








🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
基本信息
标题: Sign Language Transformers: Joint End-to-end Sign Language Recognition and Translation
作者: Necati Cihan Camgo, Oscar Kollerq, Simon Hadfield and Richard Bowden
发表: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
DOI: 10.1109/CVPR42600.2020.01004

摘要
先前关于手语翻译的研究表明,拥有中级手语词汇表示(有效识别单个手势)可以显著提高翻译性能。事实上,当前最先进的翻译技术需要词汇级别的标记化才能运行。我们提出了一种基于Transformer的新型架构,该架构可以联合学习连续手语识别和翻译,并且可以端到端地训练。 这是通过使用连接主义时序分类(CTC)损失将识别和翻译问题绑定到单个统一架构中实现的。这种联合方法不需要任何真实时间信息,同时解决了两个相互依赖的序列到序列学习问题,并导致了显著的性能提升。
我们评估了我们的方法在具有挑战性的RWTH-PHOENIX-Weather-2014T(PHOENIX14T)数据集上的识别和翻译性能。我们报告了我们的手语Transformer实现的最先进的手语识别和翻译结果。我们的翻译网络在签视频到口语和词素到口语翻译模型方面均表现优异,在某些情况下性能翻倍(9.58 vs. 21.80 BLEU-4得分)。我们还分享了使用Transformer网络进行其他几个文本到文本手语翻译任务的新基线翻译结果。
手语识别与手语翻译
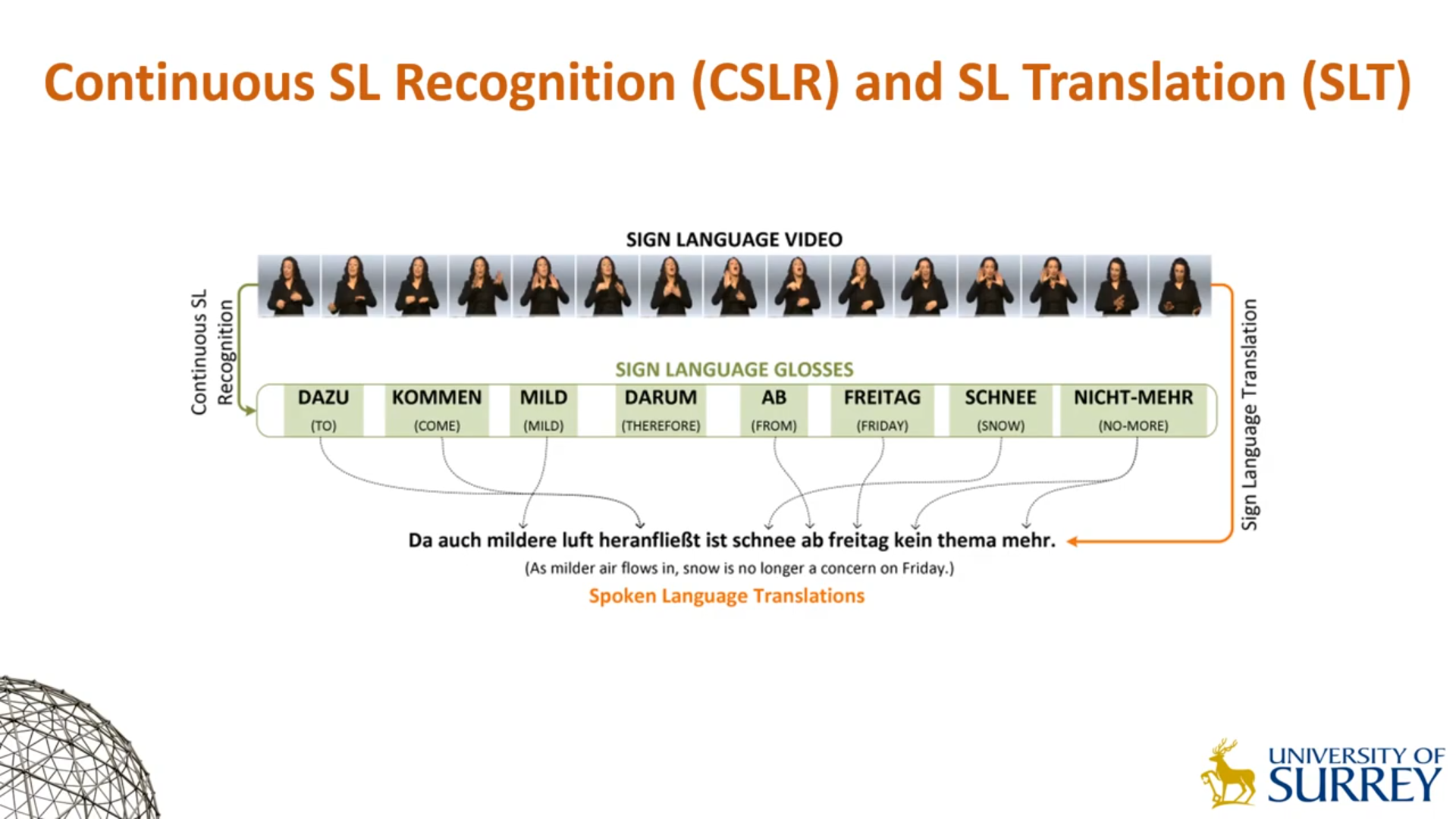
- 孤立手语识别: Sign Language Video -> Single Sign Language Gloss
- 连续手语识别: Sign Language Video -> Continuous Sign Language Glosses
- 手语翻译: Sign Language Video -> Spoken Language Translations
以往工作与当前工作
Sign2Text
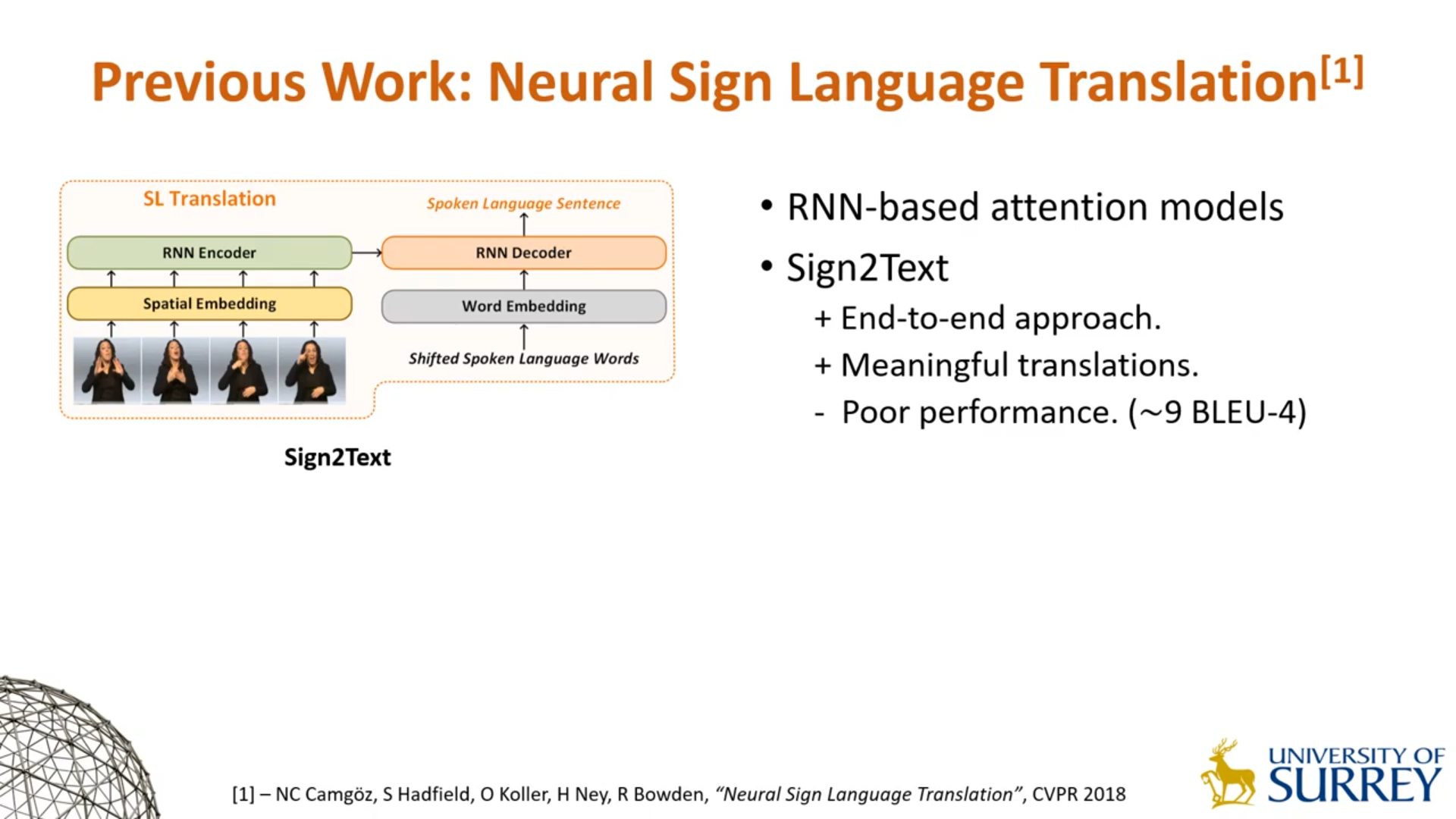
直接建模手语视频到自然语言文本的翻译任务。虽为端到端架构,但往往无法得到很好的性能。
Sign2Gloss2Text
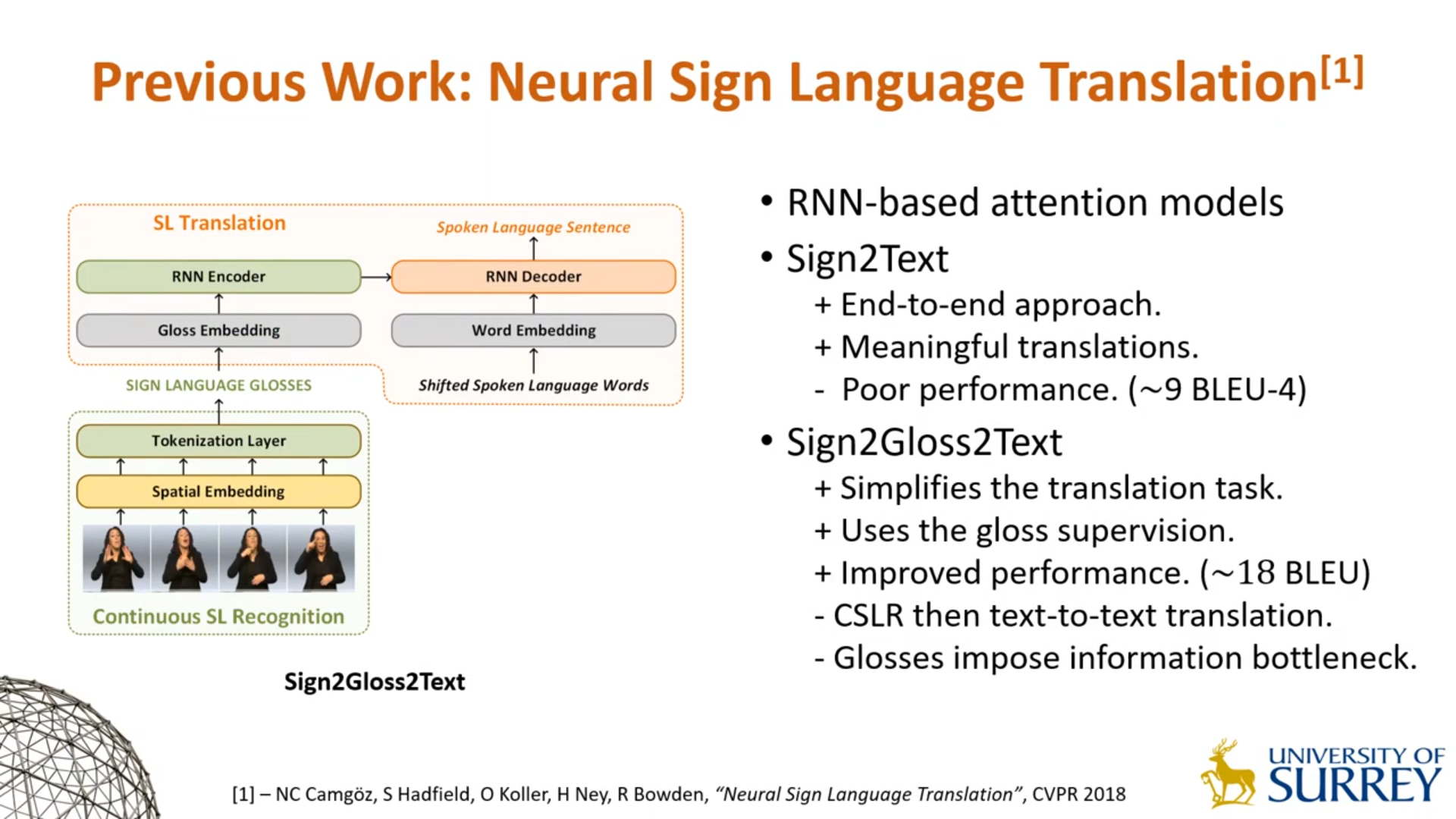
将手语视频到自然语言文本任务分解为手语视频到手语Gloss再到自然语言文本的两级任务。分解后的两级任务分别训练,能够利用到手语Gloss的标签,并且简化了翻译任务。由于显式得到了手语的Gloss,其无法进行端到端的训练,也带来了信息瓶颈。
Sign2(Gloss+Text)
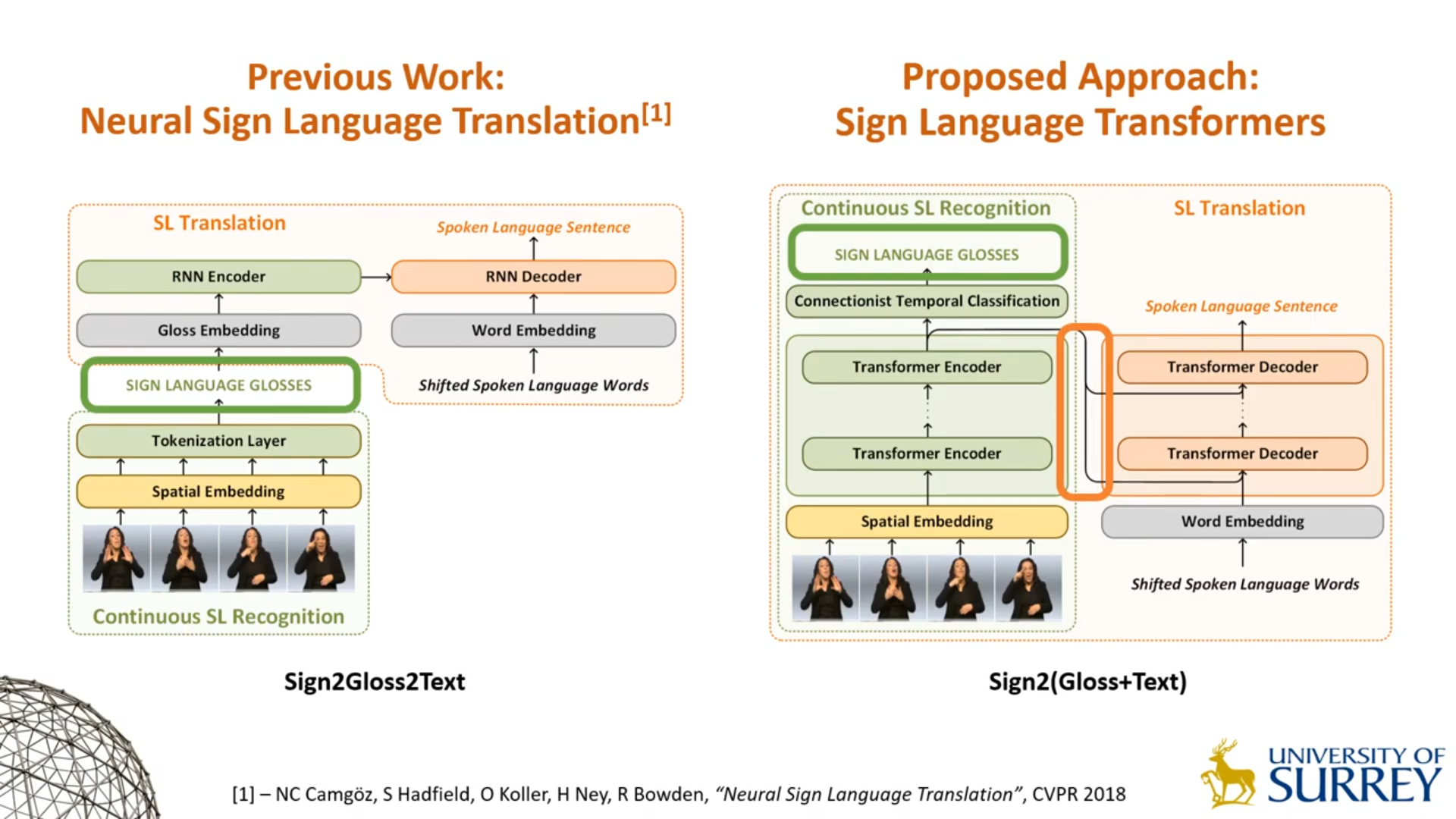
本文提出了一种新的架构,并不显式地获得手语Gloss,而是通过CTC损失来利用手语Gloss标签,并通过Transformer的Attention机制来捕获手语视频中的语义信息。
模型框架
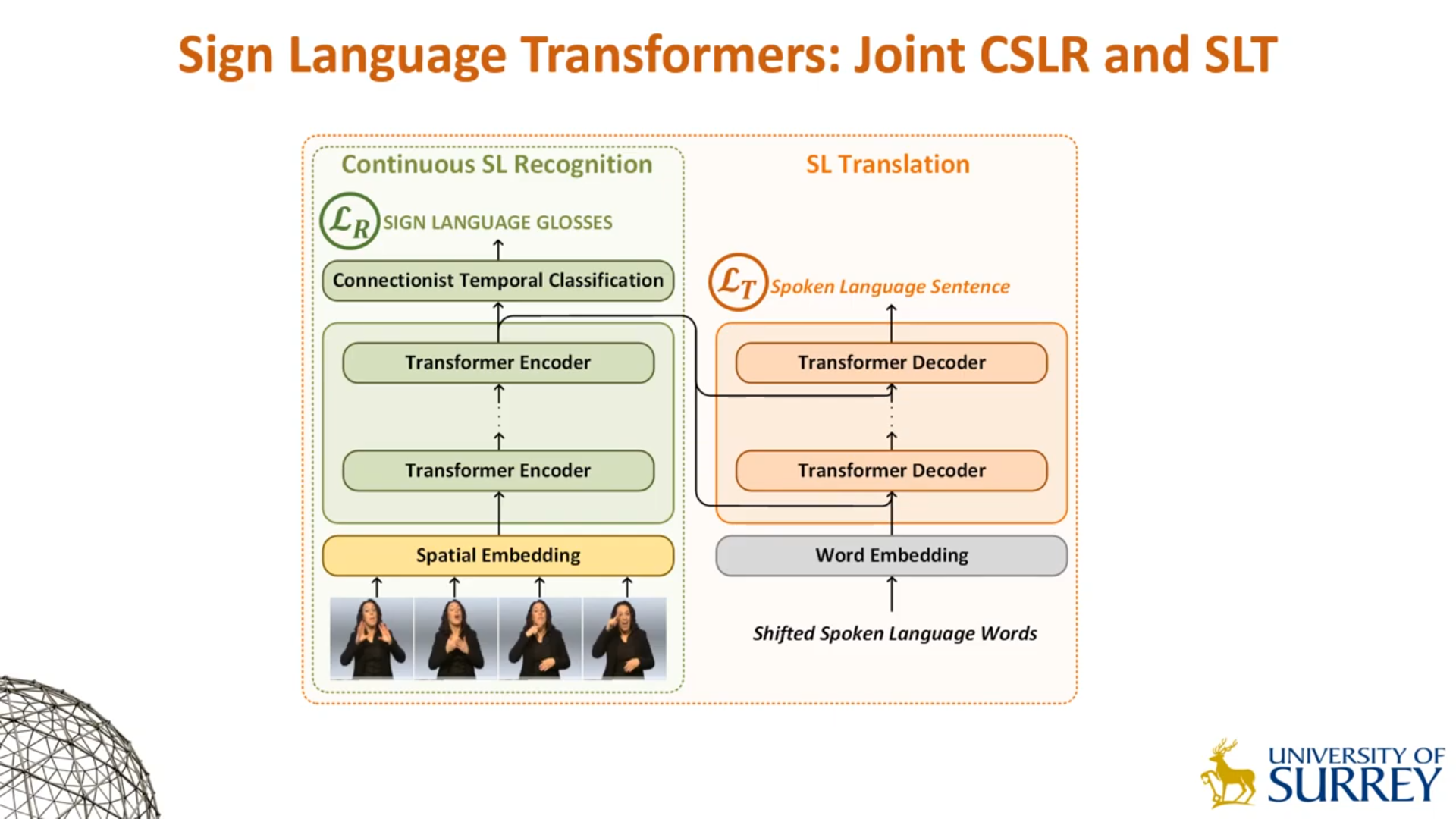
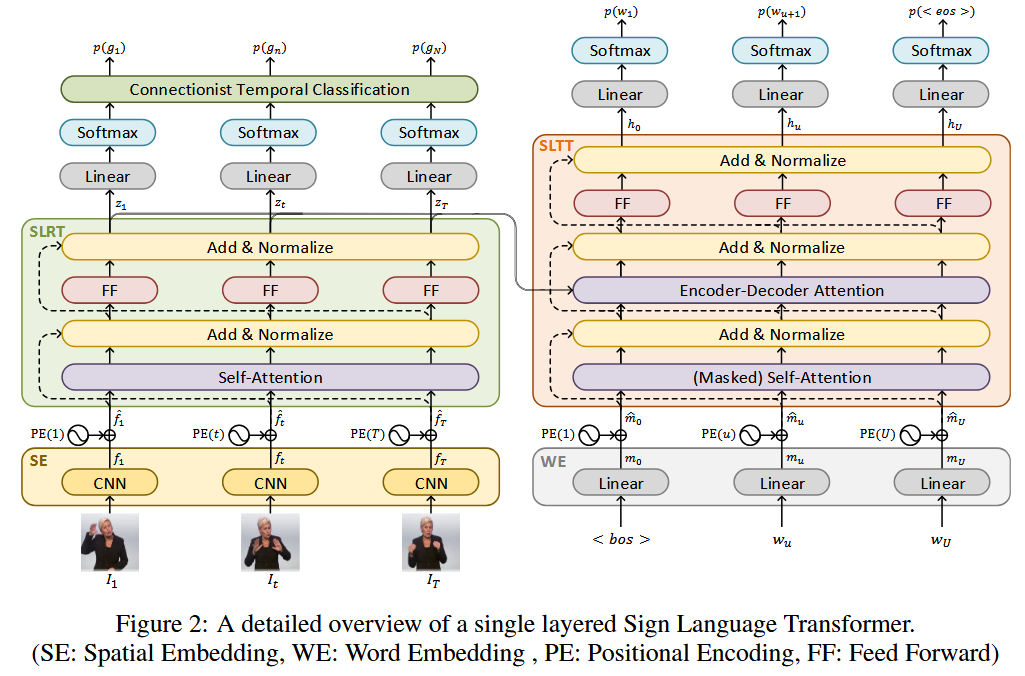
结构基本等同于Transformer,区别如下:
- Encoder端的输入替换为了视频帧,因此原本的Word Embedding层被替换为了Spatial Embedding层(本质上为预训练过的CNN)。
- Encoder端的输出通过一个Classifier利用CTC损失进行训练。
实验
实验设置
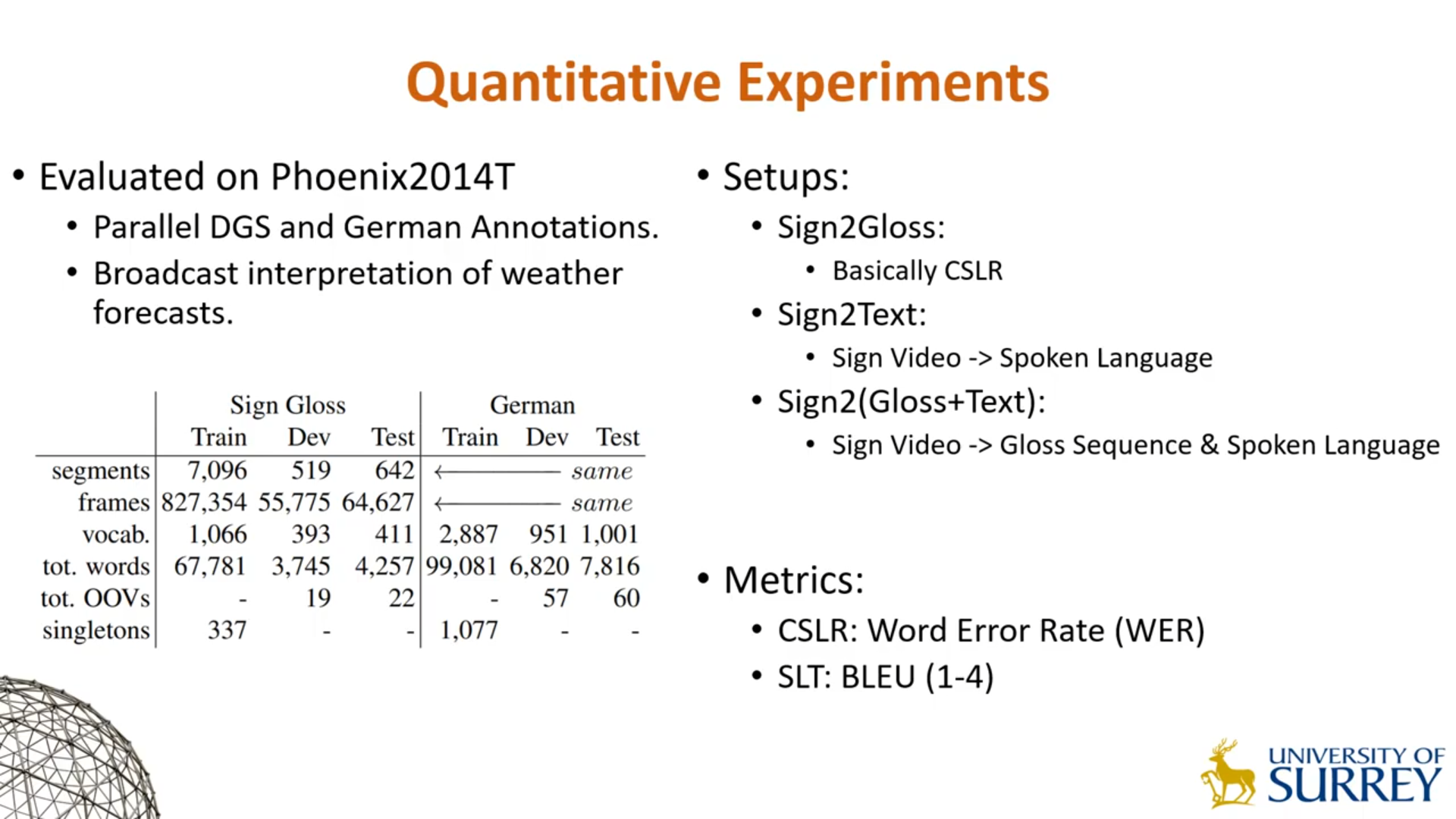
Spatial Embedding

在手语数据集上预训练过的CNN会比仅在ImageNet上预训练的CNN效果更好。

使用 Batch Norm 和 ReLU 也能带来显著的性能提升。
Loss Weight

识别损失(即CTC损失)并不仅仅作用于识别任务,它对下游的翻译任务也有帮助。因此适当的Loss权重选择对两个任务都有益。
主实验
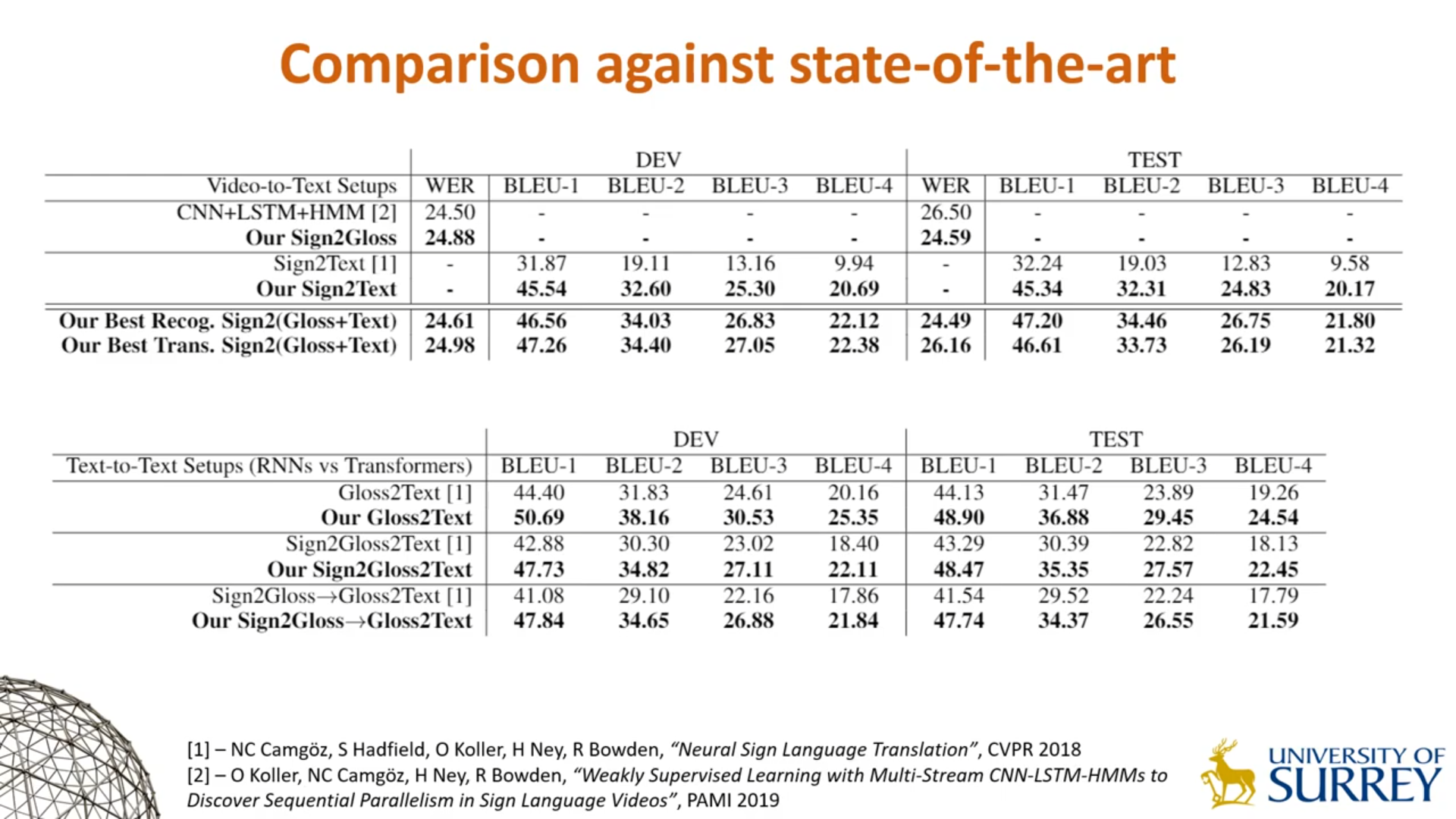
本文表现最佳的翻译模型Sign2(Gloss+Text)结果超越了以往被视为手语翻译任务伪上限的Gloss2Text的结果(以往的观点认为,Gloss2Text相当于Sign2Gloss2Text中Sign2Gloss任务已完美完成,因此将Gloss2Text的结果作为Sign2Text的性能上限),一定程度上证明了显式使用Gloss确实会引入信息瓶颈。
总结与展望

- 提出了一个端到端的基于Transformer的手语翻译架构,可以避开显示使用手语Gloss带来的信息瓶颈。
- 联合学习(同时使用CTC损失和翻译损失)有益于两个任务,Sign2Text能够取得比Gloss2Text更好的效果。
- Transformer结构表现良好,在翻译环节的各个任务中都取得了SOTA。
- 仍然需要Gloss标签来监督训练,未来将会关注更多的手语发音器官(除双手以外,还包含面部以及其他肢体部分)。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











