










一、数据库内置函数
①字符串函数:
concat(s1,s2...)
Lower(str)
Upper(str)
Lpad(str,n,pad) (左填充到长度为n的字符串长度)
Rpad(str,n,pad)(右填充到长度为n的字符串长度)
Trim(str) (去除字符串首尾的空格)
Substring(str,start,len)(字符串从start位置开始起的len个长度的字符串)
使用语法:select 函数及其参数
Eg:select concat(s1,s2.....);
统一员工的编号均为5位,不足的前面补零,
代码:update emp set workno=lpad(workno,5,0);
② 数值函数:
ceil(x)向上取整
Floor(x)向下取整
Mod(x,y)返回x/y的模
Rand() 返回0~1内的随机数
Round(x,y) 求参数x的四舍五入的值,保留y位小数
语法:select ceil(1.5) 2
生成六位数的随机验证码
Select lpad(round(rand()*1000000,0),6,’0’);
③日期函数:
Curdate()返回当前日期
Curtime()返回当前时间
Now()返回当前日期和时间
Year(date)获取指定date的年份
Month(date)获取指定date月份
Day(date) 获取指定date的日期
Date_add(date,interval expr type)返回date加上一个时间间隔expr后的时间值
DateDiff(date1,date2)返回起始时间和结束时间之间的天数
语法:select curdate();
Select year(now())/date(now())/month(now());
Date_add(now(),interval 70 month/day/year);
查询所有员工的入职天数,并按入职天数倒序排序:
Select name,datadiff(curdate(),entrydtae) as ‘entrydates’from emp order by entrydates;
④流程函数:
If(value,t,f)返回value为true则返回t,否则则返回f;
Ifnull(value1,value2)返回如果value1不为空,则返回value1,否则返回value2;
Case when[val1] then[res1]........else [default]end 返回如果val1为true 则返回res1,否则就返回default默认值
Case [expr] when [val1] then [res1].....else[default]end 返回如果expr等于val1,则返回res1,否则就返回default默认值。
语法:select if(true “ok”,”hh”);
查询员工表中的员工姓名和工作地址(北京/上海)
Select name,
Case Workaddress when ‘北京’ then ‘一线城市’ when “上海’ then”二线城市’ else “二线城市’end;
from emp;
展示班级成绩,>=85优秀 >=60 及格 否则不及格
Select name,
(Case Score when score>=85 then “优秀” when score >=60 then”及格” else “不及格”end)’分数’
from student;
二、数据约束
数据约束:保证表中数据的完整性。
Not null
Unique
Primary key(要求非空且唯一,必须要有)
Default(默认约束)
Check(8.0.16才能支持check)
Foreign key(肯定涉及两张表)
Eg:id (唯一标识) 故肯定为primary key ,要求其自动增长 故再加一个auto_increment
Name 要求其不为空,故not null, 且要求唯一,故为unique
Age 要求有一定值域范围,故其肯定要用check对输入的年龄进行检查,故check;
Status 要求默认为1;
Create table user(
Id int primary key auto_increment,
Name varchar(10) not null unique,
Age int check(age>0 &&age<=120),
Status char(1) default’1’,
Gender char(1)
)comment “用户表”;
Insert into user (name,age,status,gender) values(“tom1”,19,’1’,’男’),(“tom2”,25,’0’,”男”);
其中没有特别对id进行值,由于有auto_increment 所以可以自动增加
不能insert 同一个数据因为name 是unique 所以不能。
外键约束:让两张表的数据之间建立连接,从而保证数据的一致性和完整性
语法:表中直接添加
Alter table user add constraint 外键名称 foreign key 外键字段名 references主表(字段名);
Alter table user add constraint depot_id_emp foreign key depot_id references depot(id);
删除外键:Alter table emp drop foreign key fk_emp_dept_id;
No action 与restrict 是一致的,系统默认的操作,本质上就是不允许父表的删除更新操作影响到子表。
Cascade 就是允许父表更新和修改后,子表也同样进行修改,
Set null 将父表修改和更新后,并将外键约束受影响的子表设置为null,其可以设置为空值
Set default 将父表修改和更新后,并将受外键约束的子表设置为默认值。
语法就是在增加约束的语法上增加 on update cascade on delete cascade
完整的语法:alter table user add constraint 外键约束名 references 外键约束表(约束名)on update/set nul/set defaultcascade on delete/set null/set default cascade;

三、多表查询
多表关系:三种关系(一对多,多对多,一对一)
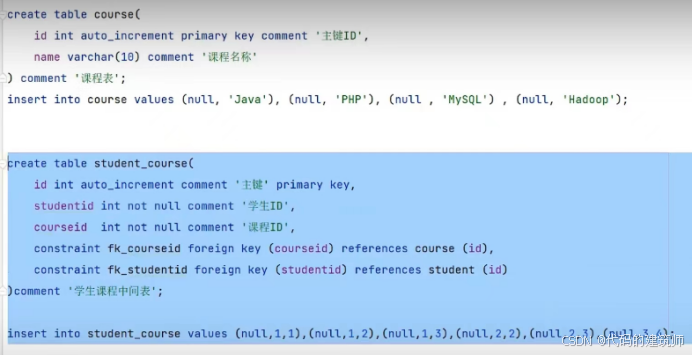
员工和部门的关系、学生和课程的关系,多对多关系需要建立中间表,中间表至少包含两个外键,分别关联两个主键。
中间表如何建立:首先需要create一个表,表中内容包括主键和两个外键约束,其中主键可以自己定义,可以是序号,而两个外键必须用constraint fk_studentid foreign key(约束名) references表(外键约束名)
一对一关系:多用于单表的拆分,来提高操作效率。(一表拆成两表或者多表,多表之间的一对一关系需要维护,只需在任意一方主键增加一个外键即可,最后记得将其进行unique 进行约束)
多表查询(笛卡尔积):前提是有外键约束的情况下,才能用笛卡尔积。记得消除无效的笛卡尔积,消除用就用外键条件约束即可消除,
语法:
Select * from 表1,表2 where 表1.外键=表2.外键;//外键为空的查询不出来,会自动减去,
连接查询:
内连接:相当于查询A,B交集部分的数据,
外连接:
左外连接:查询左表所有数据,以及两张表交集部分数据,
右连接:查询右表所有数据,以及两张表交集部分数据,
自连接:当前表与自身的连接,自连接必须使用表别名,起别名select * from 表1 e,表2 c;
起别名了,就不能使用表名了
内连接:
隐式内连接:
Select 字段列表 from 表1,表2 where 连接条件;
显式内连接
Select 字段列表 from 表1 inner join 表2 on 连接条件;
四、额外操作
修改基本表:
Alter table student alter column age int;将原来age的数据类型变成int;
Alter table course add unique(Cname); 对course 中的Cname增加约束条件unique;
建立索引:
Create unique index SCno on SC(Sno asc,Cno desc);
Alter index SCno rename to SCSno;
Drop index SCno;
数据查询:
Group by 会将分组属性一样的放在同一个组,并使用聚合函数。
比如 select gender count(*) from student group by gender;
结果将是:男多少人,女多少人,而不是总共多少人。
Select 后面可以加字符列表属性,也可以加算术表达式、字符串常量、函数(lower()、upper())、还可以加上前一字段的别名。
Select distinct Sno from SC;消除查询结果中的重复项
五、连接查询
连接查询(多表查询:等值连接、自然连接、非等着连接、自身连接、外连接、复合条件连接):
等值(where中含有=)与非等值连接(不含=):其谓词连接要具有可比性,
比如要查询每个学生的选修课情况
Select student.*,sc.* from student,sc where student.sno=sc.sno;
对于以上语法产生的目的表是有重复的属性(student.sno和sc.sno都分别在目的表中各占一列属性)
所以为了更好的压缩表,去掉重复的属性:所以采用自然连接
Select student.sno,sname,ssex,sage,sdept,cno,grade from student,sc where student.sno=sc.sno;
自然连接(在等值连接中将目标列中重复的属性列表删除则为自然连接)
复合条件连接(在where子句后面除了连接谓词还加上了条件选择)
Select student.sno,sname from student,sc where student.sno=sc.sno and sc.cno=”2” and sc.grade>90;
自身连接(要进行自身连接必须为表取两个别名,适用场景:有对自身与自身有关的目标表需求时):
Select a.cno,b.cpno from course a,course b where a.cpno=b.cno;
外连接(当两张表中有null的数据时,需要将其在目的表中展现为null的属性值就可以用外连接):
有的学生可能没有选课,也要在最终结果中展示出来
Select student.sno,sname,ssex,sage,sdept,cno,grade form student left outer join sc on(student.sno=sc.sno);
多表连接(两个以上的表进行连接):
Select student.sno,sname,cname,grade from student,sc,course where student.sno=sc.sno and sc.cno=course.cno;
嵌套查询(select进行嵌套,结构:select(select()),里面的select不允许使用order by 其order by 只能对嵌套查询的最终结果进行排序),由于内部的子查询得到的结果是一个集合,所以在父查询中的where 中常用in进行关系限定。
联合查询(字段列表必须一致,且字段顺序必须可比):
Select (distinct )字段列表 from 表A union (all不加all表示去重,加all 会有重复) select (distinct)字段列表 from 表B;
标量子查询返回的结果为一个值,所以常用=、>、<、<>、!=;
列子查询:返回的值是一个集合:常用in、not in 、any、 some、 all
any、 some、 all常与>、<连用, > any >all >some;
行子查询(where可以用匹配的方式(属性1,属性2)=子查询的一行多列的结果)
聚合函数查询比直接用all、some、any效率要高,
<any等价于<max >any等价于>min
<all 等价于<min >all 等价于>max
=any 等价于in !=all等价于not in
带exists(exists 对应全称量词存在和not exists对应全称量词任意)的子查询,其返回的是true 和false,常用select *进行使用。
集合查询(要求其属性列必须一致,且其中的数据类型具有可比性):union、intersect、except。
派生表查询(在from后加入派生表语句,且必须为派生表起一个别名(属性列别名))
更新数据(对元组进行操作):
insert into 表(属性列) values(值)Insert into表 子查询表(就正常select操作)
Update 表 set 属性操作表达式 where 条件筛选。
Delete from 表 (where 条件筛选)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









