










文章目录
基于Python机器学习算法农产品爬虫可视化分析预测系统(完整源码+数据库+详细开发文档+详细部署文档+详细万字论文)
源码获取方式在文章末尾
源码获取方式在文章末尾
源码获取方式在文章末尾
一、项目概述
本研究致力于设计并实现了一款基于Python的农产品可视化分析预测系统,系统主要利用requests库进行网络数据爬取,BeautifulSoup库解析网页内容,从惠农网获取相关农产品信息。系统功能包括数据价格分析、管理查询等,用户可以根据农产品名称进行机器学习模型的训练与预测,采用sklearn中的多元线性回归模型进行未来一周农产品价格的预测,并通过可视化分析展示结果。此外,系统还具备flask_admin后台数据管理功能,管理员可以对数据进行增删改查及修改用户权限。本研究的核心在于将爬虫技术、机器学习算法和数据可视化技术相结合,为农产品市场提供了一种全新的数据分析与预测工具。通过本系统,用户可以更加直观地了解农产品价格趋势,为农业生产和经营决策提供科学依据。未来,将进一步完善系统功能,提升用户体验,为农业信息化发展做出更大贡献。
二、项目说明
Navicat Premium 15简介
Navicat Premium 15是一款功能强大的数据库管理工具,为用户提供了全面的数据库管理解决方案。其直观的用户界面和丰富的功能使得数据库管理变得简单而高效。Navicat Premium 15支持多种数据库系统,包括MySQL、MariaDB、SQL Server、SQLite、Oracle等,使得用户能够轻松地管理不同类型的数据库。
Python语言
Python是一种高级编程语言,以简洁、易读的语法而闻名。它被广泛应用于各种领域,包括数据科学、人工智能、Web开发等。Python具有丰富的第三方库和框架,例如NumPy、Pandas、Scikit-learn等,使得数据处理和机器学习变得简单而高效。
Echarts简介
ECharts是一个基于JavaScript的开源可视化库,专注于提供简单、直观的数据可视化解决方案。它支持多种常见的图表类型,包括折线图、柱状图、饼图等,以及更复杂的地图、关系图等。ECharts具有丰富的交互功能,用户可以通过鼠标交互或者触摸屏操作来探索数据,实现动态展示和用户参与。
Pycharm简介
PyCharm是一款功能强大的Python集成开发环境(IDE),为Python开发者提供了全方位的开发支持。它拥有直观的用户界面和丰富的功能,包括代码自动补全、调试器、版本控制集成等,使得Python开发变得更加高效和愉快。
Mysql简介
MySQL是一种流行的开源关系型数据库管理系统,广泛应用于各种规模的应用程序中。它具有高性能、可靠性和易用性的特点,支持多种操作系统平台,并且与多种编程语言兼容。MySQL采用了客户端/服务器体系结构,能够处理大规模的数据,并提供了丰富的功能。
机器学习算法 LinearRegression简介
线性回归是一种用于建立和预测变量之间线性关系的机器学习算法。它是统计学中最基本、最简单的回归分析方法之一,也是许多其他机器学习算法的基础之一。
线性回归的基本原理是假设自变量(特征)与因变量(目标)之间存在线性关系,通过拟合一条最佳直线来描述这种关系。这条直线被称为回归线,通过该线可以对新的自变量值进行预测,从而得到对应的因变量值。
在线性回归中,通常使用最小二乘法来确定回归系数,即通过最小化实际值与预测值之间的误差平方和来求解最优的回归系数。这些回归系数表示了自变量对因变量的影响程度。
线性回归适用于以下情况:
- 自变量与因变量之间存在线性关系。
- 数据中的噪声相对较小。
- 可以通过对数据进行适当的变换来满足线性关系的假设。
线性回归的优点包括:
- 简单易于理解和实现。
- 计算速度快,适用于大规模数据集。
- 提供了对于自变量与因变量之间关系的直观理解。
三、功能需求分析
系统需要能够通过requests爬虫和BeautifulSoup解析器,从惠农网等农产品信息平台上获取相关数据。这包括农产品的价格、供应量、市场趋势等信息。爬取到的数据需要经过解析和清洗,确保数据的准确性和可用性。用户需要能够对爬取到的数据进行管理和查询。这包括数据的存储、检索、更新和删除等功能。用户应该能够通过系统界面轻松地查询到所需的农产品信息,并进行必要的数据管理操作。系统应该具备使用sklearn机器学习库中的多元线性回归(LinearRegression)模型来对未来一周农产品价格进行预测的功能。用户输入农产品名称后,系统应该能够自动训练相应的模型,并生成价格预测结果。预测结果应该以直观的可视化形式展示给用户,以便他们更好地理解和分析数据。系统应该支持生成各种图表、趋势图和统计图,帮助用户直观地了解农产品价格的变化趋势和波动情况。管理员需要能够通过后台管理界面对系统中的数据进行管理。这包括对数据的增加、删除、修改和查询等操作,以及对用户权限的管理和控制。系统需要具备数据爬取与解析、数据管理与查询、机器学习模型应用、可视化分析和后台数据管理等多项功能,以实现对农产品价格的可视化分析预测。通过这些功能的整合和实现,用户可以方便地获取到农产品市场的相关信息,并利用机器学习模型进行价格预测和分析,从而为农业生产经营者提供科学的决策支持。
四、系统总体架构设计

五、部分模块核心代码
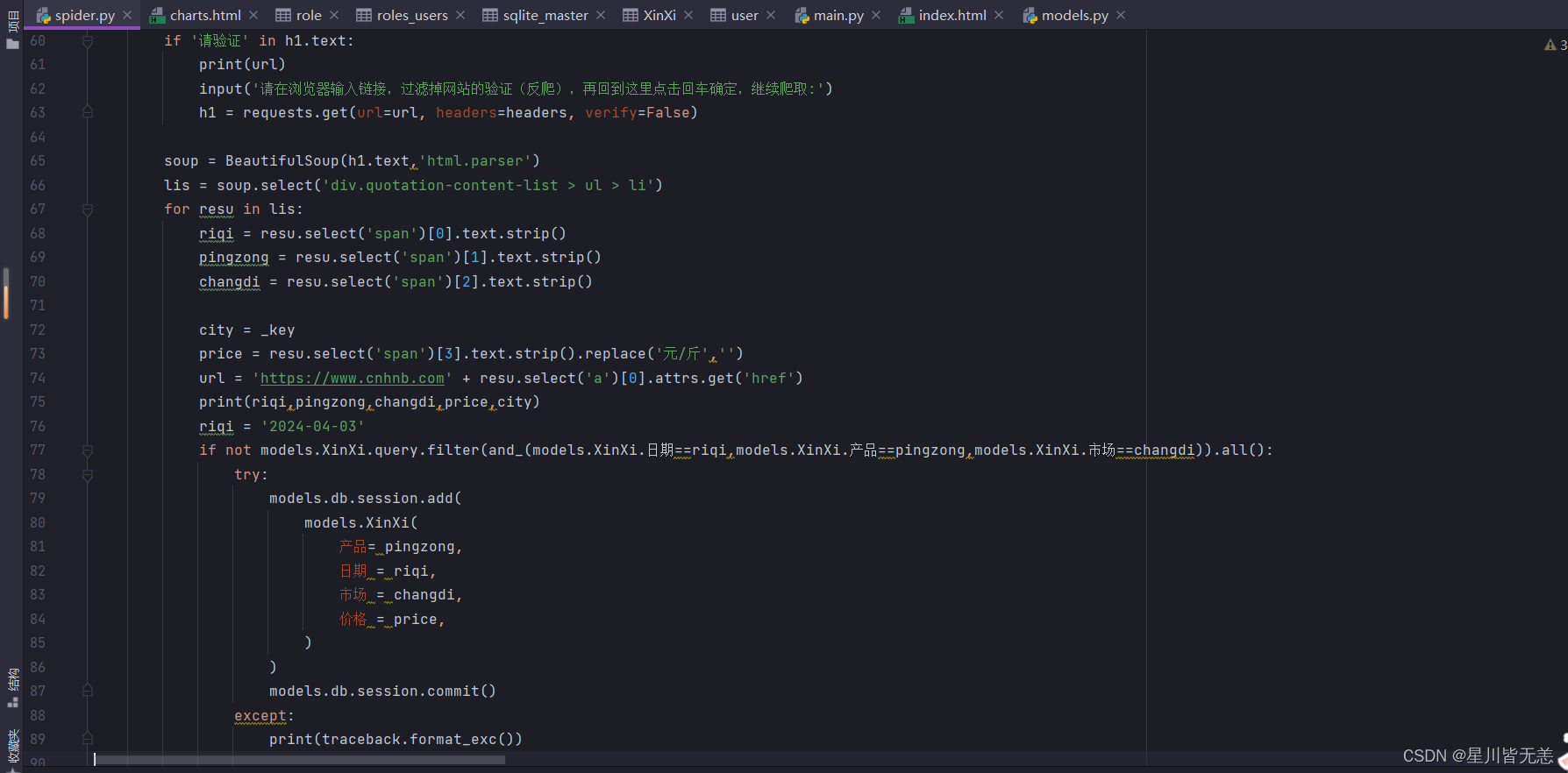
#预测某个产品价格的变化趋势。从数据库中获取产品的交易记录,然后利用线性回归模型进行训练,并预测未来几天的价格走势。
def yuce1(name):
try:
dates = models.XinXi.query.filter(models.XinXi.产品 == name).all()
date_day = list(set([i.日期 for i in dates]))
date_day.sort()
liuliang = []
for i in date_day:
record_list = models.XinXi.query.filter(and_(models.XinXi.日期 == i,models.XinXi.产品 == name)).all()
num = 0
count = 0
for reco in record_list:
num += reco.价格
count += 1
liuliang.append(round(num / count ,2))
date_day = [str(i).replace('-', '') for i in date_day]
examDict = {
'日期': date_day,
'均价': liuliang
}
print(examDict)
examOrderedDict = OrderedDict(examDict)
examDf = pd.DataFrame(examOrderedDict)
examDf.head()
exam_x = examDf.loc[:, '日期']
exam_y = examDf.loc[:, '均价']
x_train, x_test, y_train, y_test = train_test_split(exam_x, exam_y, train_size=0.8)
x_train = x_train.values.reshape(-1, 1)
x_test = x_test.values.reshape(-1, 1)
model = LinearRegression()
model.fit(x_train, y_train)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
rDf = examDf.corr()
model.score(x_test, y_test)
data1 = datetime.datetime.strptime(str(date_day[-3]), '%Y%m%d')
li1 = []
for i in range(10):
data1 = data1 + datetime.timedelta(1)
li1.append([int(data1.strftime('%Y%m%d'))])
li2 = numpy.array(li1)
y_train_pred = model.predict(li2)
.................

六、功能实现
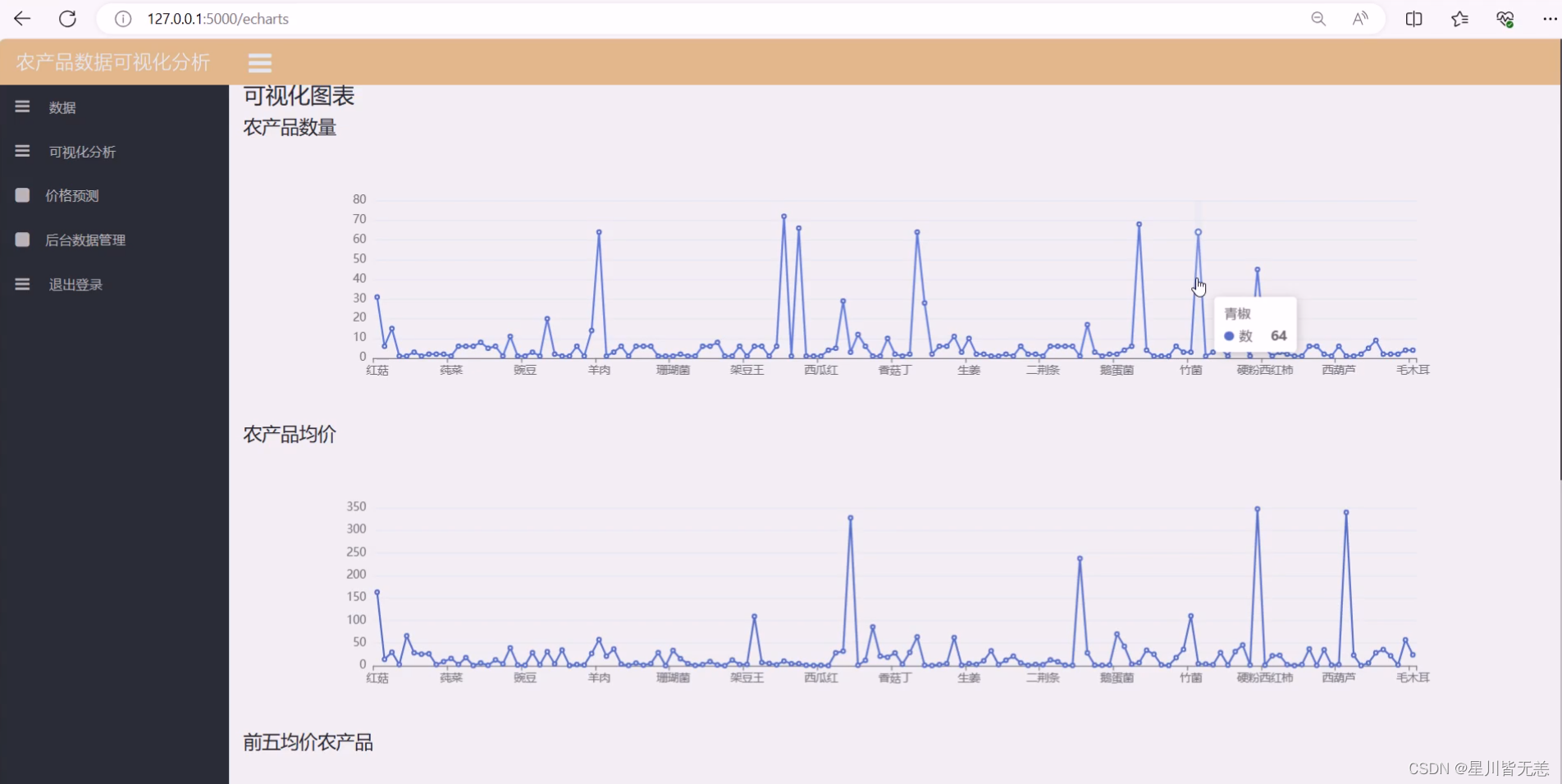

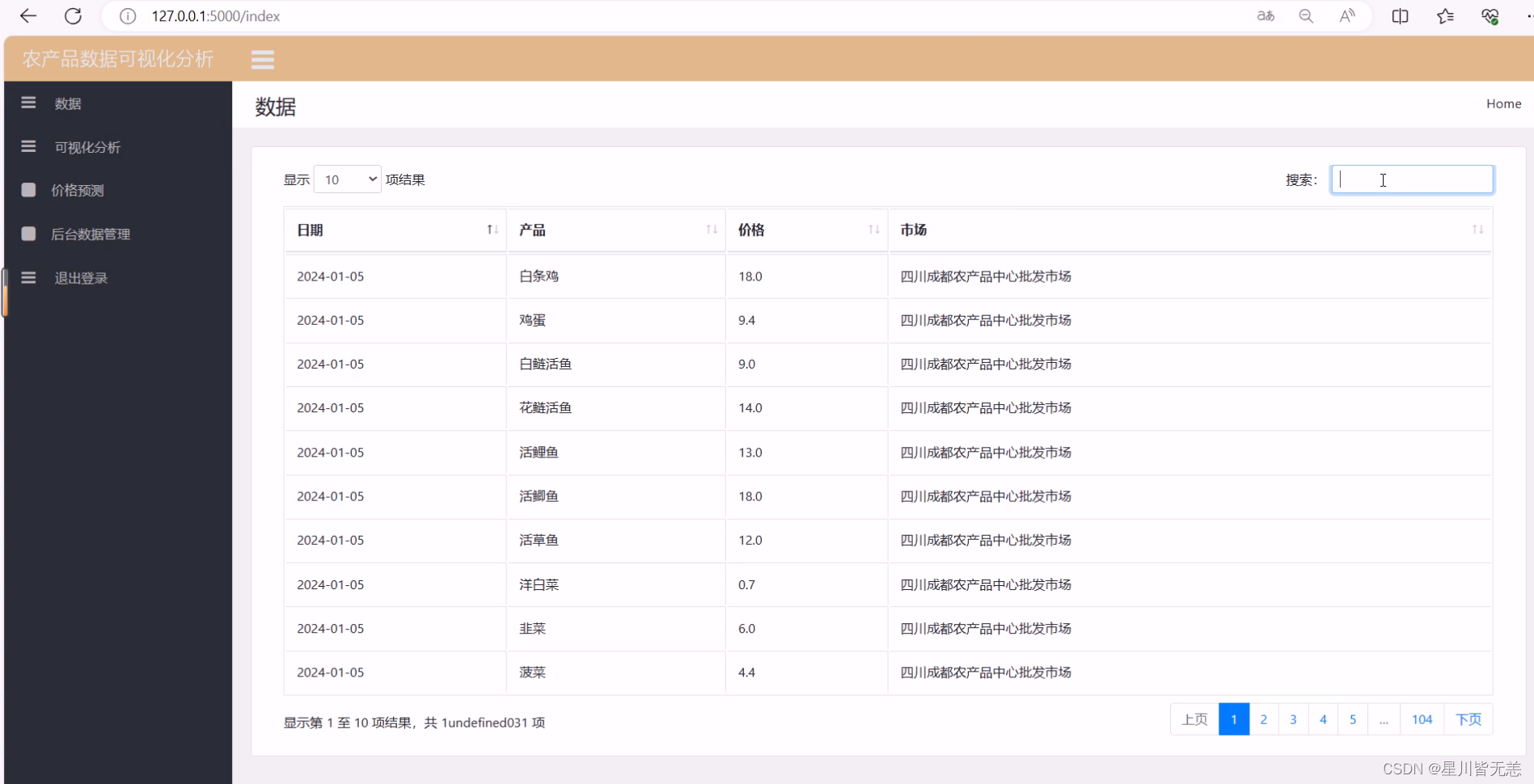

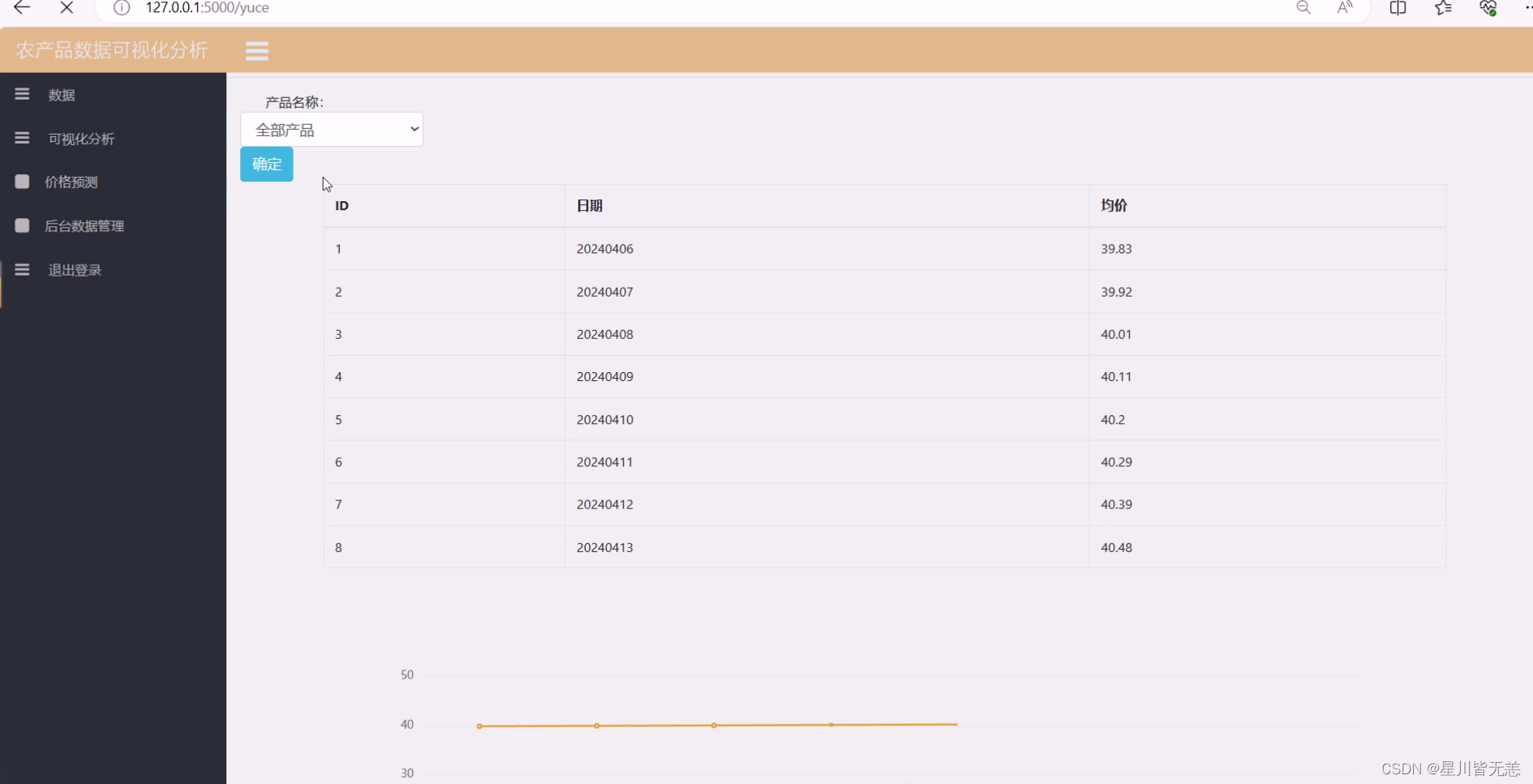


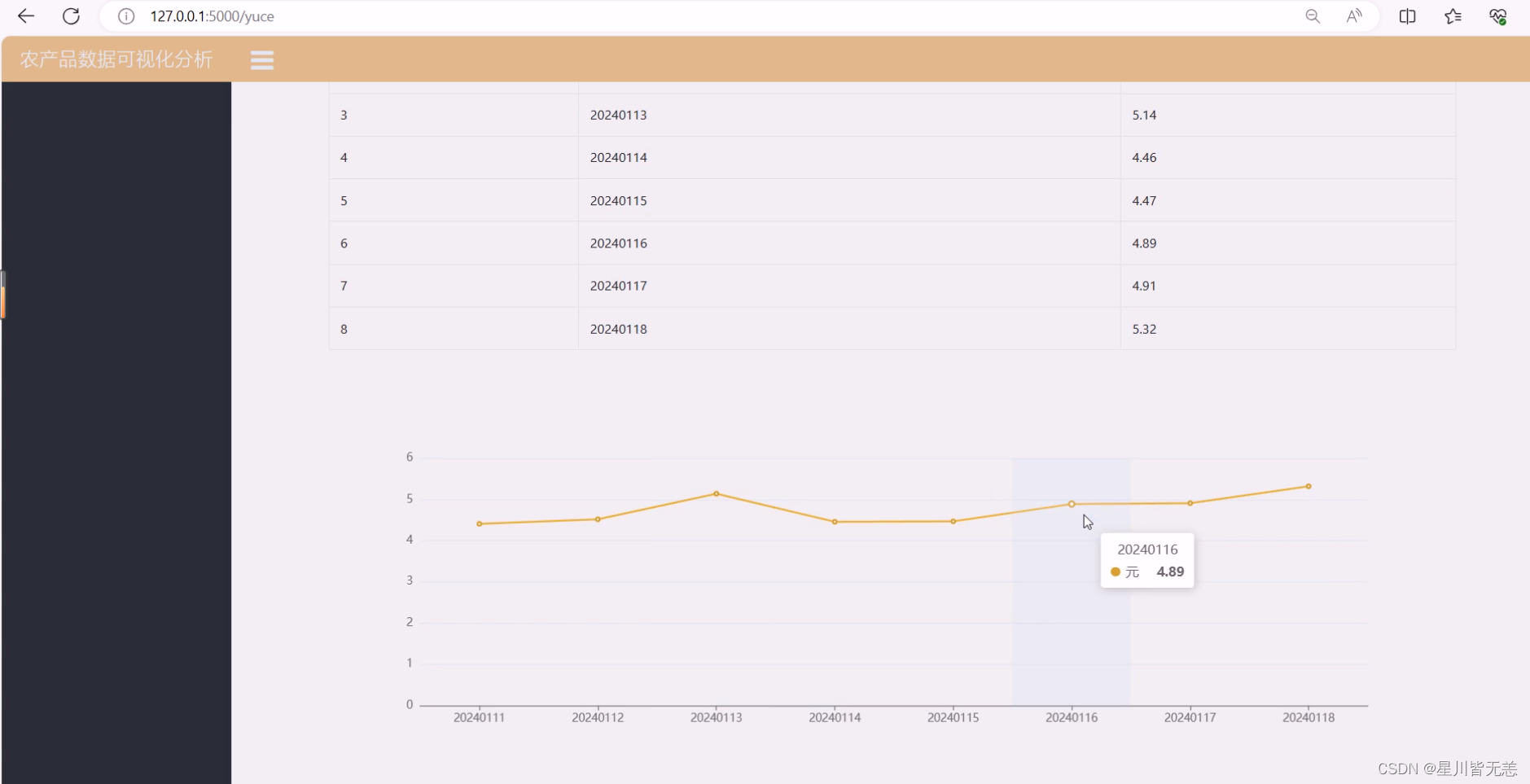
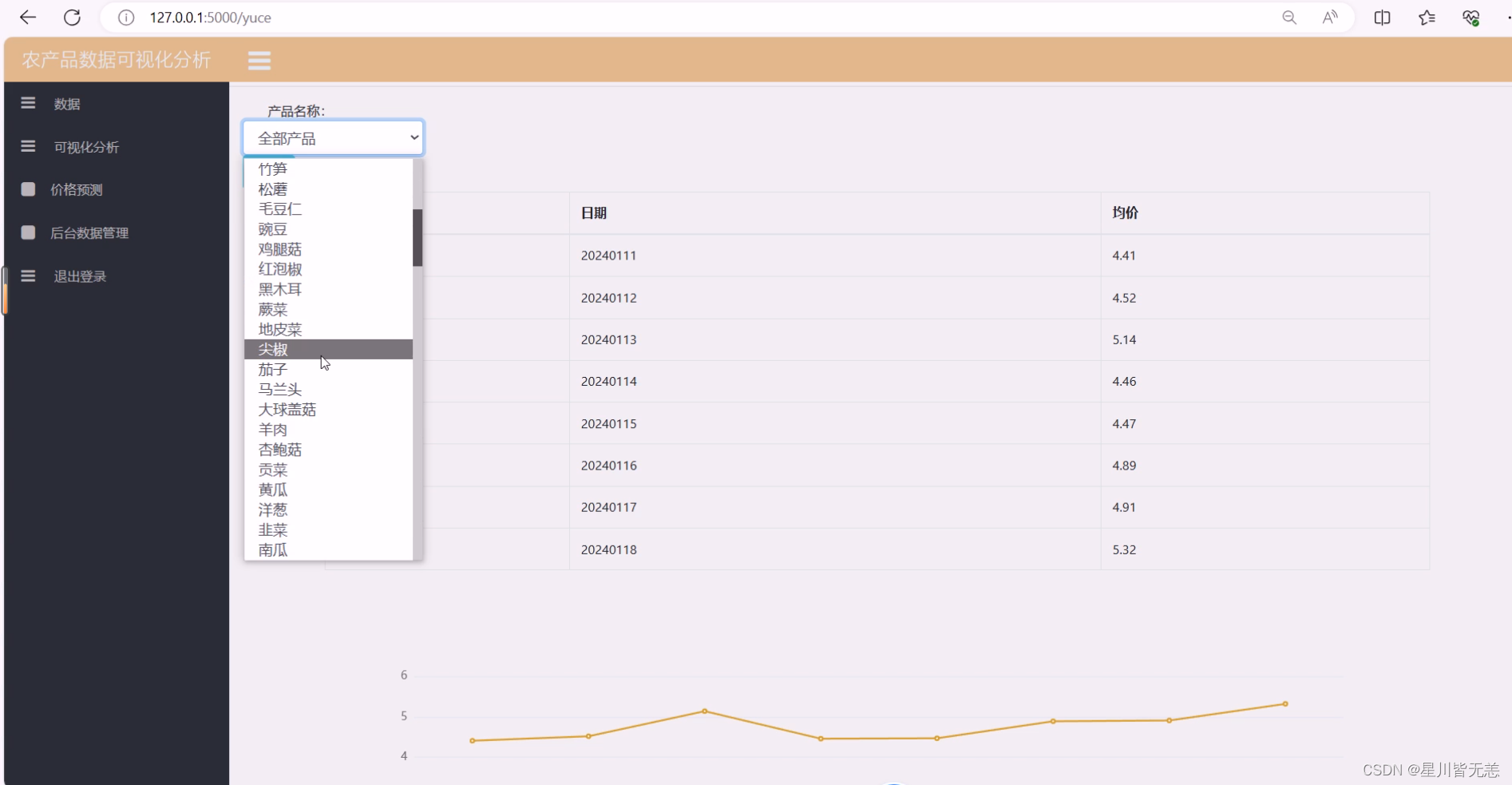
七、项目资料获取
需要全部项目资料(完整系统源码等资料),扫码+。
需要全部项目资料(完整系统源码等资料),扫码+。
需要全部项目资料(完整系统源码等资料),扫码+。
需要全部项目资料(完整系统源码等资料),扫码+。
















 4083
4083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









