










文章目录
有关 Github \text{Github} Github仓库,欢迎来 Star \text{Star} Star
1. \textbf{1. } 1. 概述: 分类定义 & \textbf{\&} &评价指标
1️⃣分类概念:
- 定义:将数据分为不同类别的过程
- 过程:学习已有数据的特征和标签 → \text{→} →构建模型 → \text{→} →将新数据分配到预定义类别中
2️⃣评估方法
方法 描述 Holdout Method \text{Holdout Method} Holdout Method 将数据集(随机)分为训练集/测试集分别训练/测试 Random Subsampling \text{Random Subsampling} Random Subsampling 进行多轮 Holdout Method \text{Holdout Method} Holdout Method,取多轮评估的平均作为最终结果 Cross-Validation \text{Cross-Validation} Cross-Validation 将数据分为 k k k个小块,让每一小块轮流作测试集(其余 k -1 k\text{-1} k-1块为训练集 3️⃣评估指标
- Confusion Matrix \text{Confusion Matrix} Confusion Matrix:
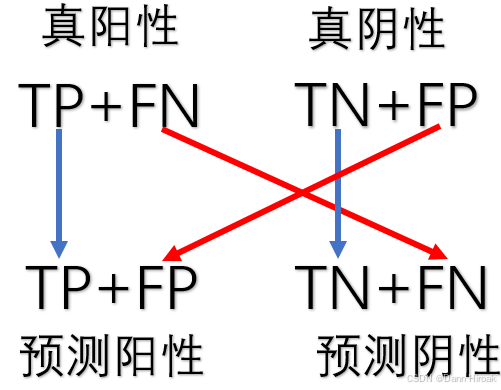
实际\预测 C 1 \mathbf{C}_1 C1 ¬ C 1 \neg \mathbf{C}_1 ¬C1 C 1 \mathbf{C}_1 C1 True Positives(TP) \text{True Positives(TP)} True Positives(TP)真阳性 False Negatives(FN) \text{False Negatives(FN)} False Negatives(FN)假阴性 ¬ C 1 \neg \mathbf{C}_1 ¬C1 False Positives(FP) \text{False Positives(FP)} False Positives(FP)假阳性 True Negatives(TN) \text{True Negatives(TN)} True Negatives(TN)真阴性 - 准确率/误差率:
指标 计算 含义 Accuracy \text{Accuracy} Accuracy TP+TN ALL \cfrac{\text{TP+TN}}{\text{ALL}} ALLTP+TN 预测正确的总占比 Error \text{Error} Error 1 − Accuracy 1-\text{Accuracy} 1−Accuracy 预测错误的总占比 - 敏感性/特异性:
- 敏感性/特异性含义:
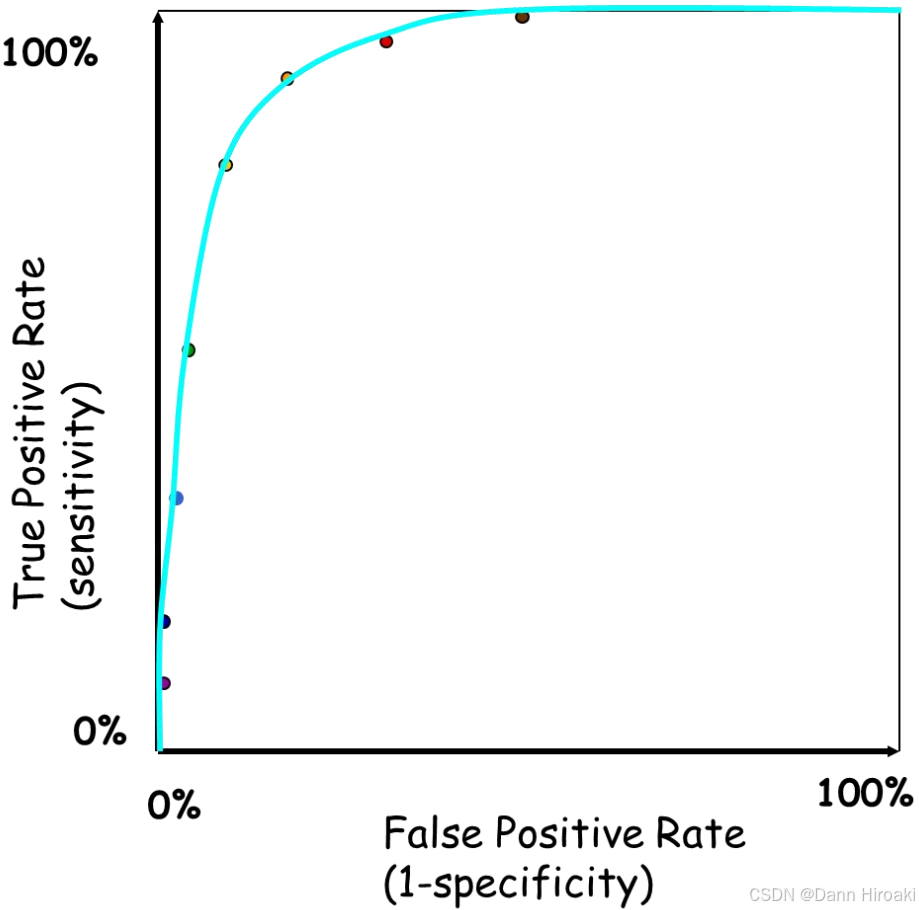
指标 计算 含义 Sensitivity(Recall) \text{Sensitivity(Recall)} Sensitivity(Recall) TP TP+FN \cfrac{\text{TP}}{\text{TP+FN}} TP+FNTP 检出 TP \text{TP} TP的能力 Specificity \text{Specificity} Specificity TN TN+FP \cfrac{\text{TN}}{\text{TN+FP}} TN+FPTN 避免 FP \text{FP} FP的能力 - ROC \text{ROC} ROC曲线:即 Specificity − (1-Specificity) \text{Specificity}-\text{(1-Specificity)} Specificity−(1-Specificity)曲线, AUC \text{AUC} AUC值为其横轴积分
- 召回/精度:
指标 计算 含义 Recall(Sensitivity) \text{Recall(Sensitivity)} Recall(Sensitivity) TP TP+FN \cfrac{\text{TP}}{\text{TP+FN}} TP+FNTP 真实阳性中, TP \text{TP} TP比例 Precision \text{Precision} Precision TP TP+FP \cfrac{\text{TP}}{\text{TP+FP}} TP+FPTP 预测阳性中, TP \text{TP} TP比例 - F β -score \displaystyle\text {F}_{\beta}\text{-score} Fβ-score:
指标 计算 含义 F β -score \displaystyle\text {F}_{\beta}\text{-score} Fβ-score ( 1 + β 2 ) × Precision×Recall β ×Precision+Recall (1\text{+}\beta^2) \text{×} \cfrac{\text{Precision} \text{×} \text {Recall }}{\beta{}\text{×}\text {Precision+} \text{Recall}} (1+β2)×β×Precision+RecallPrecision×Recall β <1 \beta{}\text{<1} β<1/ β >1 \beta{}\text{>1} β>1时 Preci. \text{Preci.} Preci./ Recall \text{Recall} Recall影响更大 F 1 -score \displaystyle\text {F}_1\text{-score } F1-score 2 × Precision×Recall Precision+Recall 2 \text{×} \cfrac{\text {Precision} \text{×} \text {Recall}}{\text {Precision+} \text {Recall}} 2×Precision+RecallPrecision×Recall 二者均等重要的调和平均
2. \textbf{2. } 2. 决策树
2.1. \textbf{2.1. } 2.1. 决策树概述
1️⃣决策树的结构:
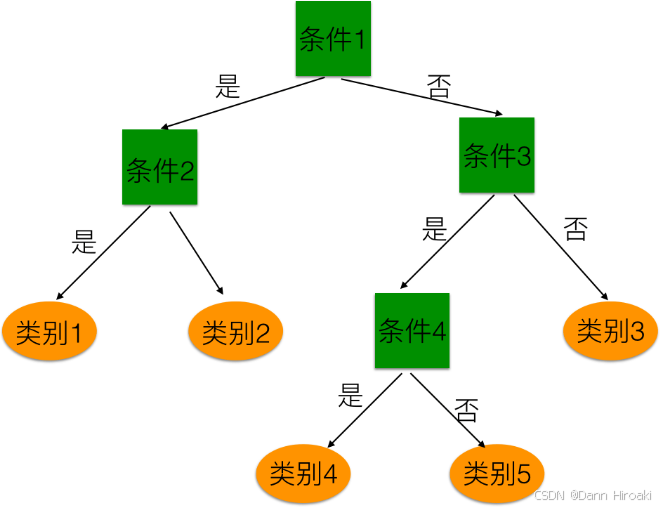
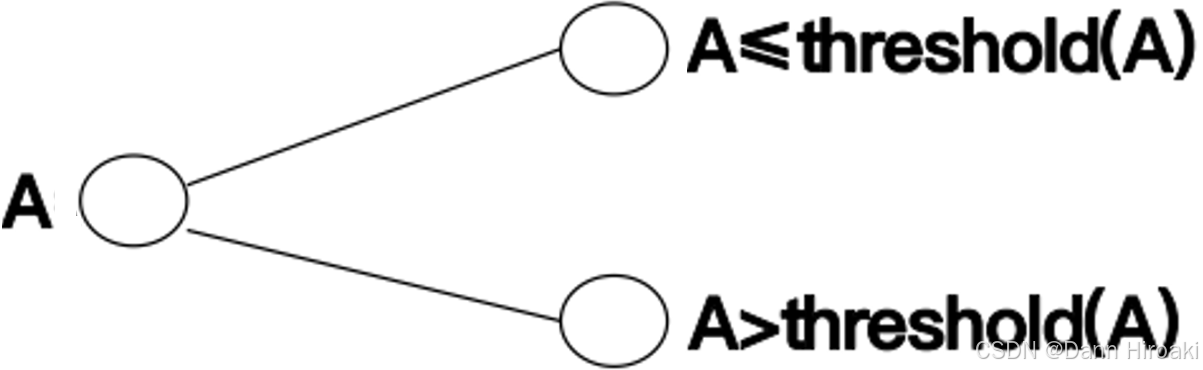
- 对应关系:中间(根)结点 ↔ 对应 \xleftrightarrow{对应} 对应 对某属性的测试,分支 ↔ 对应 \xleftrightarrow{对应} 对应 属性值,叶结点 ↔ 对应 \xleftrightarrow{对应} 对应 实例所属类别
- 分类流程:把实例从根结点一层层排列到叶子结点
2️⃣决策树的分类策略
- 属性的选择:基于启发式/统计测试,使得信息增益/增益率/ Gini \text{Gini} Gini指标等度量值最好
- 终止划分条件:无样本剩下 or \text{or} or 给定的某节点所有样本属于一类 or \text{or} or 没有属性用于下一步划分
3️⃣有关符号
集合符号 集合样本数 含义 D {D} D ∣ D ∣ \mid{}D\mid{} ∣D∣ 训练样本集,含 m m m个类别 C i ⊆ D ( i = 1 … m ) C_i\text{⊆}D(i\text{=}1\dots{}m) Ci⊆D(i=1…m) C i , D C_{i,D} Ci,D ∣ C i , D ∣ \mid{}C_{i,D}\mid{} ∣Ci,D∣ D D D中 C i C_i Ci类样本的集合 2.2. \textbf{2.2. } 2.2. 决策树的度量指标
1️⃣信息增益:
- 信息熵:划分后集合的混乱程度
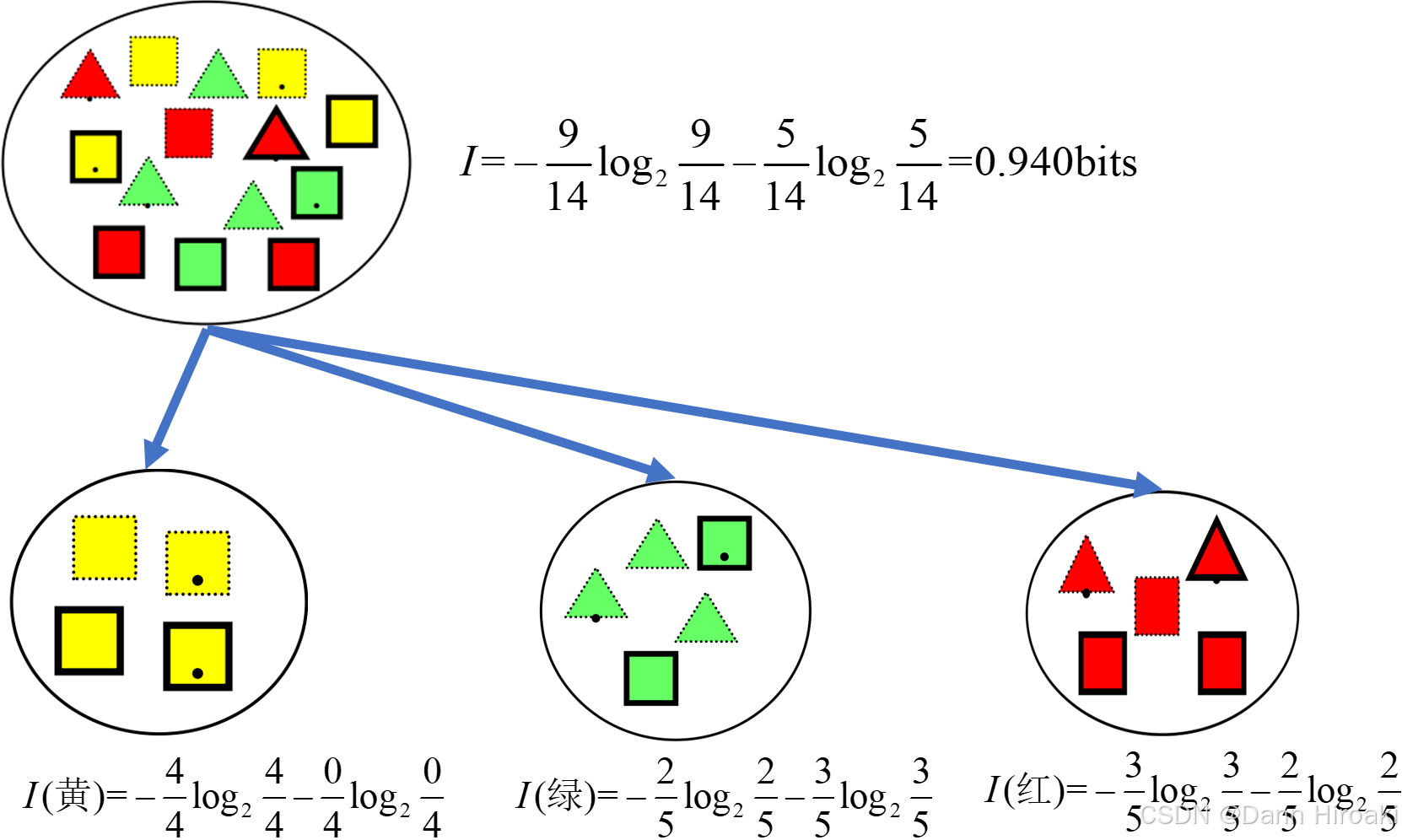
- 集合: D D D包含了 n n n个类别 C i C_i Ci(如下)
类别 C 1 C_1 C1 C 2 C_2 C2 C 3 C_3 C3 … C n C_n Cn 元素数 N C 1 N_{C_1} NC1 N C 2 N_{C_2} NC2 N C 3 N_{C_3} NC3 … N C n N_{C_n} NCn 元素频率 P 1 = N C 1 N 总 P_1\text{=}\cfrac{N_{C_1}}{N_总} P1=N总NC1 P 2 = N C 2 N 总 P_2\text{=}\cfrac{N_{C_2}}{N_总} P2=N总NC2 P 3 = N C 3 N 总 P_3\text{=}\cfrac{N_{C_3}}{N_总} P3=N总NC3 … P n = N C n N 总 P_n\text{=}\cfrac{N_{C_n}}{N_总} Pn=N总NCn - 熵值: Info ( D ) = − ∑ i = 1 n P i log P i \text{Info}(D)\text{=}\displaystyle{}-\sum_{i=1}^{n}P_i\log{P_i} Info(D)=−i=1∑nPilogPi (单位为 bits \text{bits} bits)
- 条件熵:按属性划分的信息熵
- 划分: D → 划分为 v 个子集 有 v 个值的属性 A { D 1 , D 2 , … , D v } D\xrightarrow[划分为v个子集]{有v个值的属性A}\{D_1,D_2,\dots,D_v\} D有v个值的属性A划分为v个子集{D1,D2,…,Dv},注意 D i D_i Di由于其它属性存在 → \text{→} →内部依然分类
- 熵值: D D D关于属性 A A A划分的熵为 Info A ( D ) = ∑ j = 1 v ∣ D j ∣ ∣ D ∣ ×Info ( D j ) \text{Info}_A(D)\text{=}\displaystyle{}\sum_{j=1}^{v}\cfrac{|D_j|}{|D|}\text{×}\text{Info}(D_j) InfoA(D)=j=1∑v∣D∣∣Dj∣×Info(Dj)
- 信息增益:
- 含义:划分导致的不确定性降低程度,即 Gain=Info ( D ) − Info A ( D ) \text{Gain=Info}(D)-\text{Info}_A(D) Gain=Info(D)−InfoA(D)
- 意义:选择有最大信息增益的属性来划分
2️⃣信息增益率:
- 划分熵: SplitInfo ( A ) = − ∑ j = 1 m ∣ D j ∣ ∣ D ∣ log 2 ( ∣ D j ∣ ∣ D ∣ ) → \displaystyle{}\text{SplitInfo}(A)\text{=}-\sum_{j=1}^m \cfrac{\left|D_j\right|}{|D|} \log _2\left(\frac{\left|D_j\right|}{|D|}\right)\text{→} SplitInfo(A)=−j=1∑m∣D∣∣Dj∣log2(∣D∣∣Dj∣)→划分越均匀值越低 → 衡量 \xrightarrow{衡量} 衡量划分有效 ? ? ?
- 信息增益率: GainRatio ( A ) = Gain ( A ) SplitInfo ( A ) → \text{GainRatio}(A)\text{=}\cfrac{\operatorname{Gain}(A)}{\operatorname{SplitInfo}(A)}\text{→} GainRatio(A)=SplitInfo(A)Gain(A)→避免信息增益的偏向性
- 意义:选择有最大信息增益率的属性来划分
3️⃣ Gini \text{Gini} Gini指数
- 数据集的 Gini \text{Gini} Gini指数:
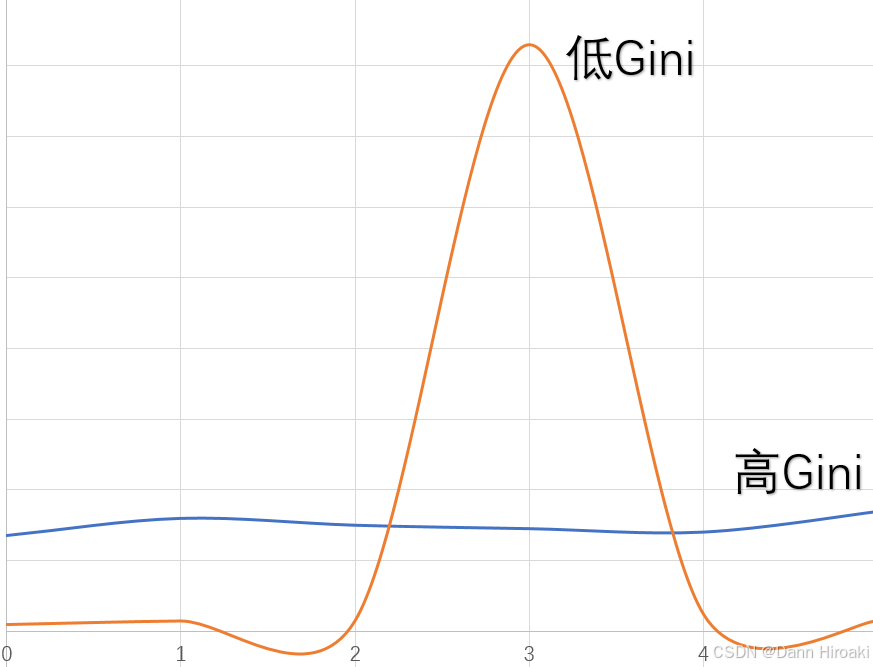
- 定义: Gini ( D ) = 1 − ∑ j = 1 n p j 2 \displaystyle{}\text{Gini}(D)\text{=}1-\sum_{j=1}^n p_j^2 Gini(D)=1−j=1∑npj2,其中 p j p_j pj为类别 j j j样本数占总样本数比例
- 含义:衡量样本分布的均匀程度 → { Gini值越大→样本越分散→纯度低 Gini值越小→样本越集中→纯度高 \text{→}\begin{cases}\text{Gini}值越大\text{→}样本越分散\text{→}纯度低\\\\ \text{Gini}值越小\text{→}样本越集中\text{→}纯度高 \end{cases} →⎩ ⎨ ⎧Gini值越大→样本越分散→纯度低Gini值越小→样本越集中→纯度高
- 基于属性 A A A分裂的 Gini \text{Gini} Gini指数
- 定义:对于 D → 属性 A ( 含有 v 个值 ) { D 1 , D 2 , . . . , D v } D\xrightarrow{属性A(含有v个值)}\{D_1,D_2,...,D_v\} D属性A(含有v个值){D1,D2,...,Dv}有 Gini A ( D ) = ∑ i = 1 v ∣ D i ∣ ∣ D ∣ Gini ( D i ) \displaystyle{}\text{Gini}_A(D)\text{=}\sum_{i=1}^{v}\cfrac{\left|D_i\right|}{|D|} \text{Gini}\left(D_i\right) GiniA(D)=i=1∑v∣D∣∣Di∣Gini(Di)
- 含义:衡量 D D D经过 A A A分裂后的整体不纯度
- 基于属性 A A A分裂的不纯度减少
- 定义: Δ Gini ( A ) =Gini ( D ) − Gini A ( D ) \Delta{\text{Gini}}(A)\text{=}\text{Gini}(D)-\text{Gini}_A(D) ΔGini(A)=Gini(D)−GiniA(D)
- 意义:选择能够使 Δ Gini ( A ) \Delta{\text{Gini}(A)} ΔGini(A)最大 / Δ Gini A /\Delta{\text{Gini}_A} /ΔGiniA最小最小的属性进行结点分裂
🙃度量的对比和总结
指标 分裂属性选择 分裂过程倾向于 信息增益 使信息增益 Gain ( A ) \text{Gain}(A) Gain(A)最大的属性 多值属性 信息增益率 使信息增益率 GainR. ( A ) \text{GainR.}(A) GainR.(A)最大的属性 不平衡分裂(某些子集极小) Gini \text{Gini} Gini指数 使不纯度减少 Δ Gini ( A ) \Delta{\text{Gini}}(A) ΔGini(A)最大(纯度增加)的属性 多值属性 & \& &分裂后纯度提高 2.3. \textbf{2.3. } 2.3. 一些经典的决策树算法
1️⃣ ID3 \text{ID3} ID3(迭代二分 3 3 3)
- 思想:默认属性值离散 → \text{→} →结点分裂时(遍历每个特征的信息增益)选择信息增益最大的特征
- 特点:倾向于选择多指特征(不合理),对噪声敏感,方法简单应用广
2️⃣ C4.5 \text{C4.5} C4.5算法:基于 ID3 \text{ID3} ID3的改进
- 离散属性选择:直接选择结点分裂时==信息增益率==最大的特征 → \text{→} →克服了对值属性的倾向性
- 连续属性离散化:
- 排序:对连续属性 A A A,其在 D D D中取有 m m m个离散属性值,排序后得到 { a 1 , a 2 , … , a m } \left\{a_1, a_2, \ldots, a_m\right\} {a1,a2,…,am}
- 分割:对 { a 1 , a 2 , … , a m } \left\{a_1, a_2, \ldots, a_m\right\} {a1,a2,…,am}有 m - 1 m\text{-}1 m-1种方式一分为二,选择信息增益率最大的分割以进行
- 递归:可对划分得子集 { a 1 , a 2 , … , a k } \left\{a_1, a_2, \ldots, a_k\right\} {a1,a2,…,ak}或 { a k + 1 , a k + 2 , … , a m } \left\{a_{k+1}, a_{k+2}, \ldots, a_m\right\} {ak+1,ak+2,…,am}进一步按此划分
- 终止:直到达到某阈值, { a 1 , a 2 , … , a m } \left\{a_1, a_2, \ldots, a_m\right\} {a1,a2,…,am}被分为互不交叉的 K K K块(转化为 K K K个离散值)
- 对缺失数据的处理:
- 含义:数据的某个属性的值会缺失,需要根据已知值来估计(以填充)
- 策略:( Quinlan \text{Quinlan} Quinlan)计算每个属性 a i a_i ai值出现的概率 P ( a i ) → P(a_i)\text{→} P(ai)→为缺失值 e i e_i ei赋予概率分布 P ( a i ) P(a_i) P(ai)
- 生成规则:
- 逻辑:将根 → \text{→} →叶路径转化为如下 IF-THEN \text{IF-THEN} IF-THEN规则,由此决策树也变为 IF-THEN \text{IF-THEN} IF-THEN规则集合
IF [中间节点所有条件] THEN [根节点类别]- 存储:规则(路径)会被存储在数组中,每行对应每个路径
3️⃣ CART \text{CART} CART算法:采用二元化分的二叉决策树
- 划分方式:
- 离散属性:计算每种二元分裂的 Gini \text{Gini} Gini指数,选择 Gini \text{Gini} Gini最小(纯度最高)的方式分裂
- 连续属性:排序后考虑每个分割点,选择使得 Gini \text{Gini} Gini最小的分割点进行分割
- 递归划分:在划分得到的子集上递归地进行下一次划分 → \text{→} →直到达到终止条件
- 终止条件:
- 叶结点:样本数为 1 1 1,或者小于某给定值 N min N_{\min} Nmin
- 属性:结点中样本同属一类,即无更多属性可供分裂
- 高度:决策树高度达到用户预设
2.4. \textbf{2.4. } 2.4. 决策树的其它有关内容
1️⃣决策树的过拟合
- 欠拟合与过拟合:
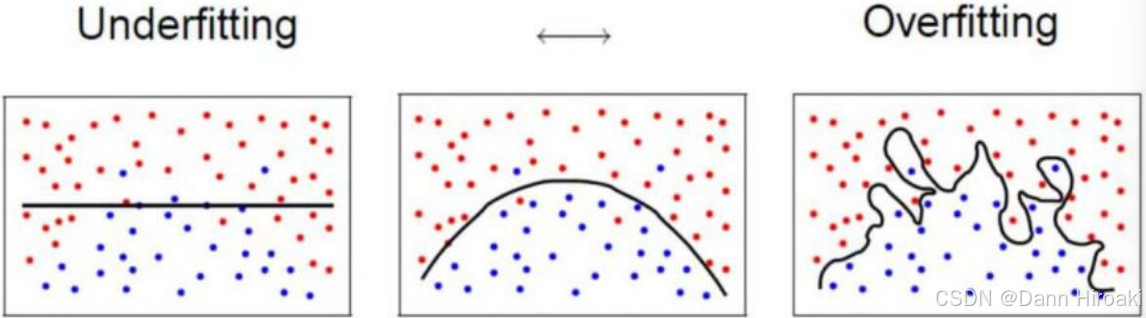
类型 模型表现 成因 欠拟合 训练集❌/测试集❌ 模型过于简单 过拟合 训练集✅/测试集❌ 决策树分支过多 → \text{→} →对噪声的过分拟合,训练集太小 - 欠拟合的解决:剪枝
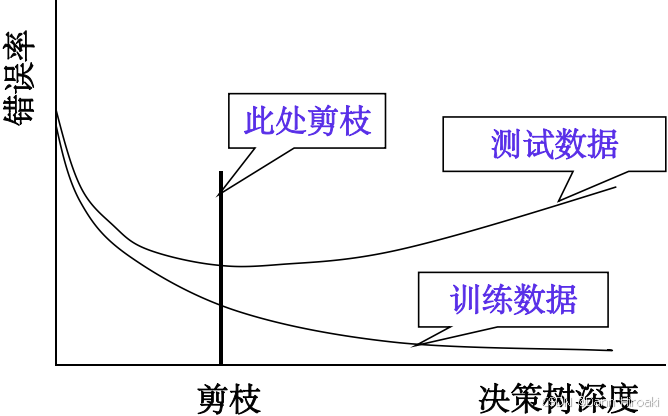
方式 时机 操作 剪枝标准 预剪枝 树构建时 使结点终止分裂 结点实例少于某值/分裂不使纯度提高时 后剪枝 树构建后 中间节点 → 替换为 \xrightarrow{替换为} 替换为叶节点 剪枝后能否降低错误率 2️⃣集成学习
- 含义:单个机器学习(弱学习算法) → 整合 某种规则 \xrightarrow[整合]{某种规则} 某种规则整合集成学习(强学习算法),由此获得更好的效果
- Bagging \text{Bagging} Bagging:并行逻辑
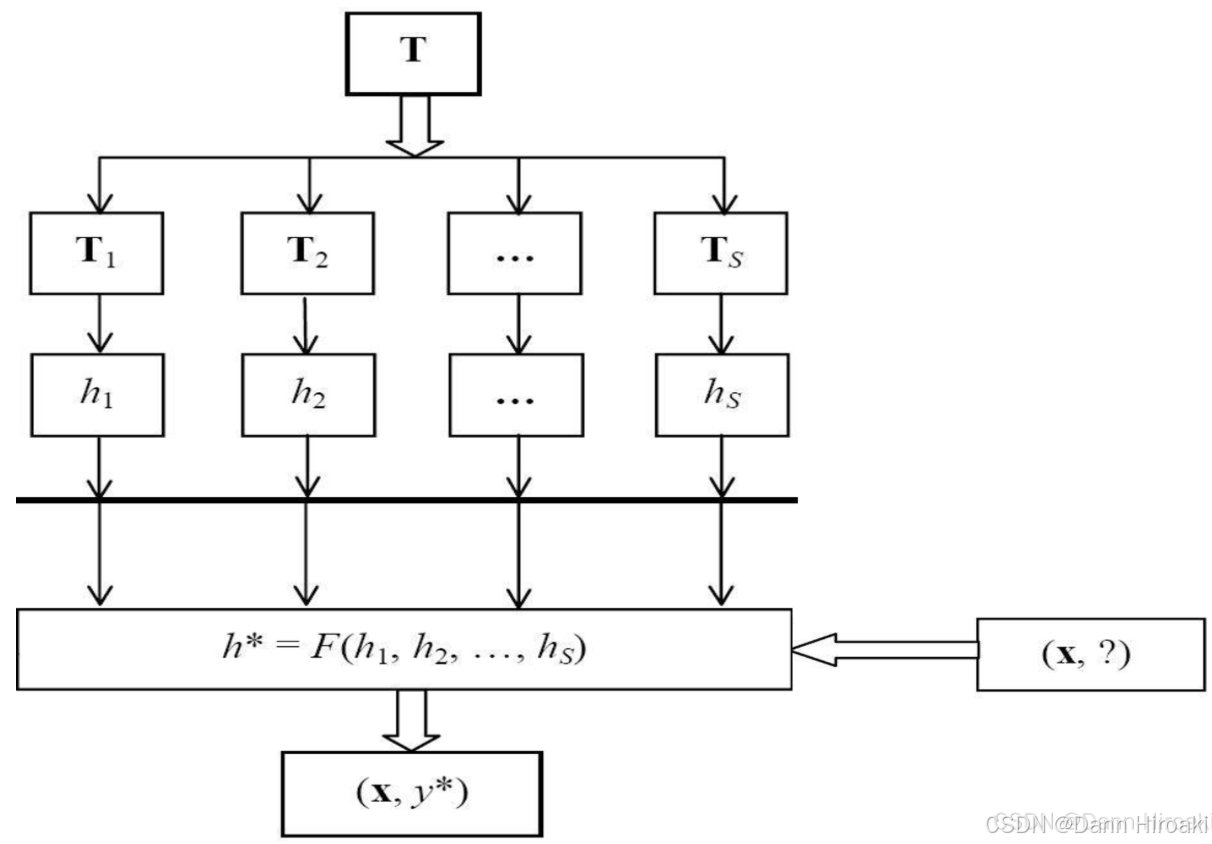
- 流程:产生 S S S个训练集 → \text{→} →训练 S S S个分类器 → \text{→} →预测时票选出 S S S个预测结果中出现最多的
- AdaBoost \text{AdaBoost} AdaBoost:串行逻辑
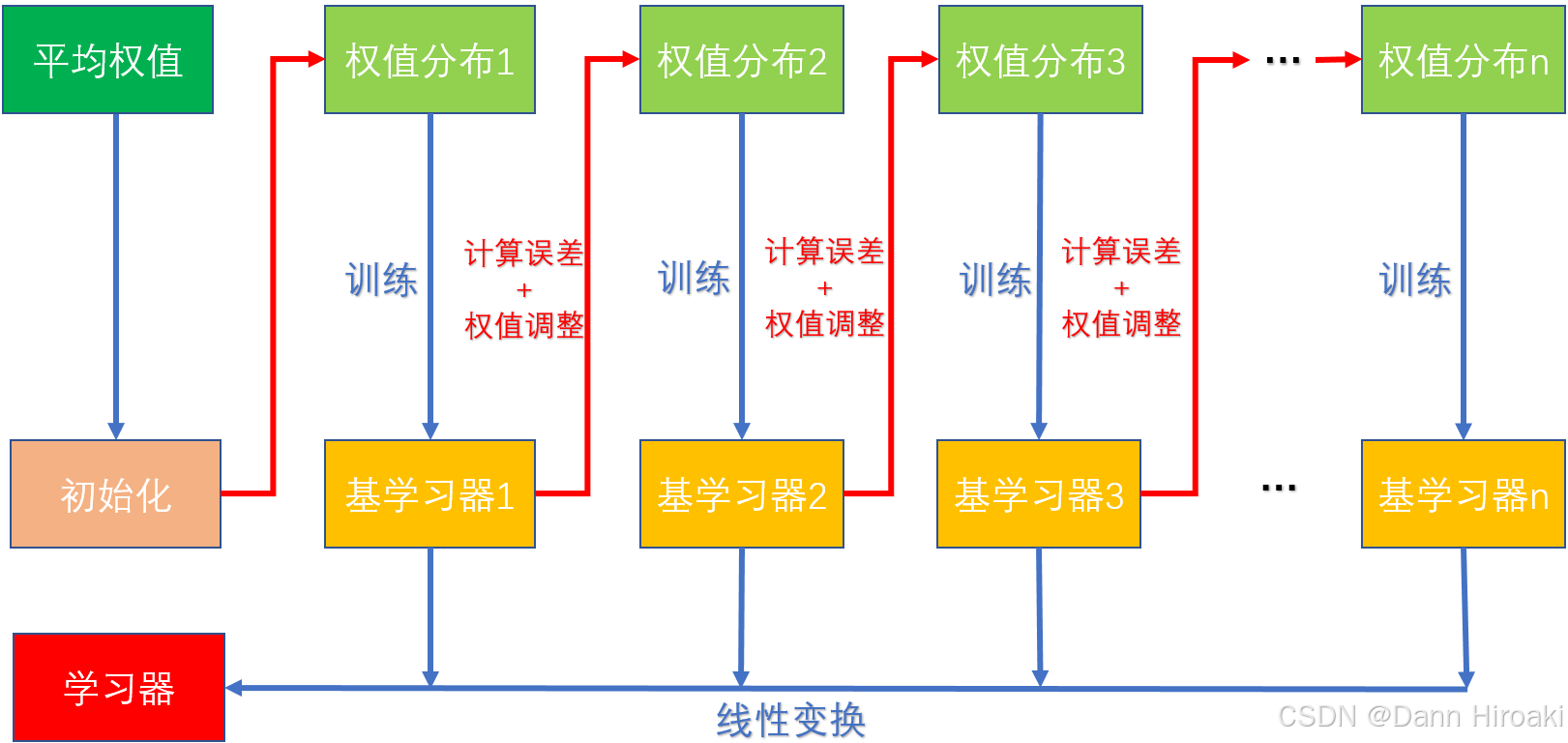
操作 含义 初始化 对于含 N N N个样本的数据集,赋予每个样本相同的权值 1 N \cfrac{1}{N} N1 训练 使用当前权重训练基学习器,并计算其在训练集上的误差 更新权 降低被正确分类的样本的权值,提升被错误分类样本的权值 线性组合 让误差大的基学习器比例大,误差小的比例小,进行线性组合 3️⃣梯度与梯度提升树:样本对损失函数的负梯度 → 当作 / 估计 \xrightarrow{当作/估计} 当作/估计该样本残差
- 梯度提升:对样本 [ ( x 1 , y 1 ) ( x 2 , y 2 ) . . . ( x n , y n ) ] \begin{bmatrix}(x_1,y_1)\\(x_2,y_2)\\...\\(x_n,y_n)\end{bmatrix} (x1,y1)(x2,y2)...(xn,yn) 拟合(回归),使损失函数 J = ∑ i L ( F ( x i ) , y i ) J\text{=}\displaystyle{}\sum_{i}L(F(x_i),y_i) J=i∑L(F(xi),yi)最小
- 拟合:对当下的拟合 [ F ( x 1 ) F ( x 2 ) . . . F ( x n ) ] \begin{bmatrix}F(x_1)\\F(x_2)\\...\\F(x_n)\end{bmatrix} F(x1)F(x2)...F(xn) 有残差 [ h ( x 1 ) = y 1 - F ( x 1 ) h ( x 2 ) = y 2 - F ( x 2 ) . . . . . . h ( x n ) = y n - F ( x n ) ] \begin{bmatrix}h(x_1)\text{=}y_1\text{-}F(x_1)\\h(x_2)\text{=}y_2\text{-}F(x_2)\\......\\h(x_n)\text{=}y_n\text{-}F(x_n)\end{bmatrix} h(x1)=y1-F(x1)h(x2)=y2-F(x2)......h(xn)=yn-F(xn) 需调整 c h ch ch来最小化 J J J
- 梯度: ∂ J ∂ F ( x i ) = F ( x i ) − y i ← { L ( y i , F ( x i ) ) = ( y − F ( x ) ) α α ( 以其为例 , 可选其它 ) ∂ J ∂ F ( x i ) = ∂ ∑ i L ( y i , F ( x i ) ) ∂ F ( x i ) = ∂ L ( y i , F ( x i ) ) ∂ F ( x i ) \cfrac{\partial J}{\partial F(x_i)}\text{=}F(x_i)-y_i\text{ ←} \begin{cases} \displaystyle{}L(y_i, F(x_i))\text{=}\cfrac{(y-F(x))^\alpha}{\alpha}(以其为例, 可选其它)\\\\ \displaystyle{}\cfrac{\partial J}{\partial F(x_i)}=\cfrac{\displaystyle{}\partial \sum_i L(y_i, F(x_i))}{\partial F(x_i)}=\cfrac{\partial L(y_i, F(x_i))}{\partial F(x_i)} \end{cases} ∂F(xi)∂J=F(xi)−yi ←⎩ ⎨ ⎧L(yi,F(xi))=α(y−F(x))α(以其为例,可选其它)∂F(xi)∂J=∂F(xi)∂i∑L(yi,F(xi))=∂F(xi)∂L(yi,F(xi))
- 下降: F ( x i ) := F ( x i ) + h ( x i ) → h ( x i ) = y i − F ( x i ) = ∂ J ∂ F ( x i ) F ( x i ) − ∂ J ∂ F ( x i ) F(x_i)\text{:=}F(x_i)\text{+}h(x_i)\xrightarrow{\displaystyle{}h(x_i)=y_i-F(x_i)=\frac{\partial J}{\partial F(x_i)}}F(x_i)-\cfrac{\partial J}{\partial F(x_i)} F(xi):=F(xi)+h(xi)h(xi)=yi−F(xi)=∂F(xi)∂JF(xi)−∂F(xi)∂J
- 梯度提升树 (GBDT) \text{(GBDT)} (GBDT):
- 原理概述:由多个决策树串联的集成学习,可描述为 F ( x ) = F 0 ( x ) + ∑ m = 1 M γ m h m ( x ) \displaystyle{} F(x) \text{=} F_0(x) + \sum_{m=1}^M \gamma_m h_m(x) F(x)=F0(x)+m=1∑Mγmhm(x)
参数 含义 F ( x ) F(x) F(x) 用于预测 y y y的预测模型 F 0 ( x ) F_0(x) F0(x) 初始模型,一般初始化为 1 n ∑ i = 1 n y i \cfrac{1}{n}\displaystyle{}\sum_{i=1}^n{}y_i n1i=1∑nyi h m ( x ) h_m(x) hm(x) 第 m m m个弱学习器(一般为决策树) γ m \gamma_m γm 第 m m m个决策树的步长稀疏/学习率,控制每棵树对总模型的贡献 - 核心步骤:
大步 小步 操作 初始化 N/A \text{N/A} N/A 设定 F 0 ( x ) F_0(x) F0(x)为所有目标值的平均,例如 F 0 ( x ) = 1 n ∑ i = 1 n y i F_0(x)\text{=}\cfrac{1}{n}\displaystyle{}\sum_{i=1}^n{}y_i F0(x)=n1i=1∑nyi 迭代树 计算残差 用 r x i , m = − ∂ L ( y i , F m − 1 ( x i ) ) ∂ F m − 1 ( x i ) \displaystyle{}r_{x_i,m} \text{=} \cfrac{-\partial L(y_i, F_{m-1}(x_i))}{\partial F_{m-1}(x_i)} rxi,m=∂Fm−1(xi)−∂L(yi,Fm−1(xi))当作当前 F m − 1 ( x i ) F_{m-1}(x_i) Fm−1(xi)与 y i y_i yi残差 迭代树 拟合残差 让 h m ( x i ) h_m(x_i) hm(xi)尽可能接近 r x i , m → r_{x_i,m}\text{→} rxi,m→让当前 h m ( x i ) h_m(x_i) hm(xi)学习上一步误差 迭代树 更新模型 F m ( x ) = F m − 1 ( x ) + γ m h m ( x ) F_m(x) \text{=} F_{m-1}(x) \text{+} \gamma_m h_m(x) Fm(x)=Fm−1(x)+γmhm(x) 终止 N/A \text{N/A} N/A 达到最大迭代次数 M / M/ M/总体损失函数小于某值 → \text{→} →停止迭代
3. \textbf{3. } 3. 贝叶斯分类器
1️⃣ Bayes \text{Bayes} Bayes定律
- 推导:
- P ( B i ∣ A ) = P ( B i ) P ( A ∣ B i ) P ( A ) ⇐ { P ( A ∣ B i ) = P ( A B i ) P ( B i ) P ( B i ∣ A ) = P ( A B i ) P ( A ) P\left(B_i| A\right)\text{=}\cfrac{P\left(B_i\right) P\left(A|B_i\right)}{P(A)}\Leftarrow\begin{cases}P(A|B_i)\text{=}\cfrac{P(AB_i)}{P(B_i)}\\\\P(B_i|A)\text{=}\cfrac{P(AB_i)}{P(A)}\end{cases} P(Bi∣A)=P(A)P(Bi)P(A∣Bi)⇐⎩ ⎨ ⎧P(A∣Bi)=P(Bi)P(ABi)P(Bi∣A)=P(A)P(ABi)
- P ( B i ∣ A ) = P ( B i ) P ( A ∣ B i ) ∑ j P ( A ∣ B j ) P ( B j ) ⇐ P ( A ) = ∑ j P ( A B j ) = ∑ j P ( A ∣ B j ) P ( B j ) P(B_i|A)\text{=}\cfrac{P(B_i)P(A|B_i)}{\displaystyle\sum_{j}P(A|B_j)P(B_j)}\Leftarrow{}{P(A)}\text{=}\displaystyle\sum_{j}P(AB_j)\text{=}\sum_{j}P(A|B_j)P(B_j) P(Bi∣A)=j∑P(A∣Bj)P(Bj)P(Bi)P(A∣Bi)⇐P(A)=j∑P(ABj)=j∑P(A∣Bj)P(Bj)
- 解释:
参数 含义 示例 P ( B i ) P(B_i) P(Bi) 先验概率,指对事件 B i B_i Bi发生的主观臆测 某种疾病在人群中的发病率 P ( B i ∣ A ) P(B_i\mid{}A) P(Bi∣A) 后验概率,指观察到 A A A发生后 B i B_i Bi发生概率 对个体实施检测后个体患病概率 2️⃣ Bayes \text{Bayes} Bayes定律与分词(断句):令 X X X为待分词句子, Y = { W 1 , W 2 , . . . , W n } Y\text{=}\{W_1,W_2,...,W_n\} Y={W1,W2,...,Wn}为一种可能的分词结果
- Bayes \text{Bayes} Bayes分解: P ( Y ∣ X ) ∝ P ( Y ) × P ( X ∣ Y ) → 认为 P ( X ∣ Y ) = 1 基于该句子某种断句→必定生成该句子 P ( Y ∣ X ) ∝ P ( Y ) P(Y | X) \text{∝} P(Y)\text{×}P(X|Y)\xrightarrow[认为P(X|Y)\text{=}1]{基于该句子某种断句\text{→}必定生成该句子}P(Y | X) \text{∝} P(Y) P(Y∣X)∝P(Y)×P(X∣Y)基于该句子某种断句→必定生成该句子认为P(X∣Y)=1P(Y∣X)∝P(Y)
- 联合概率展开:
- P ( Y ) = P ( W 1 ) P(Y)\text{=}P(W_1) P(Y)=P(W1)
W1 →- P ( Y ) = P ( W 1 ) × P ( W 2 ∣ W 1 ) P(Y)\text{=}P(W_1)\text{×}P(W_2|W1) P(Y)=P(W1)×P(W2∣W1)
W1 W2 →- P ( Y ) = P ( W 1 ) × P ( W 2 ∣ W 1 ) × P ( W 3 ∣ W 2 , W 1 ) P(Y)\text{=}P(W_1)\text{×}P(W_2|W1)\text{×}P(W_3|W2,W_1) P(Y)=P(W1)×P(W2∣W1)×P(W3∣W2,W1)
W1 W2 W3 →- P ( Y ) = P ( W 1 ) × P ( W 2 ∣ W 1 ) × P ( W 3 ∣ W 2 , W 1 ) × ⋯ × P ( W n ∣ W 1 , W 2 , … , W n − 1 ) P(Y)\text{=}P(W_1)\text{×}P(W_2|W1)\text{×}P(W_3|W2,W_1)\text{×}\cdots\text{×}P\left(W_n| W_1, W_2, \ldots, W_{n-1}\right) P(Y)=P(W1)×P(W2∣W1)×P(W3∣W2,W1)×⋯×P(Wn∣W1,W2,…,Wn−1)
W1 W2 W3 ... Wn.- k k k阶马可夫假设:
- 含义:认为某个单词只由其前 k k k个单词确定,以解决稀疏性问题
- 简化: P ( Y ) = P ( W 1 ) × P ( W 2 ∣ W 1 ) × P ( W 3 ∣ W 2 ) × ⋯ × P ( W n ∣ W n − 1 ) P(Y)\text{=}P(W_1)\text{×}P(W_2|W_1)\text{×}P(W_3|W_2)\text{×}\cdots\text{×}P\left(W_n|W_{n-1}\right) P(Y)=P(W1)×P(W2∣W1)×P(W3∣W2)×⋯×P(Wn∣Wn−1)
3️⃣朴素贝叶斯分类器
- 模型描述:
- 假设:决定各分类的属性之间是相互独立(简单粗暴/但也损失了分类精度)
- 前提:样本 X ( a 1 , a 2 , . . . , a n ) X(a_1,a_2,...,a_n) X(a1,a2,...,an)有 n n n个属性 { A 1 , A 2 , . . . , A n } \{A_1,A_2,...,A_n\} {A1,A2,...,An}且有 m m m个类 { C 1 , C 2 , . . . , C m } \{C_1,C_2,...,C_m\} {C1,C2,...,Cm}
- 分类:将 X ( a 1 , a 2 , . . . , a n ) X(a_1,a_2,...,a_n) X(a1,a2,...,an)归类为 C i ⇔ 等价 P ( C i ∣ X ) > P ( C j ∣ X ) C_i\xLeftrightarrow{等价}P\left(C_i | X\right)\text{>}P\left(C_j|X\right) Ci等价 P(Ci∣X)>P(Cj∣X),其中 C j C_j Cj为除 C i C_i Ci任一类
- 模型分析:
- P ( C i ∣ X ) = P ( X ∣ C i ) P ( C i ) P ( X ) ⇒ P ( X ) 为常数 P\left(C_i|X\right)\text{=}\cfrac{P\left(X|C_i\right) P\left(C_i\right)}{P(X)}\xRightarrow{P(X)为常数} P(Ci∣X)=P(X)P(X∣Ci)P(Ci)P(X)为常数最大化 P ( X ∣ C i ) P ( C i ) P\left(X|C_i\right) P\left(C_i\right) P(X∣Ci)P(Ci)以分类
- P ( X ∣ C i ) P ( C i ) = P ( A 1 = a 1 , A 2 = a 2 , ⋯ , A n = a n ∣ C i ) P ( C i ) ⇒ 各属性独立 ∏ k = 1 n P ( a k ∣ C i ) P ( C i ) P(X|C_i)P(C_i)\text{=}P(A_1\text{=}a_1,A_2\text{=}a_2,\cdots,A_n\text{=}a_n|C_i)P(C_i)\xRightarrow{各属性独立}\displaystyle{}\prod_{k=1}^nP(a_k|C_i)P(C_i) P(X∣Ci)P(Ci)=P(A1=a1,A2=a2,⋯,An=an∣Ci)P(Ci)各属性独立k=1∏nP(ak∣Ci)P(Ci)
- 模型流程:
阶段 操作 准备 确定样本的属性,获取相应的样本 训练 对每个类别计算 P ( C i ) → P(C_i)\text{→} P(Ci)→对每个属性计算$P(a_k 应用 对新样本 Λ \Lambda Λ计算其对每个类别的$P(\Lambda{} - Underflow \text{Underflow} Underflow问题:
- 问题:多概率相乘 ∏ k = 1 n P ( a k ∣ C i ) P ( C i ) \displaystyle{}\prod_{k=1}^nP(a_k|C_i)P(C_i) k=1∏nP(ak∣Ci)P(Ci)很可能会快速变为 0 0 0
- 解决:取对数 → log ( ∏ k = 1 n P ( a k ∣ C i ) P ( C i ) ) \text{→}\log{\left(\displaystyle{}\prod_{k=1}^nP(a_k|C_i)P(C_i)\right)} →log(k=1∏nP(ak∣Ci)P(Ci))
4️⃣示例:判断学历为大学,年薪 30-40 \text{30-40} 30-40,薪水 20000-30000 \text{20000-30000} 20000-30000的员工的性别
样本 性别 工作内容 学历 年龄 薪水 1 女 送货 大学 20 − 30 20000 − 30000 2 男 包装 大学 > 40 > 40000 3 男 烘烤 大学 30 − 40 20000 − 30000 4 男 包装 高中 30 − 40 20000 − 30000 5 男 送华 大学 > 40 30000 − 40000 6 女 烘烤 高中 20 − 30 20000 − 30000 7 男 烘烤 大学 20 − 30 < 20000 8 女 包装 大学 30 − 40 20000 − 30000 9 男 烘烤 大学 > 40 20000 − 30000 10 男 包装 大学 20 − 30 < 20000 \begin{array}{|cccccc|} \hline \text { 样本 } & \text { 性别 } & \text { 工作内容 } & \text { 学历 } & \text { 年龄 } & \text { 薪水 } \\ \hline 1 & \text { 女 } & \text { 送货 } & \text { 大学 } & 20-30 & 20000-30000 \\ \hline 2 & \text { 男 } & \text { 包装 } & \text { 大学 } & >40 & >40000 \\ \hline 3 & \text { 男 } & \text { 烘烤 } & \text { 大学 } & 30-40 & 20000-30000 \\ \hline 4 & \text { 男 } & \text { 包装 } & \text { 高中 } & 30-40 & 20000-30000 \\ \hline 5 & \text { 男 } & \text { 送华 } & \text { 大学 } & >40 & 30000-40000 \\ \hline 6 & \text { 女 } & \text { 烘烤 } & \text { 高中 } & 20-30 & 20000-30000 \\ \hline 7 & \text { 男 } & \text { 烘烤 } & \text { 大学 } & 20-30 & <20000 \\ \hline 8 & \text { 女 } & \text { 包装 } & \text { 大学 } & 30-40 & 20000-30000 \\ \hline 9 & \text { 男 } & \text { 烘烤 } & \text { 大学 } & >40 & 20000-30000 \\ \hline 10 & \text { 男 } & \text { 包装 } & \text { 大学 } & 20-30 & <20000 \\ \hline \end{array} 样本 12345678910 性别 女 男 男 男 男 女 男 女 男 男 工作内容 送货 包装 烘烤 包装 送华 烘烤 烘烤 包装 烘烤 包装 学历 大学 大学 大学 高中 大学 高中 大学 大学 大学 大学 年龄 20−30>4030−4030−40>4020−3020−3030−40>4020−30 薪水 20000−30000>4000020000−3000020000−3000030000−4000020000−30000<2000020000−3000020000−30000<20000
- { P ( 包装 ∣ 女 ) × P ( 大学 ∣ 女 ) × P ( 30 - 40 ∣ 女 ) × P ( 20000 - 30000 ∣ 女 ) × P ( 女 ) = 0.0222 P ( 包装 ∣ 男 ) × P ( 大学 ∣ 男 ) × P ( 30 - 40 ∣ 男 ) × P ( 20000 - 30000 ∣ 男 ) × P ( 男 ) = 0.0315 \begin{cases}P(包装|女)\text{×}P(大学|女)\text{×}P(30\text{-}40|女)\text{×} P(20000\text{-}30000|女)\text{×}P(女)\text{=}0.0222\\\\P(包装|男)\text{×}P(大学|男)\text{×}P(30\text{-}40|男)\text{×} P(20000\text{-}30000|男)\text{×}P(男)\text{=}0.0315\end{cases} ⎩ ⎨ ⎧P(包装∣女)×P(大学∣女)×P(30-40∣女)×P(20000-30000∣女)×P(女)=0.0222P(包装∣男)×P(大学∣男)×P(30-40∣男)×P(20000-30000∣男)×P(男)=0.0315
- 故根据给定条件,应归类为男性
4. KNN \textbf{4. KNN} 4. KNN算法
1️⃣算法概念与思想
- 基本思想:若与 x x x最邻近的 k k k个样本 { x 1 , x 2 , . . . , x n } \{x_1,x_2,...,x_n\} {x1,x2,...,xn}大都属于 A A A类别 → x i \text{→}x_i →xi也属于 A A A类别
- 算法流程:选定 k k k值,计算输入 x x x与样本所有点的距离 dist ( x , x i ) \text{dist}(x,x_i) dist(x,xi)
- 分类任务:对 k k k个最邻近进行投票(如 x i x_i xi属于 v v v就为 v v v类投 1 1 1票),选出数量最多的类作为 x x x的类
- 回归任务:对 k k k个最邻近取平均,作为 x x x的相应值
- 算法特点:为 Lazy-Learning \text{Lazy-Learning} Lazy-Learning方法,即无需训练模型,待分类数据到达时马上开始分类
2️⃣算法有关的问题
- 关于 k k k及其选择:
- 影响: k k k太小容易对噪声敏感(过拟合),太大可能会包含太多其它类别的点
- 选择: k k k一定是奇数(避免平局),另外可通过测试确定 k k k(选择 k =1,3,5... k\text{=1,3,5...} k=1,3,5...时使错误率最小的 k k k)
- Majority Voting \text{Majority Voting} Majority Voting问题
- 含义:某一类别占比太大,以至分类时总会选择到它
- 解决:加权投票,如 x i x_i xi属于𝑣就为为 v v v类投 1 dist ( x , x i ) 2 \cfrac{1}{\text{dist}(x,x_i)^2} dist(x,xi)21票 → \text{→} →使靠 x x x更近的结点话语权更大


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









