







windows.h库实现多线程
单线程矩阵乘法
每次矩阵乘法计算过程包含一个三重循环过程,这将带来 O($ n^3 $) 的时间复杂度
#单线程实现N*N矩阵乘法
def mul(A=[],B=[]):
n=len(A)
C=[[0]*n for row in range(n)]
for m in range(n):
for i in range(n):
for j in range(n):
C[m][i]+=A[i][j]*B[j][i]
return C;
多线程矩阵乘法
矩阵乘法是一个重复操作过程,即将矩阵 A 的不同行与矩阵 B 的不同列相乘,且各个相乘结果之间不存在互相依赖关系,因此可以利用多线程计算来对矩阵乘法的计算过程进行加速,理论上,采用nxn个线程时,可以达到 O(n) 的性能
代码实现
#include <windows.h>
#include <iostream>
#include <ctime>
#define N 1000 //将矩阵大小固定为1000*1000
#define MAX_THREADS 10
using namespace std;
struct MYDATA //用于传递多个参数给线程函数
{
int begin, end;
int* A, * B, * C;
};
DWORD ThreadProc(LPVOID IpParam)//线程函数,用于计算矩阵乘法
{
MYDATA* pmd = (MYDATA*)IpParam;
int* A = pmd->A, * B = pmd->B, * C = pmd->C;
int begin = pmd->begin, end = pmd->end;
for (int index = begin; index < end; index++)
{
int i = index / N, j = index % N;
C[i * N + j] = 0;
for (int n = 0; n < N; n++)
{
C[i * N + j] += A[i * N + n] * B[n * N + j];
}
}
return 0;
}
int A[N * N], B[N * N], C[N * N], revB[N * N];
double rate[MAX_THREADS];
double Rate;
int main()
{
for (int i = 0; i < N * N; i++)
{
A[i] = rand();
B[i] = rand();
}
int threads[MAX_THREADS] = {1, 2, 4, 8,16,32,64,100,500,1000 };
for (int i = 0; i < MAX_THREADS; i++)
{
int m = threads[i];
clock_t start, end;
start = clock();
HANDLE hThread[N];//初始化临界区
static MYDATA mydt[N];
int temp = (N * N) / m;
for (int i = 0; i < m; i++)//创建线程
{
mydt[i].A = A, mydt[i].B = B, mydt[i].C = C;
mydt[i].begin = i * temp, mydt[i].end = i * temp + temp;
if (i == m - 1)//最后一个线程
{
mydt[i].end = N * N;
}
hThread[i] = CreateThread(NULL, 0, (LPTHREAD_START_ROUTINE)ThreadProc, &mydt[i], 0, NULL);
}
WaitForMultipleObjects(m, hThread, TRUE, INFINITE);
end = clock();
cout << m << "个线程时运行时间为" << (double)(end - start) / CLOCKS_PER_SEC << "s" << endl;
rate[i] = (double)(end - start);
Rate = rate[0] / rate[i];
cout << "加速比:" << Rate << endl;
}
}
运行结果:
| 线程数 | 运行时间 | 加速比 |
|---|---|---|
| 1 | 3.717 s | 1 |
| 2 | 1.282 s | 2.5081 |
| 4 | 0.811 s | 4.58323 |
| 8 | 0.524 s | 7.09351 |
| 16 | 0.427 s | 8.70492 |
| 32 | 0.456 s | 8.15132 |
| 64 | 0.472 s | 7.875 |
| 100 | 0.011 s | 337.909 |
| 500 | 0.045 s | 82.6 |
| 1000 | 0.184 s | 20.2011 |
 |
优化
数据类型:内存中二维数组是以行优先进行存储的,因此可以认为一维数组在内存方面和二维数组没区别
数据大小:这里固定为1000*1000的矩阵
cache:
发现在代码块中
C[i * N + j] += A[i * N + n] * B[n * N + j];
对于矩阵B的访问存在严重的cache命中率问题,因此可以对矩阵B做一个映射,将B[n * N + j]映射到revB[j * N + n]构造矩阵revB代替B进行矩阵乘法,从而提高cahe命中率
for (int index = 0; index < N; index++)
{
int i = index / N, j = index % N;
revB[i * N + j] = B[j * N + i];
}·
代码实现
#include <windows.h>
#include <iostream>
#include <ctime>
#define N 1000
#define MAX_THREADS 10
using namespace std;
struct MYDATA //用于传递多个参数给线程函数
{
int begin, end;
int* A, * B, * C;
};
DWORD ThreadProc(LPVOID IpParam)//线程函数,用于计算矩阵乘法
{
MYDATA* pmd = (MYDATA*)IpParam;
int* A = pmd->A, * B = pmd->B, * C = pmd->C;
int begin = pmd->begin, end = pmd->end;
for (int index = begin; index < end; index++)
{
int i = index / N, j = index % N;
C[i * N + j] = 0;
for (int n = 0; n < N; n++)
{
/* C[i * N + j] += A[i * N + n] * B[n * N + j];*/
C[i * N + j] += A[i * N + n] * B[j * N + n];
}
}
return 0;
}
int A[N * N], B[N * N], C[N * N], revB[N * N];
double rate[MAX_THREADS];
double Rate;
int main()
{
for (int i = 0; i < N * N; i++)
{
A[i] = rand();
B[i] = rand();
}
for (int index = 0; index < N; index++)//对矩阵B做映射
{
int i = index / N, j = index % N;
revB[i * N + j] = B[j * N + i];
}
int threads[MAX_THREADS] = {1, 2, 4, 8,16,32,64,100,500,1000 };
for (int i = 0; i < MAX_THREADS; i++)
{
int m = threads[i];
clock_t start, end;
start = clock();
HANDLE hThread[N];//初始化临界区
static MYDATA mydt[N];
int temp = (N * N) / m;
for (int i = 0; i < m; i++)//创建线程
{
mydt[i].A = A, mydt[i].B = revB, mydt[i].C = C;
mydt[i].begin = i * temp, mydt[i].end = i * temp + temp;
if (i == m - 1)//最后一个线程
{
mydt[i].end = N * N;
}
hThread[i] = CreateThread(NULL, 0, (LPTHREAD_START_ROUTINE)ThreadProc, &mydt[i], 0, NULL);
}
WaitForMultipleObjects(m, hThread, TRUE, INFINITE);
end = clock();
cout << m << "个线程时运行时间为" << (double)(end - start) / CLOCKS_PER_SEC << "s" << endl;
rate[i] = (double)(end - start);
Rate = rate[0] / rate[i];
cout << "加速比:" << Rate << endl;
}
}
运行结果:
| 线程数 | 运行时间 | 加速比 |
|---|---|---|
| 1 | 2.543 s | 1 |
| 2 | 1.281 s | 1.98517 |
| 4 | 0.702 s | 3.62251 |
| 8 | 0.437 s | 5.81922 |
| 16 | 0.374 s | 6.79947 |
| 32 | 0.383 s | 6.63969 |
| 64 | 0.391 s | 6.50384 |
| 100 | 0.013 s | 195.615 |
| 500 | 0…022 s | 115.591 |
| 1000 | 0.19 s | 13.3842 |
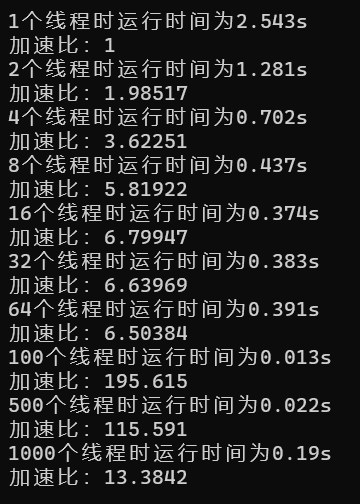 |
相比优化之前,速度提升明显。
查看加速比,发现采用多线程加速矩阵乘法效果显著,加速比最高可达300以上。
但加速比并未一直随线程数增多而提升,没有达到理论上采用nxn个线程时 O(n) 的性能。
甚至当线程数过多时,所用时间要远远大于单线程(10000个线程耗费20分钟没有跑出结果)。
分析
1.将创建线程的时间统计在内,而创建线程的耗时相比于简单的进行一行乘以一列的乘加运算,耗时要高很多。
2.线程数超过了操作系统所能同时执行的最大数量,因此每个线程都需要操作系统进行调度执行,调度花费的时间要远超执行矩阵行列乘加运算的用时。
3.线程数过多会导致线程之间频繁地切换,从而增加了上下文切换的开销,降低了计算效率
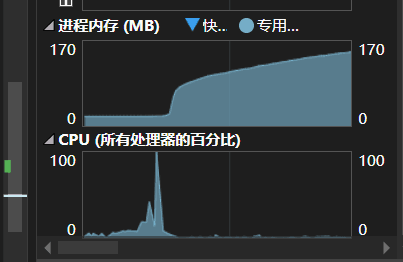
4.查看cpu以及进程内存,可以发现大部分耗费发生在了内存交换上,而不是cpu运算。
结论
多线程加速矩阵乘法可以显著提高计算速率,但是线程数的选择要根据具体情况进行调整,如果线程数过少,则无法充分利用CPU资源;如果线程数过多,则会导致上下文切换频繁,从而降低计算效率
















 1535
1535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











