










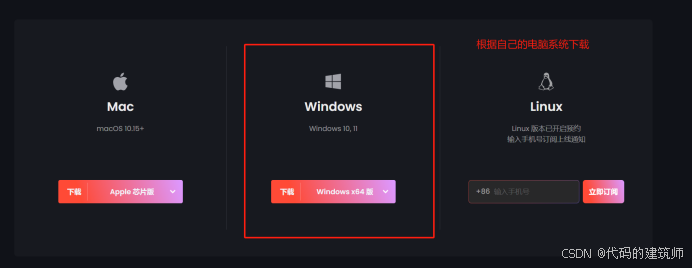
首先,进入官网下载对应的版本,以windows为例,见如下操作:

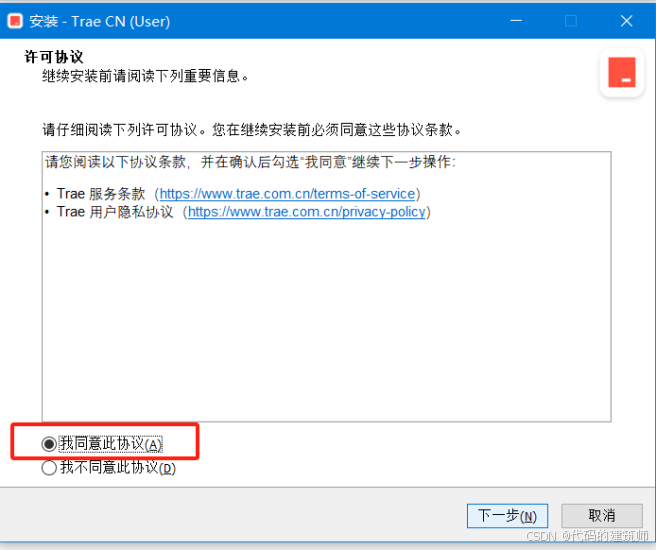
将下载后的文件一直点击下一步就行

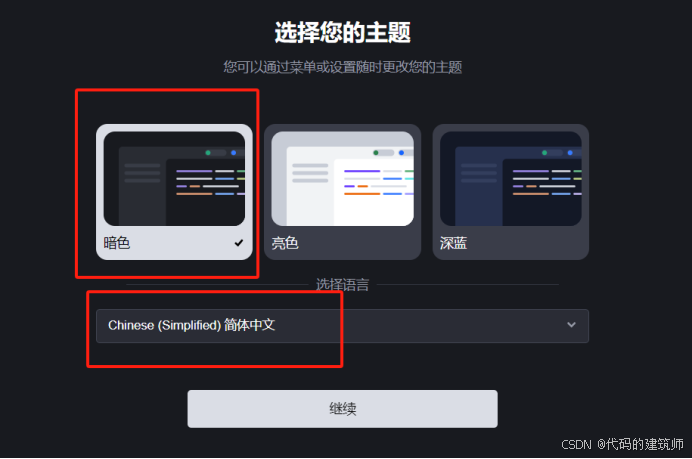
点击开始,对Trae进行初始配置:主题和语言,点击继续
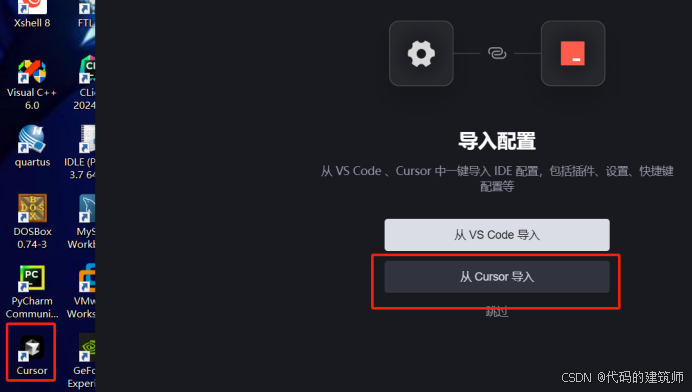
我电脑安装的是Cursor,所以选择从Cursor导入,这个个过程需要等待一会
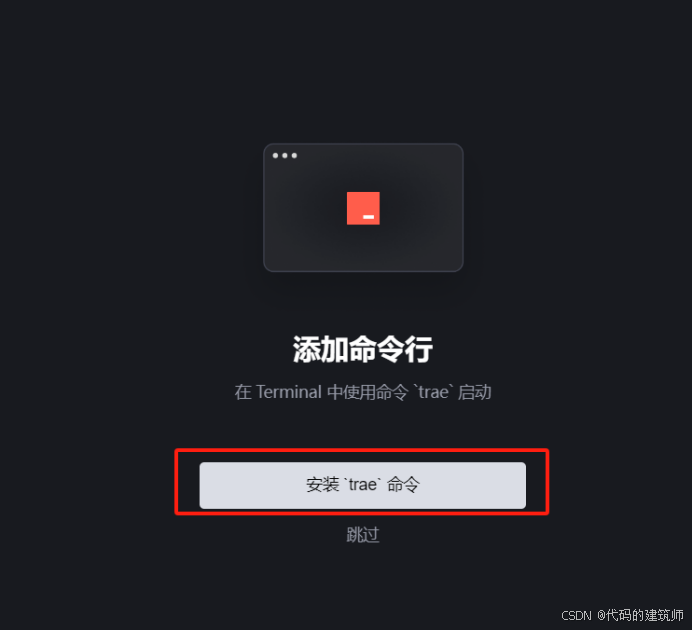
一会过后就可以在终端添加命令行:这一步是为了让我们在终端能够使用trae命令快速唤起Trae,使用trae my-react-app命令在Trae中打开文件
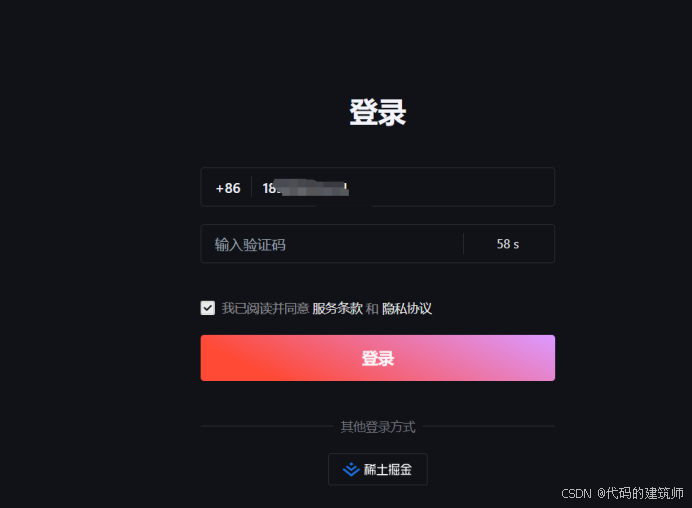
然后就到了登录账号这一步,这里我选择手机号登录

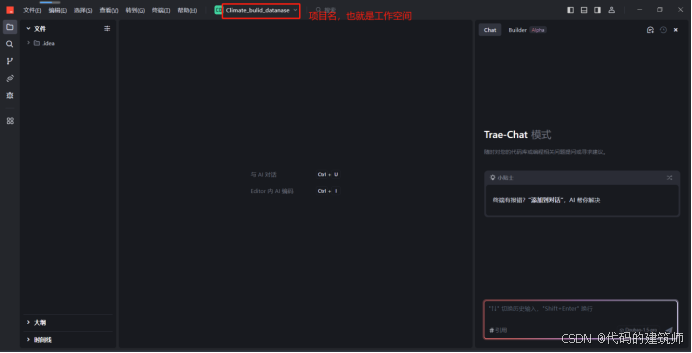
然后就可以正式的项目工作了!!然后点击打开文件夹,就可以进行快乐的编程了
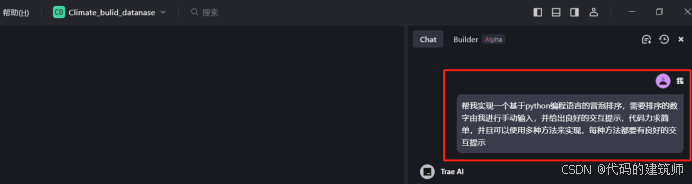
然后我提出我的编程需求:
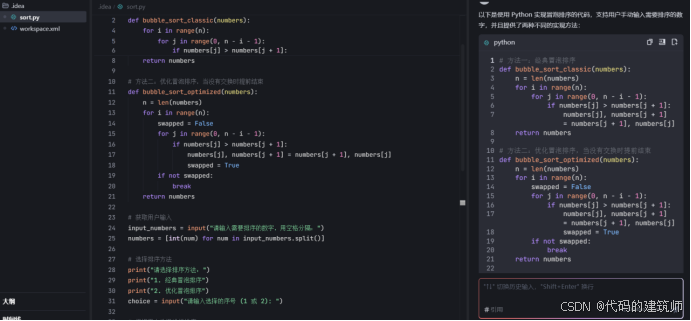
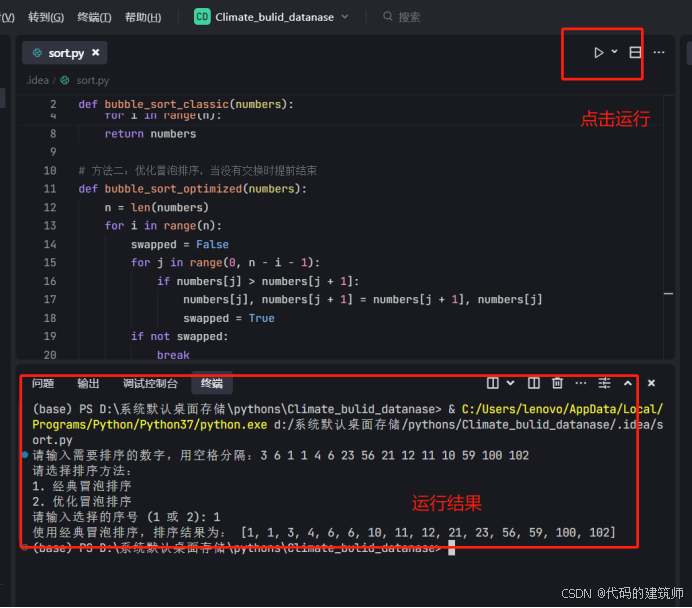
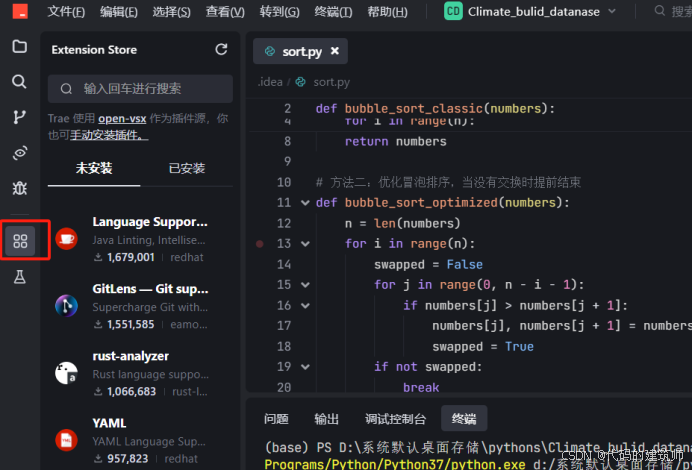
以及一些插件的选择:
并且也可以选择相应的AI大模型:
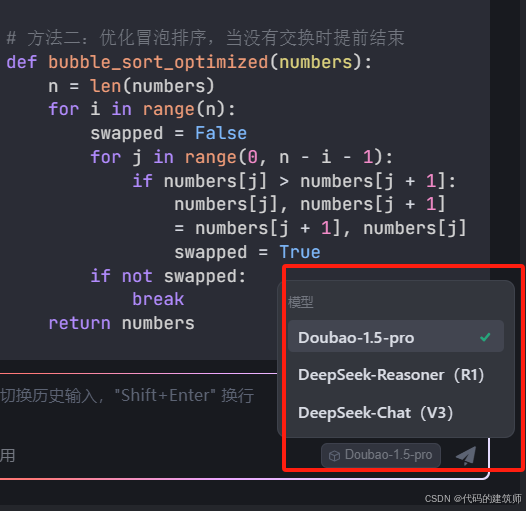
快去试一试吧!!!


















 1990
1990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









