态成员方法
//sleep的参数是一个时间,单位是ms
//计算机算的快,常用的就是ms,us,ns这结果单位
//sleep(1000)就是要休眠1000ms,除非遇到一些异常打断休眠,
//所以为了防止这样的情况发生,我们要套上try catch的壳
//这里还有一个经典面试题:谈谈Thread的run和start的区别
//使用run,可以看到只是在打印thread,没有打印main
//直接调用run,并没有创建新的线程,而是在之前的线程中,执行了run里的内容
//使用start,则是创建新的线程,新的线程里面会调用run,新线程和旧线程之间是并发执行的关系
}
}
我们再来观察这段代码,我们在start之后,主线程和thread(我们自己定义的线程)一起被系统调度执行.那么这里两个线程都是有个无限循环执行的任务.这里就可以很容易看出系统调度线程的过程
start可以看到两个线程并发的执行,两组打印时交替出现的
如果我们直接调用run,此时并没有创建新的线程,而只是在之前的线程中,执行了run中的内容
我们使用start,则是创建新的线程,新的线程里面会调用run,新线程和旧线程之间时并发执行的关系.
那么使用多线程带来的好处是啥呢?
hi用多线程,能够更加充分得利用CPU多和资源
同一项任务,我们利用多线程就可以更快的执行完
package thread;
/**
* @author Gremmie102
* @date 2022/7/21 11:41
* @purpose :
*/
public class Demo6 {
//1.单个线程,串行的,完成10亿次自增.
//2.两个线程,并发的,完成10亿次自增
private static final long COUNT = 20_0000_0000;
private static void serial(){
//需要把方法执行的时间给记录下来
//记录当前的毫秒级时间戳
long beg = System.currentTimeMillis();
int a = 0;
for (long i=0;i<COUNT;i++){
a++;
}
a = 0;
for (long i = 0;i < COUNT;i++){
a++;
}
long end = System.currentTimeMillis();
System.out.println("单线程消耗时间:"+(end-beg)+"ms");
}
private static void concurrency(){//并发
long beg = System.currentTimeMillis();
Thread t1 = new Thread(()->{
int a = 0;
for (long i =0;i<COUNT;i++){
a++;
}
});
Thread t2 = new Thread(()->{
int a = 0;
for (long i =0;i<COUNT;i++){
a++;
}
});
t1.start();
t2.start();
try{
t1.join();//这里的join是等待线程结束,等待线程把自己的run方法执行完
//在主线程中调用t1.join,意思就是让main线程等t1执行完
t2.join();
//t1 t2是会开始执行,同时不等t1 t2执行玩,main线程就往下走了,于是就结束计时
//此处的即使,是为了衡量t1和t2的执行时间,正确的做法应该是等到t1和t2都执行完再计时
} catch (InterruptedException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("单线程消耗时间:"+(end-beg)+"ms");
}
public static void main(String[] args) {
// serial();
concurrency();
}
}
如上代码,我们可以通过单线程和多线程的对比发现,运行时间有很大的改善
那么我们注意到了这个join()的方法,这里我们在前一篇博客中有讲到,join就是等待线程结束(等待线程把自己的run方法执行完),在主线程中调用t1.join,意思就是让main线程等待t1执行完.这两个join操作谁先谁后其实并不影响.
针对这里的先后顺序并不影响的原因,我做一下解释,因为如果是先t1先join,t2后join.
那么主线程就要先等待t1线程执行完,这时main线程是在阻塞状态的,t2此时和t1并发执行,那么当t1执行完之后,主线程又可以继续执行了,这时又运行到了下一条t2的join,主线程又要停下来等待了,等到t2线程执行完之后,主线程再继续.
那我们把t1和t2的顺序反过来之后,也是如此,都是main线程等待t1t2都运行结束之后再运行,在这之前t1t2都是并发执行的.
那么又有问题了,t2可以等待t1执行完再去执行吗,可以的话代码怎么实现呢?
很简单,只要在t2的run方法中写上t1.join就可以了.
如果我们没有加上t1.join和t2.join,这时虽然某种意义上是并发的,但消耗的时间其实并不是单个线程的一半,比如单个线程串行执行,消耗的时间是1300ms,那么两个线程并发执行确是800ms,因为这里
- 创建线程本身也是有开销的
- 两个线程在CPU上不一定是纯并行,也可能是并发,一部分时间里面是并行了,一部分时间里是并发了.
- 线程的调度,也是有开销的(当前场景中,开销应该是非常小的)
多线程的使用场景
- 在CPU密集型场景
代码中大部分工作,都是在使用CPU进行运算
使用多线程,就可以更好的利用CPU多核计算资源,从而提高效率
- 在I/O密集型场景
I input 输入
O output 输出
读写硬盘,读写网卡…这些操作都算I/O
在这些场景里,就需要花很大时间来等待
像这些IO操作,都是几乎不消耗CPU就能完成快速读写数据的操作
既然CPU在摸鱼,就可以给他找点活干,也可以使用多线程,避免COU过于闲置
希望能够帮助到你
















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











