






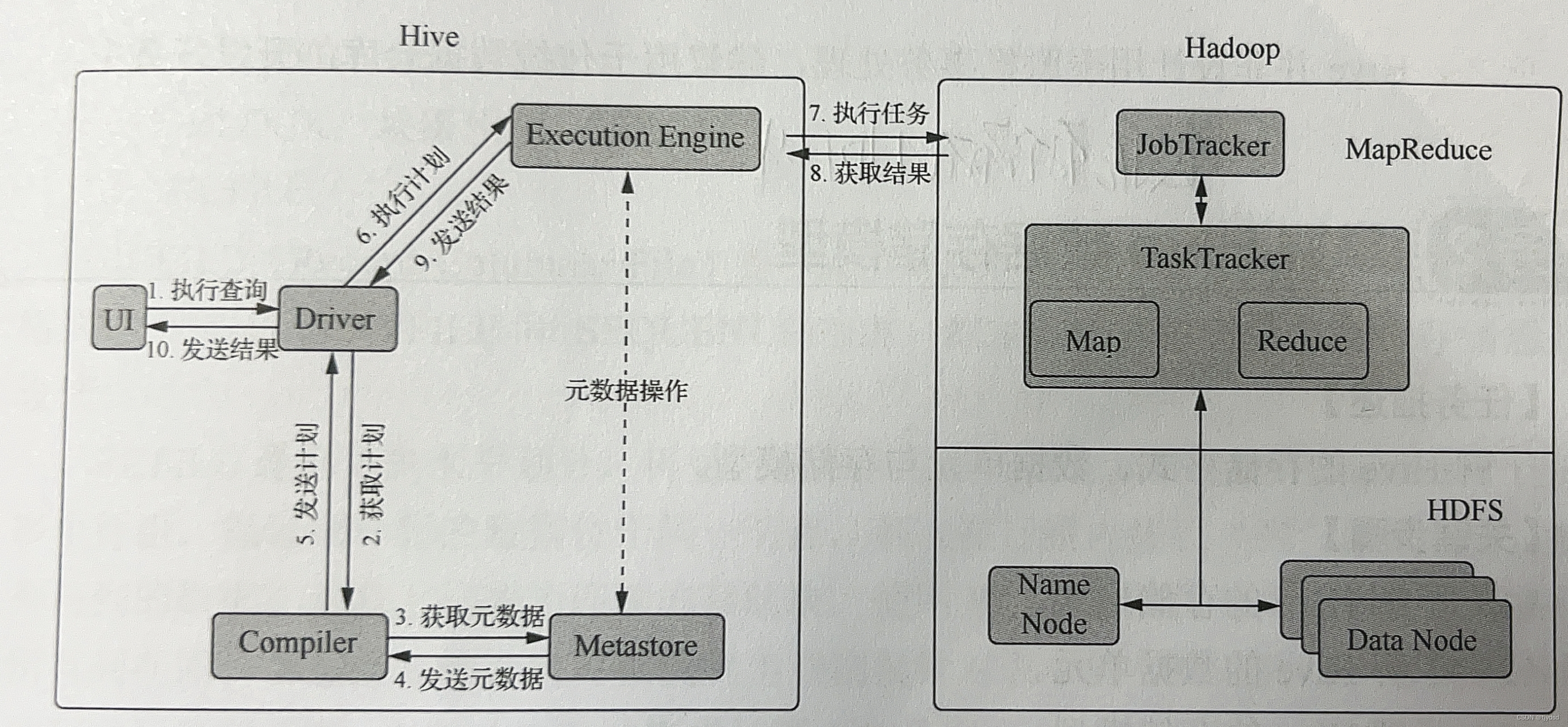
HQL 通过 CLI、JDBC 客户端、HWI 接口提交,通过 Compiler 编译并运用 Metastore中的数据进行类型检测和语法分析,进而得到执行计划,产生以有向无环图(DirectedAcyclic Graph,DAG)描述的一系列MapReduce 作业;DAG描述了作业之间的依赖关系,执行引擎按照作业的依赖关系将作业提交至 Hadoop 执行。Hive 的具体工作流程如图1.3 所示。
Hive 工作流程中各步骤的详细描述如表所示。

hive适用场景
1. 适用场景
> Hive 适用于非结构化数据的离线分析统计场合。
> Hive 的执行延迟比较高,因此适用于对实时性要求不高的场合。
> Hive 的优势在于处理大数据,因此适用于大数据(而非小数据)处理的场合。
2. 场景技术特点
> 为超大数据集设计了计算与扩展功能。
>支持 SQL like 查询语言。
>支持多表的join 操作。
>支持非结构化数据的查询与计算。
>提供数据存取的编程接口,支持JDBC、ODBC。















 1074
1074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









