







使用语言----c
难度----简单
目录
题1 两数之和
链接:https://leetcode.cn/problems/two-sum
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int* twoSum(int* nums, int numsSize, int target, int* returnSize){
}
分析:最简单的办法,暴力循环,循环每一个nums的数,再去寻找一个数可以和他相加等于target,就可以进行返回了。题中给出的参数还有指针returnsize,其用处是:找到了两个数相加等于target,则令*returnsize=2,否则为0
再注意note,提示我们需要使用malloc进行分配空间。
题解如下:
int* twoSum(int* nums, int numsSize, int target, int* returnSize){
for(int i=0;i<numsSize;i++)
{
for(int j=i+1;j<numsSize;j++)
{
if(nums[i]+ nums[j]==target)
{
int* ret=malloc(sizeof(int)*2);
ret[0]=i;
ret[1]=j;
*returnSize=2;
return ret;
}
}
}
*returnSize=0;
return NULL;
}扩展:使用哈希表的方法可以将时间复杂度降低到O(n^2)下。
题2 回文数
链接:https://leetcode.cn/problems/palindrome-number
给你一个整数 x ,如果 x 是一个回文整数,返回 true ;否则,返回 false 。
回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。
例如,121 是回文,而 123 不是。
示例 1:
输入:x = 121
输出:true
示例 2:
输入:x = -121
输出:false
解释:从左向右读, 为 -121 。 从右向左读, 为 121- 。因此它不是一个回文数。
示例 3:
输入:x = 10
输出:false
解释:从右向左读, 为 01 。因此它不是一个回文数。
bool isPalindrome(int x)
{
}
分析:
解法1:纯粹的采用数学的思路。举个例子,1221,先取首位和末位进行比较,再接着取顺数第二位和倒数第二位进行比较即可。
1221如何取得首位? 1221/1000=1
1221如何取得末位? 1221%10=1
1221如何取得顺数第二位? 1221%1000=221 221/100=2
1221如何取得倒数第二位? 1221%1000=221 221/10=22 22%10=2
解题核心就在于将上面的步骤修改为一串可以循环进行的且对不同的位数具有适配性的代码来。
如何取首位?这与这个数有多少位是有关系的。
但我们不需要求出有几位,我们只需要实现“有几位就让他除以10*几位”,例如1221就除以1000,122就除以100即可。
int a=1;
while((x/a)>9)
{
a=a*10;
}取末位就很简单了。不管数是几位,直接%10就可以得到末尾了。
那么判断首位末位的代码就很容易的实现了,难在如何去使用当前的x与a去寻找下一个首位与末位。
1221如何取得顺数第二位? 1221%1000=221 221/100=2
1221如何取得倒数第二位? 1221%1000=221 221/10=22 22%10=2
看如上分析,肯定有一步要实现%1000来得到221,再用221去做不同的操作来得到新的首位和末位。
while(x>0)
{
int left=x/a;
int right=x%10;
if(left!=right)
{
return false;
}
/*如何在这里实现*/
}我这里提供一种写法,可以自己试着推演。
可用数学归纳法进行一个总结。其实就是多书写几个不同的位数去尝试“凑”出来。
不同的位数去得到新首位与新末位
121 121%100=21 21/10=2
1221 1221%1000=221 221/100=2
12221 12221%10000=2221 2221/1000=2
%那一步的100,1000等是通过位数来确定的,早在上文就已经有过介绍。又因为第二次进入循环又会遇到x/a,所以和a又会有关系了。
而/那一步就有100,1000等等。这个时候又可以从取倒数第二位来考虑,因为传进入的x%10必须等于2,说明了传进来的x会更改大小为20-30的一个数字
拿1221举例,1221肯定会对1000取余,得到221,221如何去得到22呢?在这里比较靠谱的是/10,
再去看还有一个x/a也要得到2,因为x已经被改为了22,那么a也一定等于10了,说明a从1000变到了10,相当于/100
x=(x%a)/10;
a=a/100;这样就写出了初步的代码,可以接着往下去验证五位数,六位数是否符合其逻辑,再进行更改。经过推演,此式子是合适的。
完整代码如下
bool isPalindrome(int x){
//为负数直接为false
if(x<0)
{
return false;
}
if(x==0)
{
return true;
}
//判断有几位
int a=1;
while((x/a)>9)
{
a=a*10;
}
while(x>0)
{
int left=x/a;
int right=x%10;
if(left!=right)
{
return false;
}
x=(x%a)/10;
a=a/100;
}
return true;
}解法2:反转一半的数字。(本题最推荐解法)
既然是回文数,那么比如1221,将21进行反转后就等于了12
12就等于1*10加上一个2了。
反转12221呢? 得到122
这就是核心的思想,仅反转一半,然后判断前后是否相等即可。
bool isPalindrome(int x){
//首先判断是否为负数或者个位数为0但0是回文数
if(x<0|| x%10==0 && x!=0)
{
return false;
}
//进入判断
int a=0;
while(x>a)
{
a=a*10+x%10;
x/=10;
}
if(x==a || x==a/10)
{
return true;
}
else
{
return false;
}
}如上面的代码,还是首先剔除了明显不是回文数的负数和个位为0的非0数。剩下的思想就如上面的代码所示了。
只有一个需要注意的点,当传入参数为奇数时,如果还是按照if(x==a)来判断是否为回文数,就会出现错误。此时要多加一条判断条件(x==a/10),将中间的奇数位进行一个剔除,因为当传入奇数时,中间的那个数是多少都无所谓。
解法3:将数字转化为字符串求解。
思路简单,应该是最先应该想到的解法。使用sprintf进行字符串的转换。然后定义两个下标,分别从前后开始向中间进行遍历。如果遇到不相等的即返回false。
bool isPalindrome(int x){
char arr[100];
sprintf(arr,"%d",x);
int start=0;
int end=strlen(arr)-1;
while(start<end)
{
if(arr[start]!=arr[end])
{
return false;
}
start++;
end--;
}
return true;
}题3 罗马数字转整数
链接:https://leetcode.cn/problems/roman-to-integer
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1 。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。
X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。
C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数。
示例 1:
输入: s = "III"
输出: 3
示例 2:
输入: s = "IV"
输出: 4
示例 3:
输入: s = "IX"
输出: 9
示例 4:
输入: s = "LVIII"
输出: 58
解释: L = 50, V= 5, III = 3.
示例 5:
输入: s = "MCMXCIV"
输出: 1994
解释: M = 1000, CM = 900, XC = 90, IV = 4.
提示:
1 <= s.length <= 15
s 仅含字符 ('I', 'V', 'X', 'L', 'C', 'D', 'M')
题目数据保证 s 是一个有效的罗马数字,且表示整数在范围 [1, 3999] 内
题目所给测试用例皆符合罗马数字书写规则,不会出现跨位等情况。
IL 和 IM 这样的例子并不符合题目要求,49 应该写作 XLIX,999 应该写作 CMXCIX 。
关于罗马数字的详尽书写规则,可以参考 罗马数字 - Mathematics 。
int romanToInt(char* s)
{}分析:从题上分析,罗马数字不过是一个简单的加减,当左边的数大于右边的,就加左边的,若是左边的小于右边的,就减左边的。
处理字符串通常的想法是使用指针进行遍历。
那我们就可以从最右边开始进行遍历,因为最后一个是一定会加上去的,将每次得到的一个置为flag1,他后面那个置为flag2,进行比较,确定加减。由于是倒着来的,所以flag2先置为0即可。
int romanToInt(char* s) {
int flag1 = 0;
int sum = 0;
int flag2 = 0;
int strLength = strlen(s);
for (strLength-1; strLength >= 0; --strLength) {
switch (*(s + strLength)) {
case 'I': flag1 = 1;
break;
case 'V': flag1 = 5;
break;
case 'X': flag1 = 10;
break;
case 'L': flag1 = 50;
break;
case 'C': flag1 = 100;
break;
case 'D': flag1 = 500;
break;
case 'M': flag1 = 1000;
break;
}
flag2 = flag2 > flag1 ? -flag1 : flag1;
sum += flag2;
}
return sum;
}题4 最长公共前缀
链接:https://leetcode.cn/problems/longest-common-prefix
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入:strs = ["flower","flow","flight"]
输出:"fl"
示例 2:
输入:strs = ["dog","racecar","car"]
输出:""
解释:输入不存在公共前缀。
提示:
1 <= strs.length <= 200
0 <= strs[i].length <= 200
strs[i] 仅由小写英文字母组成
char * longestCommonPrefix(char ** strs, int strsSize){}分析:求公共前缀,那么可以先求出第一个字符串的长度,公共前缀肯定不可以超过每一个字符串的长度。再让第一个字符串和后面的字符串进行比较,进而每一次确定新的公共前缀长度,做法是在第一个字符串里进行截断。
大题思路如上,但是有几个需要注意的点。
本题输入的是字符串数组。字符串数组有两种表达方式,普通的当作二维数组来处理或者指针数组。
char str1[3][6] = { "aaa","ccc","fff" };
char* str2[] = { "aaa","bbb","ccc" };
printf("%c ", str1[2][1]);
printf("%s", str2[2]);可以注意到接口函数传入的是一个二级指针。我们在哪里见过二级指针呢?一般只有需要改变指针的情况下我们才会传入指针的指针,也就是二级指针。 就像传入一个一维数组,我们可以写为int* arr,那么针对指针数组,类比一下,传入的就是char** strs了。
那么就可以使用strs【0】来代表第一个字符串了。相应的就可以使用strlen获取其长度。再用一个指针指向他,与余下的几个字符串作比较,不断的更新maxlen,进行截断。
还需要注意的是需要将num【maxlen】置为斜杠0,因为字符串数组的"/0"在哪里是不清楚的。
一个简单的例子
int main()
{
//字符串
char arr1[] = "123";
printf("%s\n", arr1);
//字符数组
char arr2[] = { '1','2','3' };
printf("%s\n", arr2);
}
第二个的输出有一串乱码,那就是因为"/0"位置的不确定造成的。
所以完整代码如下所示。
多记两笔,之所以采用如下的while循环而非常规的for循环遍历,是因为我们直接将第一个字符数组长度当作了maxlen,但后面可能会有更短的数组,可能会造成越界的情况,所以就做出了如下的处理避免数组的越界。
char * longestCommonPrefix(char ** strs, int strsSize){
int maxlen = strlen(strs[0]);
char* num = strs[0];
for (int j = 1; j < strsSize; j++)
{
int i = 0;
while (i < maxlen && strs[j][i] == num[i])//第0行先于第1行比较然后记录多少个字节一样
{
i++;
}
maxlen= i;//把得到的数再返回给a
}
num[maxlen] = '\0';
return num;
}小记:其实当时做这道题思考并不全面,后来在复盘时将代码搬到了 vs上自己去写,才明白,传进来的是个指针数组,这个指针数组里包含了多个字符数组。所以num【maxlen】='\0'时没有任何问题的,指针num从来指向的都是字符数组,而非常量。
题5 合并两个有序链表
链接:https://leetcode.cn/problems/merge-two-sorted-lists
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
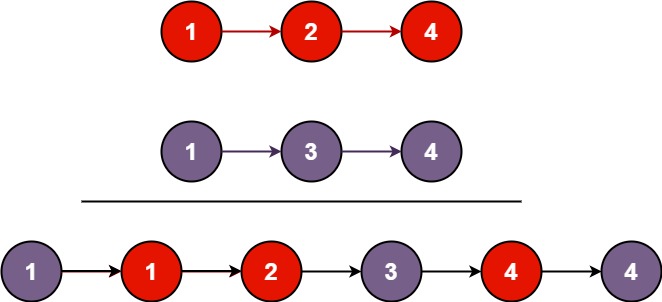
输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = []
输出:[]
示例 3:
输入:l1 = [], l2 = [0]
输出:[0]
提示:
两个链表的节点数目范围是 [0, 50]
-100 <= Node.val <= 100
l1 和 l2 均按 非递减顺序 排列
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2){}分析:这道题需要数据结构的单向链表的一些知识。
思路也很简单,就是建立一个新的链表,使用两个指针不断的去遍历两个链表(题目已经给出,list1与list2),取小的那个放入新链表,当一个链表的list指向NULL后,就说明这个链表已经被遍历完,那么就只需要将另一个没遍历完的数值较大的链表直接连到新链表之后即可。整体实现非常简单。
还要注意代码块上面的结构体。有val和指针next是需要用到的东西。
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2){
struct ListNode* head=NULL;
struct ListNode* tail=NULL;
if(list1==NULL)
{
return list2;
}
if(list2==NULL)
{
return list1;
}
while(list1!=NULL && list2!=NULL)
{
if(list1->val>list2->val)
{
if(tail==NULL)
{
head=tail=list2;
}
else
{
tail->next=list2;
tail=tail->next;
}
list2=list2->next;
}
else{
if(tail==NULL)
{
head=tail=list1;
}
else
{
tail->next=list1;
tail=tail->next;
}
list1=list1->next;
}
}
if(list1==NULL)
{
tail->next=list2;
}
if(list2==NULL)
{
tail->next=list1;
}
return head;
}题6 有效的括号
链接:https://leetcode.cn/problems/valid-parentheses
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
每个右括号都有一个对应的相同类型的左括号。
示例 1:
输入:s = "()"
输出:true
示例 2:
输入:s = "()[]{}"
输出:true
示例 3:
输入:s = "(]"
输出:false
提示:
1 <= s.length <= 104
s 仅由括号 '()[]{}' 组成
bool isValid(char* s)
{}分析:使用栈的思想应该是本题的正常解法。当输入{[(三种字符时,就入栈,碰到)}]三种字符时,
就弹出一个栈顶元素和这三个字符进行匹配。因为表达式要return true的话就必须匹配,而匹配与否应该从里往外看,也就是类似(【】),位于栈顶的一定是【,而下一个遇到的往右边的字符必须是 】才是合规的。利用栈的特性可以完美解决这一点。
本题选用了顺序栈和链式栈两种模式进行答题。
静态栈
因为力扣给的字符串可以长到10000,但顺序栈又无法扩容,只好给他10001了。
并且用flag来规避只有{(【这三种字符的情况。
#define max 10001
typedef struct stack
{
char data[max];
int size;
}stack;
bool isValid(char* s) {
stack sk;
sk.size = 1;
int flag = 0;
for(int i=0;s[i]!=0; i++)
{
switch (s[i])
{
case '{':
case '(':
case '[':
sk.data[sk.size] = s[i];
sk.size++;
flag++;
break;
case '}':
case ')':
case ']':
if ((sk.data[sk.size - 1] =='{'&& s[i]=='}')||(sk.data[sk.size-1]=='['&& s[i]==']')||(sk.data[sk.size-1]=='('&&s[i]==')'))
{
sk.size--;
flag--;
}
else
{
return false;
}
break;
}
}
if (flag == 0)
return true;
else
return false;
}动态栈
灵活的开辟空间而无需扩容。但核心思想与静态栈无异。
typedef struct stack
{
char* data;
int size;
int capacity;
}stack;
//初始化
void stackinit(stack *p)
{
p->data = (char*)malloc(sizeof(char) * 4);
p->size = 1;
p->capacity = 4;
}
//入栈
void stackpush(stack *p,char x)
{
if (p->capacity == p->size)
{
char* tmp = realloc(p->data, p->capacity * 2 * sizeof(char));
p->data = tmp;
p->capacity *= 2;
}
p->data[p->size] = x;
p->size++;
}
bool isValid(char* s) {
stack sk;
stackinit(&sk);
int flag = 0;
for (int i = 0; s[i] != 0; i++)
{
switch (s[i])
{
case '{':
case '(':
case '[':
stackpush(&sk, s[i]);
flag++;
break;
case '}':
case ')':
case ']':
if ((sk.data[sk.size - 1] == '{' && s[i] == '}') || (sk.data[sk.size - 1] == '[' && s[i] == ']') || (sk.data[sk.size - 1] == '(' && s[i] == ')'))
{
sk.size--;
flag--;
}
else
{
return false;
}
break;
}
}
if (flag == 0)
return true;
else
return false;
}题7 删除有序数组中的重复项
链接:https://leetcode.cn/problems/remove-duplicates-from-sorted-array
给你一个 升序排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。
由于在某些语言中不能改变数组的长度,所以必须将结果放在数组nums的第一部分。更规范地说,如果在删除重复项之后有 k 个元素,那么 nums 的前 k 个元素应该保存最终结果。
将最终结果插入 nums 的前 k 个位置后返回 k 。
不要使用额外的空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
判题标准:
系统会用下面的代码来测试你的题解:
int[] nums = [...]; // 输入数组
int[] expectedNums = [...]; // 长度正确的期望答案int k = removeDuplicates(nums); // 调用
assert k == expectedNums.length;
for (int i = 0; i < k; i++) {
assert nums[i] == expectedNums[i];
}
如果所有断言都通过,那么您的题解将被 通过。
示例 1:
输入:nums = [1,1,2]
输出:2, nums = [1,2,_]
解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。
示例 2:
输入:nums = [0,0,1,1,1,2,2,3,3,4]
输出:5, nums = [0,1,2,3,4]
解释:函数应该返回新的长度 5 , 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4 。不需要考虑数组中超出新长度后面的元素。
提示:
1 <= nums.length <= 3 * 104
-104 <= nums[i] <= 104
nums 已按 升序 排列
分析:
解法1:纯数学思路,使用后面的元素向前覆盖。比较取巧,可以试着在纸上画画步骤。
int removeDuplicates(int* nums, int numsSize){
int k=0;
for(int i=1;i<numsSize;i++){
if(nums[k]!=nums[i]){
nums[++k]=nums[i];
}
}
return k+1;
}解法2:使用双指针的思想。这种解法个人认为更容易想到一些。应该重点理解双指针在这样题型上的一个应用。
将两个指针初始时都指向数组头,fast负责寻找与slow不一样的元素,找到了就使slow++,将值赋给slow,再让fast++去寻找下一个。
当遍历完整个数组,直接返回slow+1即可。因为slow是下标,比题目要求的返回长度要少1
int removeDuplicates(int* nums, int numsSize){
int fast = 0, slow = 0;//fast去找,slow来存
while(fast < numsSize){
if(nums[fast] == nums[slow]){
++fast;//相等则寻找不重复元素
}
else{
++slow;
nums[slow] = nums[fast];
++fast;
}
}
return slow+1;
}















 63
63











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









