






前言
来到实验二了,稍微上了点强度,网上没找到合适的代码,最后还是自己根据实验一的代码改出来了。这里着重讲一下代码的理解,希望同学们自己看懂后也会改的来,并且最好把我的矩阵划分方式改成按行分配线程。考虑到一些潜在的风险,就不提供完整的东西了,就下面给出一些我的参考代码供大家更好地学习并行计算。
免责声明: 注意:代码等仅供同学们加深对课程知识点的理解,严禁抄袭,要是查重(不确定有没有)什么的被老师抓到了后果自负
算法介绍
仿照实验一的代码,给线程分配任务还是通过结构体的方式,不过实验一里每个线程是计算级数的一部分,而本实验中,每个线程是计算矩阵的一部分。
然后自然就想到将矩阵分成若干块,为了便于划分,规定使用9个线程,然后输入矩阵规模都是3的倍数,可以整除(其实只要在我划分的代码那稍微改改,就可以不用保证一定要3的倍数,当作任务交给读者了)
然后因为计算矩阵幂次,所以主函数里循环cnt次,每次进行矩阵乘法时,将要计算的矩阵分块,把范围分配给多线程,分别计算。由于每次计算依赖前一次计算的结果,所以每次矩阵乘法后都要让所有线程同步一下,使用下面这个代码,就可以让所有线程同步一下,再进行下一次的矩阵乘法。
pthread_join(pid[i], NULL);
至于矩阵乘法怎么算,就是直接三个for循环那样枚举就好了,流程图可看:
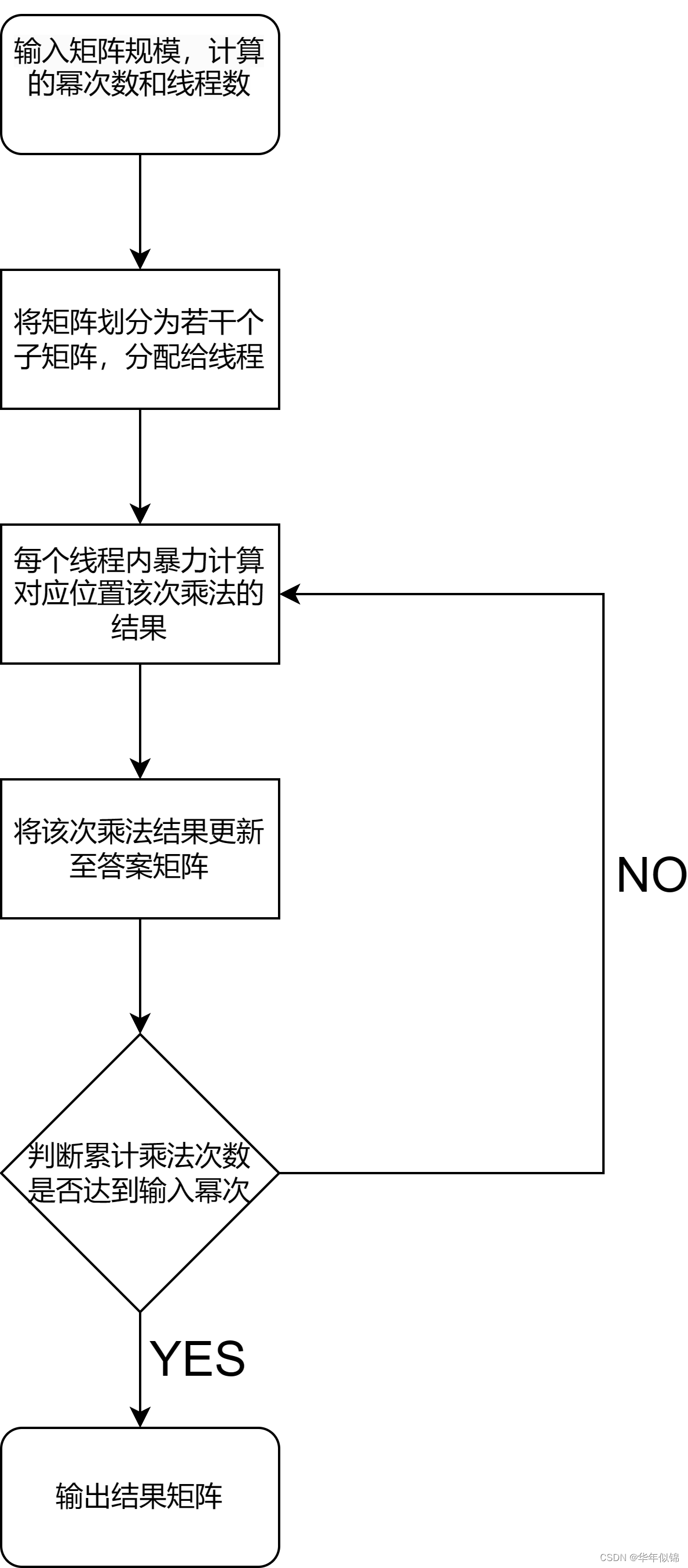
详情看下面代码:
并行程序:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define ll long long
const int maxn = 1e3 + 10;
const int mod = 998244353;
pthread_mutex_t mutex[maxn][maxn]; // 互斥变量
ll res[maxn][maxn]; // 结果矩阵
ll fuzhi[maxn][maxn]; // 临时存储过程矩阵
ll arr[maxn][maxn]; // 输入矩阵(随机赋值)
int n, mi, threads, step;
int min(int x, int y) {
return (x > y) ? y : x;
}
typedef struct Args {
int rowbegin;
int rowend;
int colbegin;
int colend;
} Args;
void *cal(void *_arg) {
Args *arg = (Args *)_arg;
for (int i = arg-> rowbegin; i <= arg->rowend; i++) {
for (int j = arg->colbegin; j <= arg->colend; j++) {
ll my_res = 0;
for (int k = 1; k <= n; k++)
my_res = (my_res + fuzhi[i][k] * arr[k][j]) % mod;
res[i][j] = my_res; // 修改结果矩阵中对应部分值
}
}
return NULL;
}
int main(int argc, char *argv[]) {
srand(time(0));
if (argc != 4) {
printf("Parameters error: N mi threads!\n");
exit(1);
}
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
pthread_mutex_init(&mutex[i][j], NULL); // 初始化互斥变量
// 处理输入参数
n = atof(argv[1]);
mi = atol(argv[2]);
threads = 9;
step = n / 3; // 单个线程处理子块的边长
//初始化矩阵相关信息
for (int i = 1; i <= n; i++)
res[i][i] = 1;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
arr[i][j] = rand() % 10;
// for (int i = 1; i <= n; i++) {
// for (int j = 1; j <= n; j++)
// printf("%lld ", arr[i][j]);
// printf("\n");
// }
Args *arg;
pthread_t *pid;
pid = (pthread_t *)malloc(threads * sizeof(pthread_t));
for (int cnt = 1; cnt <= mi; cnt++) {
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
fuzhi[i][j] = res[i][j]; // 将上一次的结果存储到fuzhi矩阵中
for (int i = 0; i < threads; i++) {
arg = (Args *)malloc(sizeof(Args));
arg->rowbegin = (i / 3) * step + 1;
arg->rowend = (i / 3 + 1) * step;
arg->colbegin = (i % 3) * step + 1;
arg->colend = min((i % 3 + 1) * step, n);
// arg->rowbegin = 1;
// arg->rowend = n;
// arg->colbegin = 1;
// arg->colend = n;
pthread_create(&pid[i], NULL, cal, (void *)arg);
}
for (int i = 0; i < threads; i++)
pthread_join(pid[i], NULL);
}
// 输出结果
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++)
printf("%lld ", res[i][j]);
printf("\n");
}
free(pid);
return 0;
}
注意
由于测试的矩阵可以很大,所以手动输入过于麻烦,我初始化就直接用rand()函数随机赋值。给结构体赋值那一块我注释掉的 1,n是为了检测并行程序单线程执行的时间跟串行对比一下是否有误。
还有,我这样写相当于把线程数写死了是9个,所以测试脚本里面第三个参数其实没用,但是也得写9,不然main()函数里面前面的判断语句会提前退出。
串行代码:
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#define ll long long
const int maxn = 1e3 + 10;
const int mod = 998244353;
int n, mi;
ll res[maxn][maxn]; // 结果矩阵
ll tem[maxn][maxn]; // 临时存储过程矩阵
ll arr[maxn][maxn]; // 输入矩阵(随机赋值)
int main(int argc, char* argv[]) {
srand(time(0));
n = atof(argv[1]);
mi = atof(argv[2]);
for (int i = 1; i <= n; i++) // 初始化n * n矩阵
for (int j = 1; j <= n; j++)
arr[i][j] = rand() % 10;
for (int i = 1; i <= n; i++)
res[i][i] = 1; // 初始化结果为单位矩阵
while (mi--) {
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++) {
// tem[i][j] = 0;
// for (int k = 1; k <= n; k++)
// tem[i][j] = (tem[i][j] + res[i][k] * arr[k][j]) % mod;
tem[i][j] = res[i][j];
}
for (int i = 1; i <= n; i++)
for (int j = 1; j<= n; j++) {
ll val = 0;
for (int k = 1; k <= n; k++)
val = (val + tem[i][k] * arr[k][j]) % mod;
res[i][j] = val;
}
}
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++)
printf("%lld ", res[i][j]);
printf("\n");
}
}
bash脚本(注意输入都是3的倍数保证恰好划分)
#!/bin/bash
touch run.log
time yhrun -p thcp1 -n 1 -c 9 ./bing.o 9 500 9 &> run.log
time yhrun -p thcp1 -n 1 -c 9 ./bing.o 51 200 9 &> run.log
time yhrun -p thcp1 -n 1 -c 9 ./bing.o 99 100 9 &> run.log
time yhrun -p thcp1 -n 1 -c 9 ./bing.o 99 200 9 &> run.log
time yhrun -p thcp1 -n 1 -c 9 ./bing.o 501 20 9 &> run.log
time yhrun -p thcp1 -n 1 -c 9 ./bing.o 501 50 9 &> run.log
time yhrun -p thcp1 -n 1 -c 9 ./bing.o 999 10 9 &> run.log
然后就是正常提交任务
yhbatch -p thcp1 -n 1 ./bing.sh
之后就是写报告咯
















 735
735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









