






一、动机:
1.原始RGB视频中含有大量显著的冗余信息,编码器无法专注于有效的关键信息。
(引入关键点检测信息)
为什么加入关键点:传统只是用RGB视频的方法鲁棒性不强,即换个背景或者换个手语者,模型性能就会大幅度下滑
挑战:1.手语数据较少 2.视频与文本之间存在模态gap
手语核心点:构建一个视觉编码器,将视频信息编码成 hidden representations
使用的技巧:
1.双流:输入为RGB视频与关键点特征图
2.双流交互:双向潜层连接(bidirectional lateral connection)、sign pyramid network with auxiliary supervision、frame-level self distillation

1. Dual Visual Encoder
使用HRNet(在COCO-WholeBody数据集上进行训练)提取关键点图。
使用两个独立的S3D分别提取RGB视频和关键点图的特征。
2.Information Interaction via Bidirectional Lateral Connection
因为运动模糊,关键点可能检测错误,因此需要原RGB视频的信息辅助。
原RGB视频中背景、手语者存在显著的冗余信息,需要关键点的信息辅助。
因此需要对原RGB视频与关键点图作information exchange。
3.Alleviate Data Scarcity via Sign Pyramid Network and Auxiliary Loss
Phoenix-2014T dataset 只有7,000 training samples, 训练一个鲁棒的机器翻译模型需要1million的平行语料。因此手语任务存在数据稀缺的难题。
因此文章使用金字塔特征抽取的方法提取双流的特征。
4.Frame-Level Self-Distillation
使用模型集成(ensemble)的平均预测作为“伪目标(pseudo-targets),然后针对两个不同的stream各自进行蒸馏训练,以使其预测更接近这些伪目标。
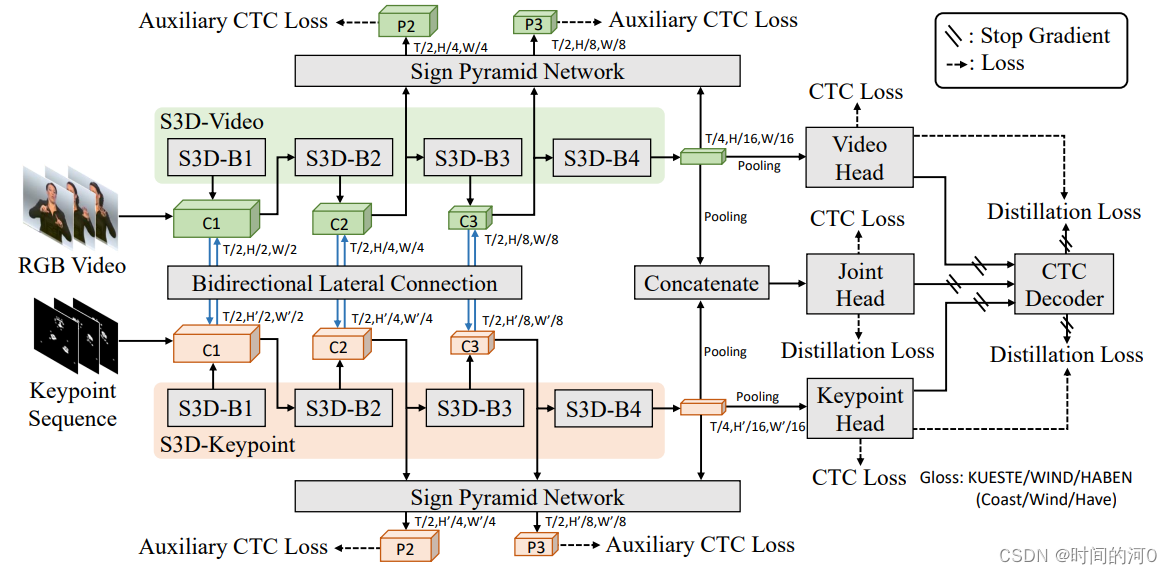
which consists of five parts: 1) a video encoder; 2) a keypoint sequence encoder; 3) a joint head; 4) a bidirectional lateral connection module; 5) two sign pyramid networks with auxiliary supervision, to model RGB videos and keypoint sequences.
一、Video Encoder: 使用S3D-Video的前4个block,获取密集的时序特征
1.输入Video:(T, H, W, 3)= (T, 224, 224, 3)
2.最后一个S3D的输出:将进行时间池化,输出大小为(T/4, 832)
3.head network:进一步提取时间上下文,包括a temporal linear layer, a batch normalization layer, a ReLU layer, as well as a temporal convolutional block which contains two temporal convolutional layers with a temporal kernel size of 3 and a stride of 1, a linear translation layer, and a ReLU layer。输出的特征叫gloss representation,大小为(T/4, 512)
4. 输出层:线性分类器、softmax。提取帧级别的gloss概率。
5.使用CTC loss优化分类器,![]() 。
。
二、Keypoint Encoder:
1. HRNet:生成关键点,42个手部关键点、68个面部关键点(只使用26个)、11个上半身关键点。即使用79个关键点。并使用热力图来表示关键点。
2.热力图表示为G,大小为(T, H’, W’, K),其中H’, W’代表每个热力图的空间分辨率。K代表总的关键点数量。
![]()
其中![]() 和
和![]() 代表第t帧中的第k个关键点。设定σ=4,H’=W’=112。
代表第t帧中的第k个关键点。设定σ=4,H’=W’=112。
3.关键点图的encoder与video的encoder相似,只是第一个卷积层被修改成适应关键点的输入。Video encoder和keypoint encoder的参数不共享。
4.使用CTC损失函数进行对齐优化,![]() 。
。
三、Bidirectional Lateral Connection:相同分辨率的特征图进行逐元素相加
1.S3D前三个block依次生成C1、C2和C3
2.由于video feature和keypoint feature的空间分辨率不同,因此使用spatially strided convolution 和 transposed convolution 来适应空间分辨率。
四、Joint Head and Late Ensemble
video encoder 和 keypoint encoder 都有自己独立的head network
1.将两个S3D输出的特征级联,作为 joint head network的输入。
2. joint head network结构与独立的head network一致。使用CTC loss进行监督,![]() 。
。
3.将三个head network预测的逐帧gloss概率进行平均,并使用CTC 解码生成gloss sequence。
五、Sign Pyramid Network:更好捕捉不同temporal span的gloss,有效的监督浅层学习有意义的表征。
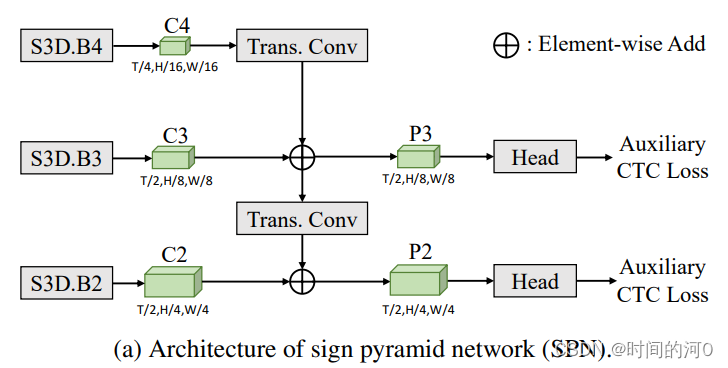
1.从S3D的后三层提取出C2、C3、C4特征(大小C4<C3<C2)
2.使用transposed convolution将小的特征图放大(both temporal and spatial dimensions),然后与大的特征图进行逐元素相加。得到P3、P2
3.P3、P2后接head模块,预测gloss,使用CTC loss,得到![]() 和
和![]()
SPN is dropped in the inference stage
六 Frame-Level Self-Distillation
Existing datasets only provide sentence-level gloss annotations, where gloss temporal boundaries are not labeled.
1.一旦CTC训练好,visual encoder 可以生成逐帧的gloss概率分布,从而可以预测近似的temporal boundaries。
2.使用三个头预测的平均概率分布来指导所有的头。
3.拉进伪标签与预测值的KL散度。
通过手语词典,可以知道每个gloss主要的动作,利用关键点图构建标签,即主要动作涉及的部位保留关键点,不是主要动作涉及的部位,筛掉。
训练一个关键点重要性识别器,输入为关键点图,输出为















 166
166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









