







参考教程:https://courses.d2l.ai/zh-v2/
线性模型
定义:回归(regression)是能为一个或多个自变量与因变量之间关系建模的一类方法。
线性假设是指目标可以表示为特征的加权和,权重决定了每个特征对我们预测值的影响。
当我们的输入包含d个特征时,我们将预测结果y^ (通常使用“尖角”符号表示y的估计值)表示为:
y
^
=
w
1
x
1
+
…
+
w
d
x
d
+
b
\hat{y}=w_1 x_1+\ldots+w_d x_d+b
y^=w1x1+…+wdxd+b在开始寻找最好的模型参数(model parameters)w和b之前, 我们还需要两个东西: (1)一种模型质量的度量方式; (2)一种能够更新模型以提高模型预测质量的方法。
• 线性回归是对n维输入的加权,外加偏差
• 使用平方损失来衡量预测值和真实值的差异
• 线性回归可以看做是单层神经网络
(1)度量模型质量-损失函数
在我们开始考虑如何用模型拟合(fit)数据之前,我们需要确定一个拟合程度的度量。 损失函数(loss function)能够量化目标的实际值与预测值之间的差距。 通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。 回归问题中最常用的损失函数是平方误差函数。 当样本i的预测值为y^(i),其相应的真实标签为y(i)时, 平方损失可以定义为以下公式:
l
(
i
)
(
w
,
b
)
=
1
2
(
y
^
(
i
)
−
y
(
i
)
)
2
l^{(i)}(\mathbf{w}, b)=\frac{1}{2}\left(\hat{y}^{(i)}-y^{(i)}\right)^2
l(i)(w,b)=21(y^(i)−y(i))2常数1/2不会带来本质的差别,但这样在计算上稍微简单一些 (因为当我们对损失函数求导后常数系数为1)。
(2)更新模型以提高模型预测质量-随机梯度下降
梯度下降(gradient descent)的方法几乎可以优化所有深度学习模型。 它通过不断地在损失函数递减的方向上更新参数来降低误差。
梯度下降最简单的用法是计算损失函数(数据集中所有样本的损失均值) 关于模型参数的导数(在这里也可以称为梯度)。 但实际中的执行可能会非常慢:因为在每一次更新参数之前,我们必须遍历整个数据集。 因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本, 这种变体叫做小批量随机梯度下降(minibatch stochastic gradient descent)。
在每次迭代中,我们首先随机抽样一个小批量B, 它是由固定数量的训练样本组成的。 然后,我们计算小批量的平均损失关于模型参数的导数(也可以称为梯度)。 最后,我们将梯度乘以一个预先确定的正数η,并从当前参数的值中减掉。
B表示每个小批量中的样本数,这也称为批量大小(batch size)。 η表示学习率(learning rate)。 批量大小和学习率的值通常是手动预先指定,而不是通过模型训练得到的。 这些可以调整但不在训练过程中更新的参数称为超参数(hyperparameter)。 调参(hyperparameter tuning)是选择超参数的过程。 超参数通常是我们根据训练迭代结果来调整的, 而训练迭代结果是在独立的验证数据集(validation dataset)上评估得到的。
其中选择批量,不能太小:每次计算量太小,不适合并行来最大利用计算资源。不能太大:内存消耗增加,浪费计算。
• 梯度下降通过不断沿着反梯度方向更新参数求解
• 小批量随机梯度下降是深度学习默认的求解算法
• 两个重要的超参数是批量大小和学习率
神经网络图
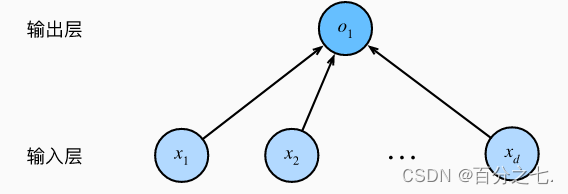
在计算层数时不考虑输入层。,也就是说,图中神经网络的层数为1。 我们可以将线性回归模型视为仅由单个人工神经元组成的神经网络,或称为单层神经网络。
对于线性回归,每个输入都与每个输出(在本例中只有一个输出)相连, 我们将这种变换( 图中的输出层) 称为全连接层(fully-connected layer)或称为稠密层(dense layer)。
线性回归的从零开始实现
%matplotlib inline
import random
import torch
from d2l import torch as d2l
#生成合成数据集
def synthetic_data(w, b, num_examples): #@save
"""生成y=Xw+b+噪声"""
X = torch.normal(0, 1, (num_examples, len(w)))#随机数,服从(0,1)正态分布
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
print('features:', features[0],'\nlabel:', labels[0])
#features: tensor([0.0257, 0.4013])
#label: tensor([2.8992])
d2l.set_figsize()
d2l.plt.scatter(features[:, 1].detach().numpy(), labels.detach().numpy(), 1);
#读取数据集
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 这些样本是随机读取的,没有特定的顺序
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 这些样本是随机读取的,没有特定的顺序
random.shuffle(indices)#打乱
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
batch_size = 10
#初始化模型参数
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)#设为True,需要计算梯度
b = torch.zeros(1, requires_grad=True)
#定义模型
def linreg(X, w, b): #@save
"""线性回归模型"""
return torch.matmul(X, w) + b
# 定义损失函数
def squared_loss(y_hat, y): #@save
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
#定义优化算法
def sgd(params, lr, batch_size): #@save
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()#梯度设0
#训练
lr = 0.03#学习率
num_epochs = 3#迭代次数
net = linreg#模型
loss = squared_loss#均方损失
#上述写法方便以后做修改
for epoch in range(num_epochs):#每次扫一遍数据
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X和y的小批量损失
# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,
# 并以此计算关于[w,b]的梯度
l.sum().backward()
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
线性回归的简洁实现
通过使用深度学习框架来简洁地实现线性回归模型生成数据集
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
#读取数据集
def load_array(data_arrays, batch_size, is_train=True): #@save
"""构造一个PyTorch数据迭代器"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)#打乱数据
batch_size = 10
data_iter = load_array((features, labels), batch_size)
#定义模型
# nn是神经网络的缩写
from torch import nn
# 我们将两个参数传递到nn.Linear中。 第一个指定输入特征形状,即2,第二个指定输出特征形状,输出特征形状为单个标量,因此为1。
net = nn.Sequential(nn.Linear(2, 1))
#初始化模型参数
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
#定义损失函数
loss = nn.MSELoss()
#定义优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
#训练
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X) ,y)
trainer.zero_grad()#清0
l.backward()
trainer.step()#模型更新
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')
• 我们可以使用PyTorch的高级API更简洁地实现模型。
• 在PyTorch中,data模块提供了数据处理工具,nn模块定义了大量的神经网络层和常见损失函数。
• 我们可以通过_结尾的方法将参数替换,从而初始化参数。















 4253
4253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









