




1 并发集合
1.1 线程安全集合分类

a.遗留的线程安全集合
- 遗留的线程安全集合如 HashTable ,Vector
b.使用 Collections 装饰的线程安全集合
- 使用 Collections 装饰的线程安全集合,如:
-
- Collections.synchronizedCollection
- Collections.synchronizedList
- Collections.synchronizedMap
- Collections.synchronizedSet
- Collections.synchronizedNavigableMap
- Collections.synchronizedNavigableSet
- Collections.synchronizedSortedMap
- Collections.synchronizedSortedSet
- java.util.concurrent.*
c.JUC下的安全集合: Blocking、CopyOnWrite、Concurrent
重点介绍 java.util.concurrent.* 下的线程安全集合类,可以发现它们有规律,里面包含三类关键词: Blocking、CopyOnWrite、Concurrent
- Blocking类型 大部分实现基于锁,并提供用来阻塞的方法。该类中大部分方法都是在不满足条件时进行阻塞等待。
- CopyOnWrite类型 之类容器修改开销相对较重。采用了一种在修改时拷贝的方式来避免多线程访问读写时的线程安全问题。适用于读多写少的情况 (写的开销相对比较大)。
- Concurrent 类型的容器 (性能较高)
-
- 优点:内部很多操作使用 cas 优化,一般可以提供较高吞吐量
- 缺点:弱一致性
-
-
- 遍历时弱一致性,例如,当利用迭代器遍历时,如果容器发生修改,迭代器仍然可以继续进行遍历,这时内容是旧的
- 求大小弱一致性,size 操作未必是 100% 准确
- 读取弱一致性
-
遍历时如果发生了修改,对于非安全容器来讲,使用 fail-fast 机制也就是让遍历立刻失败,抛出ConcurrentModifificationException,不再继续遍历
1.2 集合对比
三种集合:
- HashMap 是线程不安全的,性能好
- Hashtable 线程安全基于 synchronized,方法被synchronized修饰,虽然能保证线程安全,但性能太差,已经被淘汰
- ConcurrentHashMap 保证了线程安全,综合性能较好,不止线程安全,而且效率高,性能好
注意:修饰的安全集合类,如:SynchronizedMap,本质和Hashtable类一样,都是在每个方法上加了一个sychronized关键字修饰,性能上仍然没什么提升,因此也不推荐。
集合对比:
- Hashtable 继承 Dictionary 类,HashMap、ConcurrentHashMap 继承 AbstractMap,均实现 Map 接口
- Hashtable 底层是数组 + 链表,JDK8 以后 HashMap 和 ConcurrentHashMap 底层是数组 + 链表 + 红黑树
- HashMap 线程非安全,Hashtable 线程安全,Hashtable 的方法都加了 synchronized 关来确保线程同步
- ConcurrentHashMap、Hashtable 不允许 null 值,HashMap 允许 null 值
- ConcurrentHashMap、HashMap 的初始容量为 16,Hashtable 初始容量为11,填充因子默认都是 0.75,两种 Map 扩容是当前容量翻倍:capacity * 2,Hashtable 扩容时是容量翻倍 + 1:capacity*2 + 1
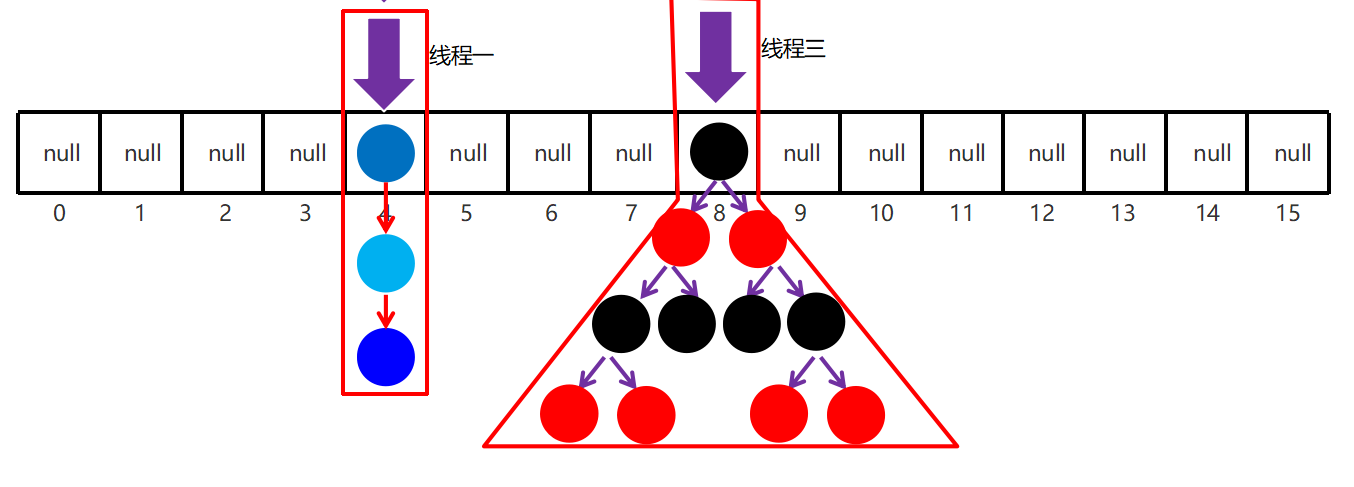
工作步骤:
-
初始化,使用 cas 来保证并发安全,懒惰初始化 table
-
树化,当 table.length < 64 时,先尝试扩容,超过 64 时,并且 bin.length > 8 时,会将链表树化,树化过程会用 synchronized 锁住链表头
说明:锁住某个槽位的对象头,是一种很好的细粒度的加锁方式,类似 MySQL 中的行锁
-
put,如果该 bin 尚未创建,只需要使用 cas 创建 bin;如果已经有了,锁住链表头进行后续 put 操作,元素添加至 bin 的尾部
-
get,无锁操作仅需要保证可见性,扩容过程中 get 操作拿到的是 ForwardingNode 会让 get 操作在新 table 进行搜索
-
扩容,扩容时以 bin 为单位进行,需要对 bin 进行 synchronized,但这时其它竞争线程也不是无事可做,它们会帮助把其它 bin 进行扩容
-
size,元素个数保存在 baseCount 中,并发时的个数变动保存在 CounterCell[] 当中,最后统计数量时累加
2 ConcurrentHashMap
练习demo:单词计数
生成测试数据
static final String ALPHA = "abcedfghijklmnopqrstuvwxyz";
static final String PATH = "";
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
int count = 200;
int length = ALPHA.length();
//将26个字母,每个字母200个,保存到list集合中
for (int i = 0; i < length; i++) {
char c = ALPHA.charAt(i);
for (int j = 0; j < count; j++) {
list.add(String.valueOf(c));
}
}
writeToFile(list, count);
//调用demo方法
...
...
//将字母写入文件中
public static void writeToFile(ArrayList<String> list 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









