







1.算法原理
决策树是一个类似于流程图的树结构,分支节点表示对一个特征进行测试,根据测试结果进行分类,树叶节点代表一个类别。即,决策树:从根节点开始一步步走到叶子节点(决策)。
2.信息熵
一条信息的信息量和它的不确定性有直接关系。一个问题不确定性越大,要搞清楚这个问题,需要了解的信息就越多,其信息嫡就越大。
信息嫡的计算公式为:
H
(
X
)
=
−
∑
x
∈
X
P
(
x
)
log
2
P
(
x
)
H(X)=-\sum_{x \in X} P(x) \log _{2} P(x)
H(X)=−x∈X∑P(x)log2P(x)其中,P(x)表示事件x出现的概率。例如,一个盒子里分别有5个白球和5个红球,随机取出一个球。问:这个球是红色的还是白色的?这个问题的信息量多大呢?由于红球和白球出现的概率都是1/2,代入信息熵公式,可以得到其信息熵为:
H
(
X
)
=
−
(
1
2
log
2
1
2
+
1
2
log
2
1
2
)
=
1
H(X)=-\left(\frac{1}{2} \log _{2} \frac{1}{2}+\frac{1}{2} \log _{2} \frac{1}{2}\right)=1
H(X)=−(21log221+21log221)=1当我们要构建一个决策树时,应该优先选择哪个特征来划分数据集呢?答案是:遍历所有的特征,分别计算,使用这个特征划分数据集前后信息熵的变化值,然后选择信息熵变化幅度最大的那个特征,来优先作为数据集划分依据。即选择信息增益最大的特征作为分裂节点。
把信息熵和概率的函数关系: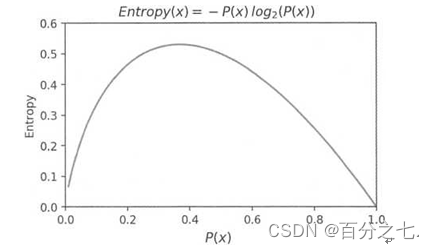
从这个函数关系可以看出来,当概率P(x)越接近0或越接近1时,信息熵的值越小,其不确定性越小,即数据越“纯”。熵是衡量一组数据是否纯的指标。典型地,当概率值为1时,此时数据是最“纯净”的, 因为只有一种类别的数据,已经消除了不确定性,其信息熵为0。我们在特征选择时,选择信息增益最大的特征,在物理上,即让数据尽量往更纯净的方向上变换。因此,我们得出,信息增益是用来衡量数据变得更有序、更纯净的程度的指标。
3.决策树的创建
决策树的创建基本上分以下步骤:
1)计算数据集划分前的信息熵。
2)遍历所有未作为划分条件的特征,分别计算根据每个特征划分数据集后的信息熵。
3)选择信息增益最大的特征,并使用这个特征作为数据划分节点来划分数据。
4)递归地处理被划分后的所有子数据集,从未被选择的特征里继续选择最优数据划分特征来划分子数据集。
递归过程什么时候结束呢?一般来讲,有两个终止条件:
1)所有的特征都用完了,即没有新的特征可以用来进一步划分数据集。
2)划分后的信息增益足够小了,这个时候就可以停止递归划分了。针对这个停止条件,需要事先选择信息增益的门限值来作为结束递归的条件。
- 离散化
如果一个特征是连续值怎么办呢?
这个时候一个用离散化来建模,需要对数据进行离散化处理,离散化成几个类别。 - 正则式
最大化信息增益来选择特征,在决策树的构建过程中,容易造成优先选择类别最多的特征来进行分类。
举一个极端的例子,我们把某个产品的唯一标识符ID作为特征之一加入到数据集中,那么构建决策树时,就会优先选择产品ID来作为划分特征,因为这样划分出来的数据,每个叶子节点只有一个样本,划分后的子数据集最“纯净”,其信息增益最大。
这不是我们希望看到的结果。解决办法是,计算划分后的子数据集的信息熵时,加上一个与类别个数成正比的正则项,来作为最后的信息熵。这样,当算法选择的某个类别较多的特征,使信息嫡较小时,由于受到类别个数的正则项惩罚,导致最终的信息熵也比较大。这样通过合适的参数,可以使算法训练得到某种程度的平衡。 - 基尼不纯度
我们知道,信息熵是衡量信息不确定性的指标,实际上也是衡量信息“纯度”的指标。
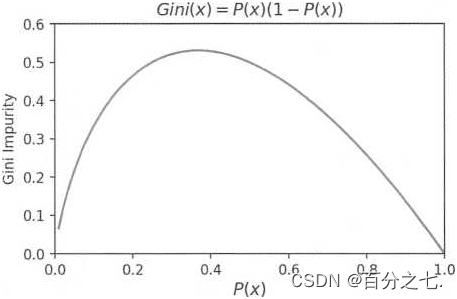
除此之外,基尼不纯度(Gini impurity)也是衡量信息不纯度的指标,其计算公式如下:
Gini ( D ) = ∑ x ∈ X P ( x ) ( 1 − P ( x ) ) = 1 − ∑ x ∈ X P ( x ) 2 \operatorname{Gini}(D)=\sum_{x \in X} P(x)(1-P(x))=1-\sum_{x \in X} P(x)^{2} Gini(D)=x∈X∑P(x)(1−P(x))=1−x∈X∑P(x)2
其中,P(x)是样本属于x这个类别的概率。如果所有的样本都属于一个类别,此时 P(x)=l,则Gini(D)=O,即数据不纯度最低,纯度最高。
4.剪枝算法
使用决策树模型拟合数据时,容易造成过拟合。解决过拟合的方法是对决策树进行剪枝处理。
决策树的剪枝有两种思路:前剪枝(Pre-Pruning)和后剪枝(Post-Pruning)。
- 前剪枝
前剪枝是在构造决策树的同时进行剪枝。在决策树的构建过程中,如果无法进一步降低信息熵的情况下,就会停止创建分支。为了避免过拟合,可以设定一个阈值,信息熵减小的数量小于这个阈值,即使还可以继续降低熵,也停止继续创建分支。这种方法称为前剪枝。还有一些简单的前剪枝方法,如限制叶子节点的样本个数,当样本个数小于一定的阈值时,即不再继续创建分支。 - 后剪枝
后剪枝是指决策树构造完成后进行剪枝。剪枝的过程是对拥有同样父节点的一组节点进行检查,判断如果将其合并,信息熵的增加量是否小于某一阈值。如果小于阈值,则这一组节点可以合并一个节点。
后剪枝是目前较普遍的做法。后剪枝的过程是删除一些子树,然后用子树的根节点代替,来作为新的叶子节点。这个新叶子结点所标识的类别通过大多数原则来确定,即把这个叶子节点里最多的类别作为这个叶子节点的类别。
后剪枝算法有很多种,其中常用的一种称为降低错误率剪枝法(Reduced-Error Pruning)。其思路是,自底向上,从已经构建好的完全决策树中找出一个子树,然后用子树的根节点代替这棵子树,作为新的叶子节点。叶子节点所标识的类别通过大多数原则来确定。这样就构建出一个新的简化版的决策树。然后使用交叉验证数据集来测试简化版本的决策树,看看其错误率是不是降低了。如果错误率降低了,则可以使用这个简化版的决策树代替完全决策树,否则还是采用原来的决策树。通过遍历所有的子树,直到针对交叉验证数据集,无法进一步降低错误率为止。















 6715
6715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









