






1.网页抓取库Urllib
库的导入:import urllib.request
- res=urllib.request.urlopen(url)#爬取网页源代码的方法,url参数用于指定要请求的路径(未指定data参数时,默认使用get方法)
- res.read().decode(‘utf-8’)#响应返回的内容
- print(type(res))#查看响应的类型
- print(res.status)#打印响应状态码
- print(res.getheaders())#打印请求头
- print(res.getheader(“Server”))#打印请求头中Server属性的值(表示服务端使用Web服务器是什么软件,如Tomcat、Nginx等)
2.网页解析库Beautifulsoup
库的引入:from bs4 import BeautifulSoup
Soup=BeautifulSoup(content,”html.parser”)#’html.parser’Python 的内置标准库,执行速度适中,文档容错能力强
result=soup.prettify() # 格式化输出
result=soup.title # 取title标签
result=soup.title.name # 取title标签名
result=soup.title.string # 取title标签内容,若标签下有多个内容时,返回None
result=soup.title.get_text() # 取title标签内容,若标签下有多个内容时,全部返回
result=soup.p # 取p标签,只会取第一个
result=soup.p[‘class’]# 取p标签的类
result=soup.a# 取a标签(第一个)
result=soup.a[‘href’]# 取a标签的href属性
//find – 返回符合查询条件的第一个标签
result=soup.find(name=“a”) # 指定标签名,同 soup.find(“a”)
result=soup.find(attrs={‘id’:‘link1’})# 指定属性
result=soup.find(text=‘Elsie’)# 指定内容
result=soup.find(name=‘p’,attrs={‘class’:‘story’})# 组合条件
result=soup.find_all(‘a’) # 取出所有a标签#find_all --list
result=soup.find_all(‘a’,limit=2) # limit限制返回标签数
result=soup.find_all(attrs={‘class’:‘sister’}) # 取出所有属性 class为sister的标签
result=soup.a.attrs # 获取a标签的所有属性
result=soup.select_one(‘.sister’) # 取出class为sister的第一个标签
//CSS选择器 – list
result=soup.select(‘.sister’) # 类选择器,取出所有class为siser的标签
result=soup.select(‘#link1’) # id选择器,取出所有id为link1的标签
result=soup.select(‘head title’) # 取head标签中的title标签
result=soup.select(‘title,.title’) # 取title标签 和 class为title的标签
result=soup.select(‘a[id=“link2”]’) # 取 a标签中 id为link2的标签
result=soup.select(‘.sister’)[0].get_text() # 取class为sister的第一个标签的内容 ,标签包裹的内容
result=soup.select(‘.sister’)[1].get(‘href’) # 取class为siser的第二个标签的href属性
3.Shutil库(os库的补充)
shutil.copy(src,dst)#复制文件,src表示源文件,dst表示目标文件夹,当移动到一个不存在的“目标文件夹”,系统会将这个不存在的“目标文件夹”识别为新的文件夹,而不会报错。
shutil.copytree(src,dst)#复制文件夹,src表示源文件夹,dst表示目标文件夹,这里只能是移动到一个空文件夹,而不能是包含其他文件的非空文件夹,否则会报错PermissionError。
shutil.move(src,dst)#移动文件/文件夹;src表示源文件/文件夹,dst表示目标文件夹;文件/文件夹一旦被移动了,原来位置的文件/文件夹就没了。目标文件夹不存在时,会报错;
shutil.rmtree(src)#删除文件夹;src表示源文件夹;区别这里和os模块中remove()、rmdir()的用法,remove()方法只能删除某个文件,mdir()只能删除某个空文件夹。但是shutil模块中的rmtree()可以递归彻底删除非空文件夹;
zipobj.write()#创建一个压缩包 zipobj相当于要进行操作的文件;
zipobj.namelist()#读取压缩包中的文件信息;
zipobj.extract()#将压缩包中的单个文件,解压出来;
zipobj.extractall()#将压缩包中所有文件,解压出来;
4.jieba库
库的导入:import jieba
jieba.cut(s) #精确模式,把文本精确的切分开,不存在冗余单词
jieba.lcut(s,cut_all=True) #全模式,把文本中所有可能的词语都扫描出来,有冗余
jieba.lcut_for_search(s) #搜索引擎模式,在精确模式基础上,对长词再次切分:
jieba.load_userdict(dict_path)#开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词
5.re库
库的导入:import re
re库Python中使用正则表达式需要用到的库,是Python的标准库
re.match(pattern, string, flags=0) #从一个字符串的开始位置起匹配正则表达式,返回match对象。如果不是起始位置匹配成功的话,match()就返回none,可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式
re.search(pattern, string, flags=0) #在一个字符串中匹配正则表达式的第一个位置,返回match对象,匹配成功re.search方法返回一个匹配的对象,否则返回None。
re.match与re.search的区别,re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search 匹配整个字符串,直到找到一个匹配。
re.sub(pattern, rep1, string, count=0, flags=0)#在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串,repl:替换的字符串,也可为一个函数,count:模式匹配后替换的最大次数,默认 0 表示替换所有的匹配,flags:编译时用的匹配模式,数字形式,前3个参数为必选参数,后两个为可选参数
re.findall(pattern, string, flags=0) 或 re.findall(string[, pos[, endpos]]) #搜索字符串,返回全部匹配的子串,返回的是列表类型,如果没有找到匹配的,就返回一个空列表,注:match(匹配开始位置的1个) 和 search(匹配符合的第1个)匹配一次 ,而 findall 是匹配所有,pos:可选参数,指定字符串的起始位置,默认为 0。endpos:可选参数,指定字符串的结束位置,默认为字符串的长度、
re.finditer(pattern, string, flags=0)和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,返回一个匹配结果的迭代器(迭代类型),每个迭代元素是match对象
re.splite(pattern, string[, maxsplit=0, flags=0])#将一个字符串按照正则表达式匹配结果分割,返回的是列表类型,maxsplit:分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数
re.compile(pattern[, flags])#compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用
6.os库
os.rename(目标文件名,新文件名)#文件重命名
os.mknod(‘./new_file.txt’)#创建文件,windows下不支持
os.mkdir(文件夹名字)#创建文件夹
os.rmdir(文件夹名字)#删除文件夹
os.getcwd()#获取当前目录
os.chdir()#改变默认目录
os.listdir()#获取目录列表
os.path.dirname(path)#返回路径的上一级路径字符串
os.path.basename(path)#返回路径的最后一级目录名或文件名
os.path.splitext(file_name)#返回文件名和其后缀组成的元组
os.path.abpath(file)#获取当前文件的绝对位置
os.path.abpath(string)#返回当前工作目录的路径加上string组成的路径字符串
os.path.isdir(path)#判断一个路径是否是一个目录(文件夹)
os.path.isfile(path)#判断一个路径是否是一个文件
os.listdir(dir_path)#以列表的形式返回一个目录(dir_path只能是目录,不能是文件名路径)下的所有文件(全称)和文件夹名称
os.removedirs(dir_path)#删除指定空目录(空文件夹)
os.path.exists(path)#判断一个路径是否存在
os.path.realpath(path)#返回path的真实路径
os.path.join(path,name)#路径拼接
os.path.split()#返回一个路径的目录名和文件名
os.stat(file)#获得文件属性
os.path.getsize(name)#获得文件大小
os.path.isabs()#判断是否为绝对路径
os.urandom(n)#随机生成n个字节的字符串,可以作为随机加密的key使用。
7.wordCloud库
库的导入:import wordcloud
词云绘制步骤
-步骤1:配置对象参数
-步骤2:加载词云文本
-步骤3:输出词云文件
w=wordcloud.WordCloud(参数)
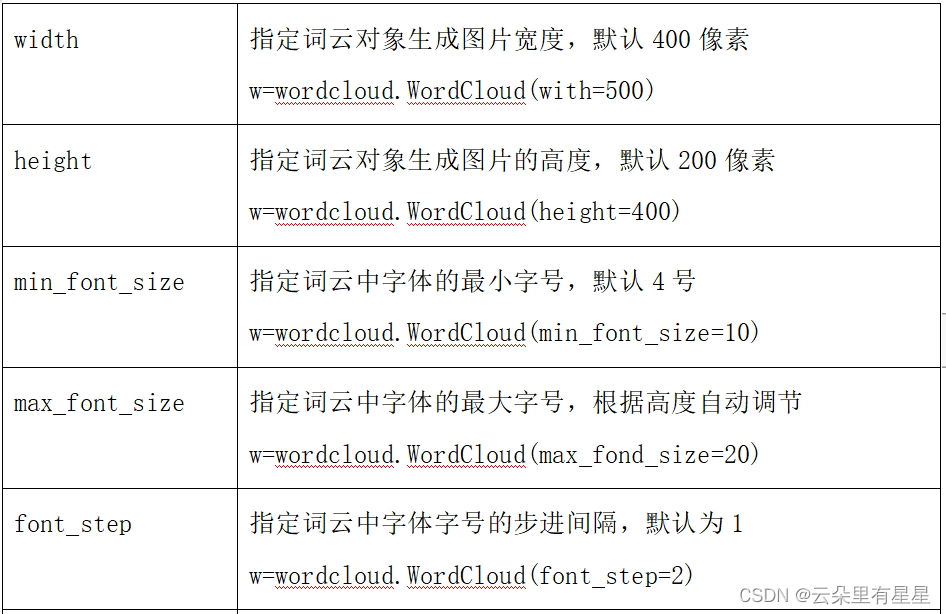
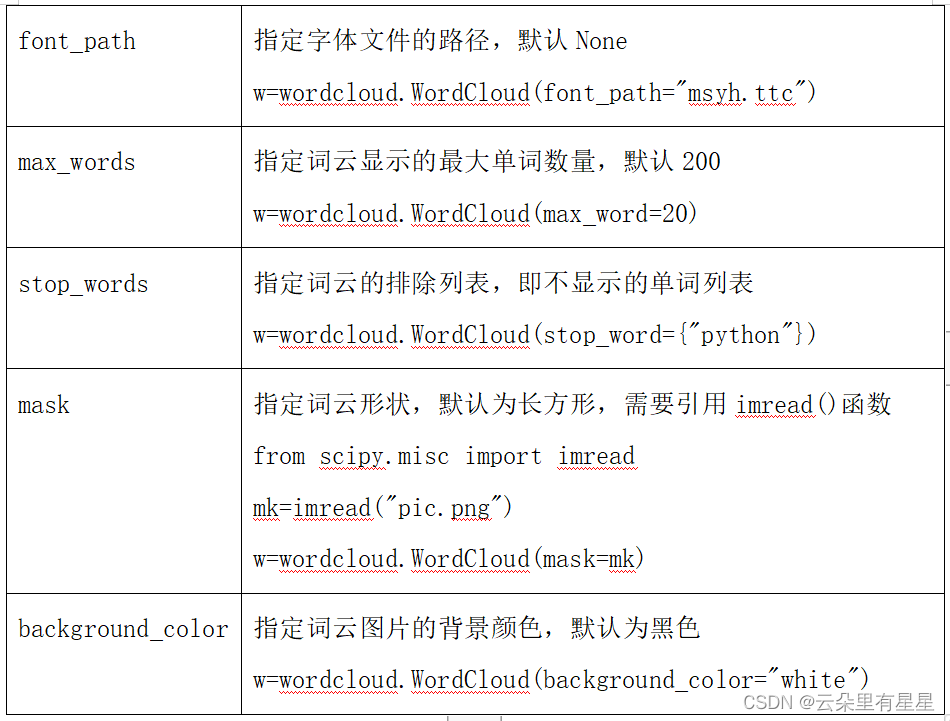
w.generate(txt) #向WordCloud对象w中加载文本txt
w.to_file(filename) #将词云输出为图像文件,.png或.jpg格式eg.w.to_file(“outfile.png”)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









