






作为一个小白对这些东西真的很陌生,查阅了很多资料看都是python的spark应用,对于javaAPI也搜到不是我想要的,,没办法只能慢慢试试了。
对于数据库的连接载入数据都不陌生,其实有载入就有载出。我的spark清洗数据引进的是csv格式的文件,第一次接触csv文件上网搜了搜csv,CSV(Comma-Separated Values,逗号分隔的值)是一种简单、实用的文件格式,用于存储和表示包括文本、数值等各种类型的数据。CSV 文件通常以 .csv 作为文件扩展名。这种文件格式的一个显著特点是:文件内的数据以逗号 , 分隔,呈现一个表格形式。CSV 文件已广泛应用于存储、传输和编辑数据。
那么引进完csv文件进行数据清洗完又是个什么东西呢,又该怎么设置导入到数据中,真是一点不懂,我觉的是要转成daraframe格式,然后又上gpt上搜了搜怎么导入到数据库中,之前学过可以先上传到hdfs上然后再hive上建表加载到hive表上经过sqoop传输到数据中,我想应该能直接传输到数据库中,最后也是成功了。
a为转换为dataframe之后的,localhos:3306需要替换成自己的数据库连接,hnsd是具体的数据库名字statci是你导入数据后起的表名字,下面root 和密码就不多说了。然后再数据库中是不需要我们提前建表的,我想这应该和dataframe的格式有关吧,搞了一会也终于是把清洗完的数据导入到数据库中了
a.write.format("jdbc")
.option("url","jdbc:mysql://localhost:3306/hnsd")
.option("dbtable","one")
.option("user","root")
.option("password","root123").save()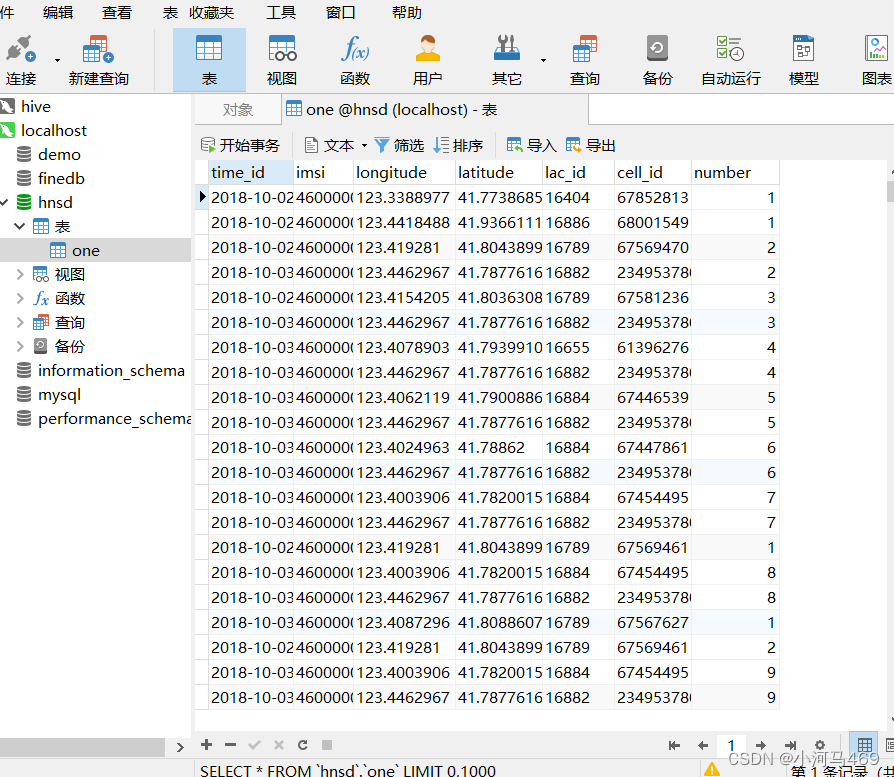















 1219
1219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









