






任务三 竞争分析
对比市场份额前三的拜耳、安速、科凌虫控,挖掘拜耳市场增长策略
1、产品分布情况
2、产品结构特征(BCG矩阵)及发展策略
3、流量结构及推广策略
4、舆情评论及情感分析(拜耳公司)
读数据
os.chdir('..')
os.chdir('./竞争数据')
使用商品销售数据分析各家的产品类别的分布
#准备数据
os.chdir('./商品销售数据')
filenames2 = glob.glob('*.xlsx')
df3 = pd.read_excel(filenames2[1])
df3.head()#定义函数
def load_xlsx1(filename):
df = pd.read_excel(filename)
useless = ['序号','店铺名称','主图链接',
'商品链接','商品名称']
df.drop(columns=useless,inplace=True)
return df
df3an = load_xlsx1(filenames2[0])#安速
df3an.head()
df3bai = load_xlsx1(filenames2[1])#拜尔
df3bai.head()
df3kl = load_xlsx1(filenames2[2])#科凌虫控
df3kl.head()类目
bai31 = df3bai.groupby('类目').sum()
an31 = df3an.groupby('类目').sum()
kl31 = df3kl.groupby('类目').sum()#作图
fig, axes = plt.subplots(1, 3, figsize=(10, 6))
ax = axes[0]
bai31['销售额'].plot.pie(autopct='%.f',title='拜耳',startangle=30,ax=ax)
ax.set_ylabel('')
ax = axes[1]
an31['30天销售额'].plot.pie(autopct='%.f',title='安速',startangle=60,ax=ax)
ax.set_ylabel('')
ax = axes[2]
kl31['30天销售额'].plot.pie(autopct='%.f',title='科凌虫控',startangle=90,ax=ax)
ax.set_ylabel('')
plt.show()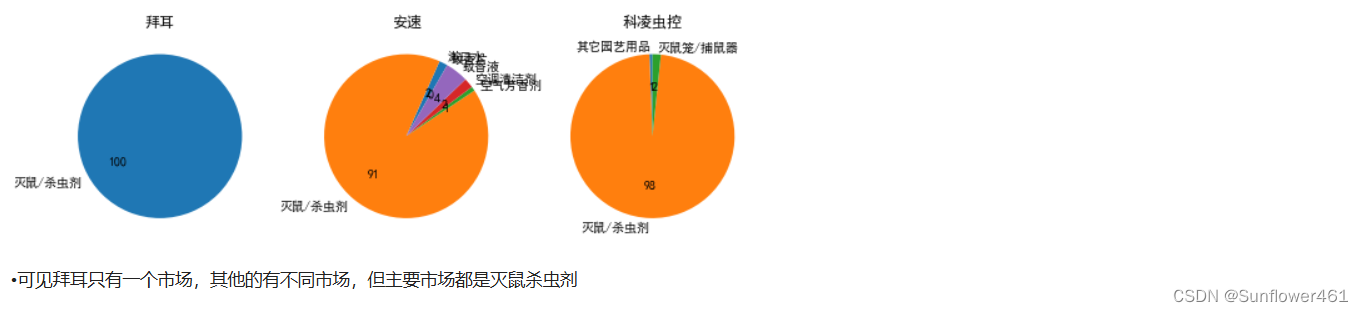
适用对象
bai32 = df3bai.groupby('使用对象').sum()
an32 = df3an.groupby('适用对象').sum()
kl32 = df3kl.groupby('适用对象').sum()#作图
fig, axes = plt.subplots(1, 3, figsize=(10, 6))
ax = axes[0]
bai32['销售额'].plot.pie(autopct='%.f',title='拜耳',startangle=30,ax=ax)
ax.set_ylabel('')
ax = axes[1]
an32['30天销售额'].plot.pie(autopct='%.f',title='安速',startangle=60,ax=ax)
ax.set_ylabel('')
ax = axes[2]
kl32['30天销售额'].plot.pie(autopct='%.f',title='科凌虫控',startangle=90,ax=ax)
ax.set_ylabel('')
plt.show()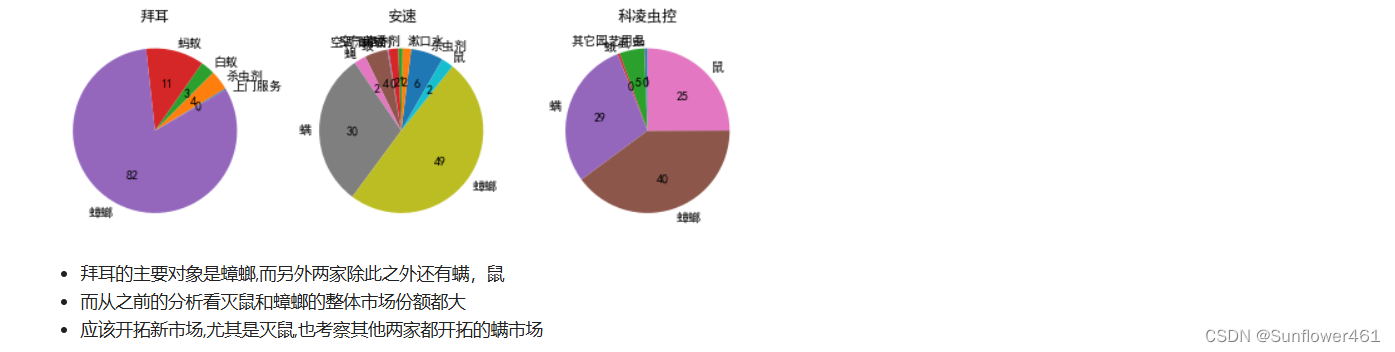
产品结构分析
读数据
os.chdir('..')
os.chdir('./商品交易数据')
filenames3 = glob.glob('*.xlsx')
filenames3df4bai = pd.read_excel(filenames3[1])
df4bai.head()#数据展示
df4bai.info()
df4bai['商品'].value_counts().count()
#五个月的数据,每个商品至多五个月都有,至少有一个月,故需要对商品分类汇总自定义分类函数
def byproduct(df):
dfb = df.groupby('商品').mean().loc[:,['交易增长幅度']]
dfb['交易金额'] = df.groupby('商品').sum()['交易金额']
dfb['交易金额占比'] = dfb['交易金额']/dfb['交易金额'].sum()
dfb['商品个数'] = df.groupby('商品').count()['交易金额']
dfb.reset_index(inplace=True)
return dfb拜尔
拜耳-BCG图
bai4 = byproduct(df4bai)
bai4.describe()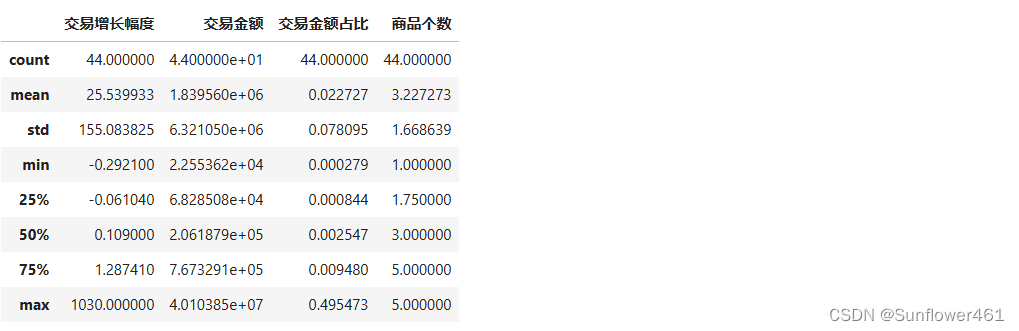
- 其中交易增长幅度可表示市场发展率,交易金额占比可表示市场份额
- 这两个指标的最大值都远大于3/4分位数,认为是异常值,考虑引入盖帽法,方便后续作图
#定义盖帽法函数
def block(x):
qu = x.quantile(.9)
out = x.mask(x>qu,qu)
return(out)
#分别定义对两个指标盖帽的函数
def block2(df):
df1 = df.copy()
df1['交易增长幅度'] = block(df1['交易增长幅度'])
df1['交易金额占比'] = block(df1['交易金额占比'])
return df1bai41 = block2(bai4)
bai41.describe()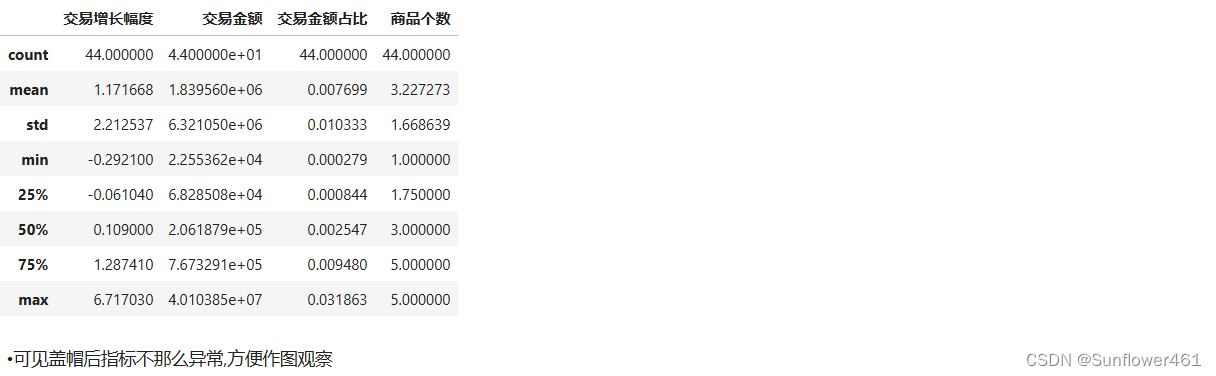
# 函数3:绘制波士顿矩阵图
def plotBCG(df,mean=False,q1=0.5,q2=0.5):
f,ax = plt.subplots(figsize=(10,8))
ax = sns.scatterplot('交易金额占比','交易增长幅度',
hue='商品个数',size='商品个数',sizes=(20,200),
palette='cool',legend='full',data=df)
for i in range(0,len(df)):
ax.text(df['交易金额占比'][i]+0.001,df['交易增长幅度'][i],i)
if mean: # 均值线
plt.axvline(df['交易金额占比'].mean())
plt.axhline(df['交易增长幅度'].mean())
else:
plt.axvline(df['交易金额占比'].quantile(q1))
plt.axhline(df['交易增长幅度'].quantile(q2))
plt.show()
plotBOG(bai41,mean=True) 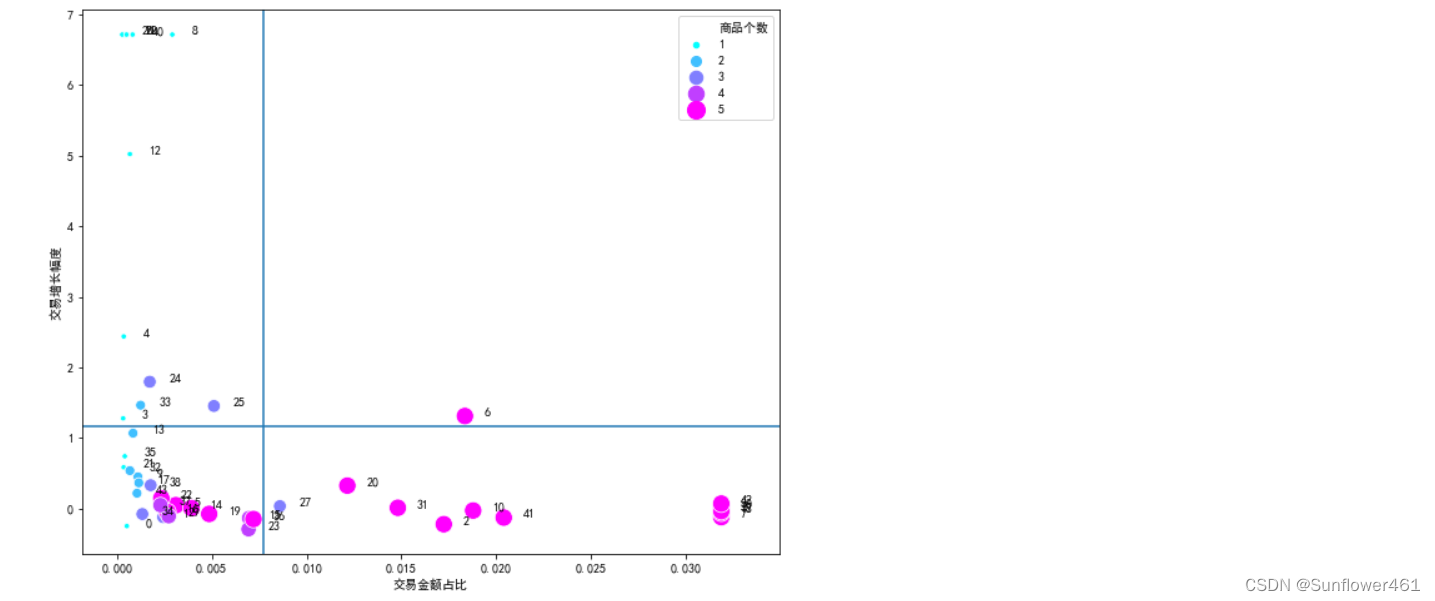
可以根据实际的业务选择区间的分隔线,由行业经验确定(例如认为增幅0.1在行业里算高,就可以作为分隔线);明星产品和奶牛产品的商品个数普遍比较多;没有突出的明星产品,但是有快进入明星产品的问题产品
拜耳-明星产品
# 函数4:根据BCG矩阵,抽取明星、奶牛、问题产品
def extractBCG(df,q1=0.5,q2=0.5,by='交易金额占比'):
'''
从原始数据中,抽取明星产品、奶牛产品、问题产品
'''
# 明星产品
star = df.loc[(df['交易金额占比']>=df['交易金额占比'].quantile(q1)
) & (df['交易增长幅度']>=df['交易增长幅度'].quantile(q2)),:]
star = star.sort_values(by,ascending=False)
# 奶牛产品:关心市场份额,依交易金额占比排序
cow = df.loc[(df['交易金额占比']>=df['交易金额占比'].quantile(q1)
) & (df['交易增长幅度']<df['交易增长幅度'].quantile(q2)),:]
cow = cow.sort_values(by,ascending=False)
# 问题产品:关心市场增长率,依交易增长幅度排序
que = df.loc[(df['交易金额占比']<df['交易金额占比'].quantile(q1)
) & (df['交易增长幅度']>=df['交易增长幅度'].quantile(q2)),:]
que = que.sort_values(by,ascending=False)
return star,cow,que
baistar,baicow,baique = extractBOG(bai4)
baistar1,baicow1,baique1 = extractBOG(bai4,by='交易增长幅度')baistar

拜耳奶牛产品/老爆款
baicow
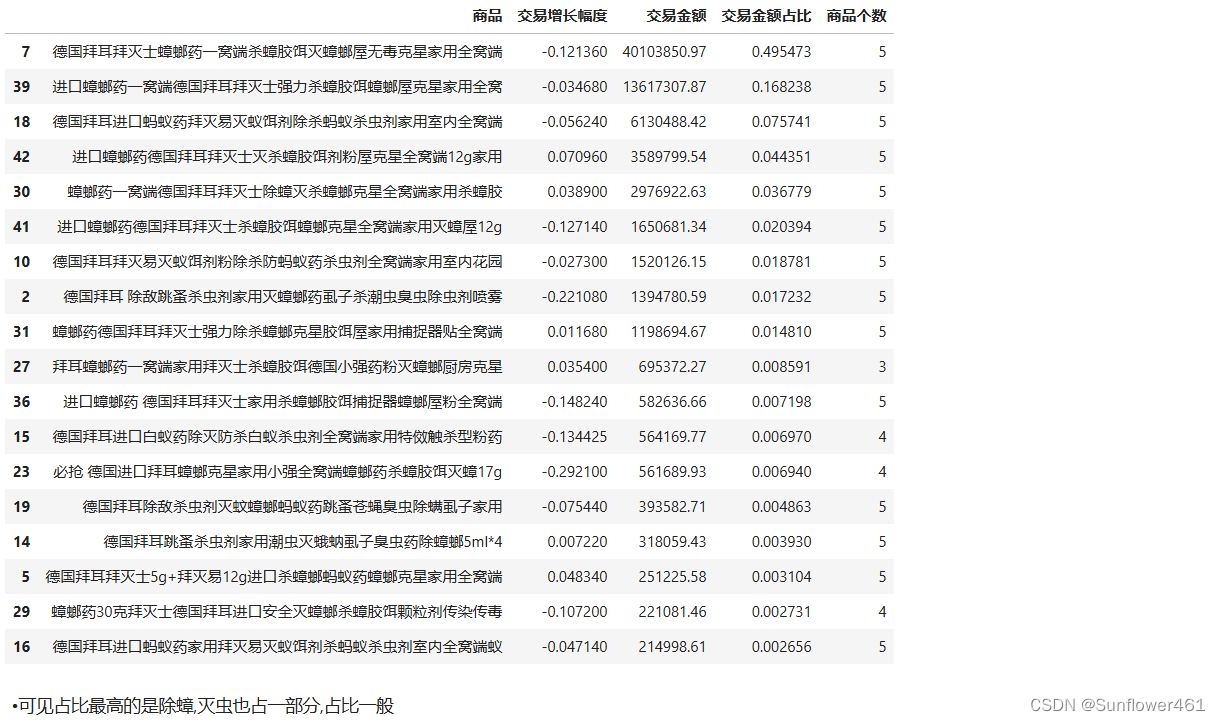
拜耳问题产品/潜力款
baique1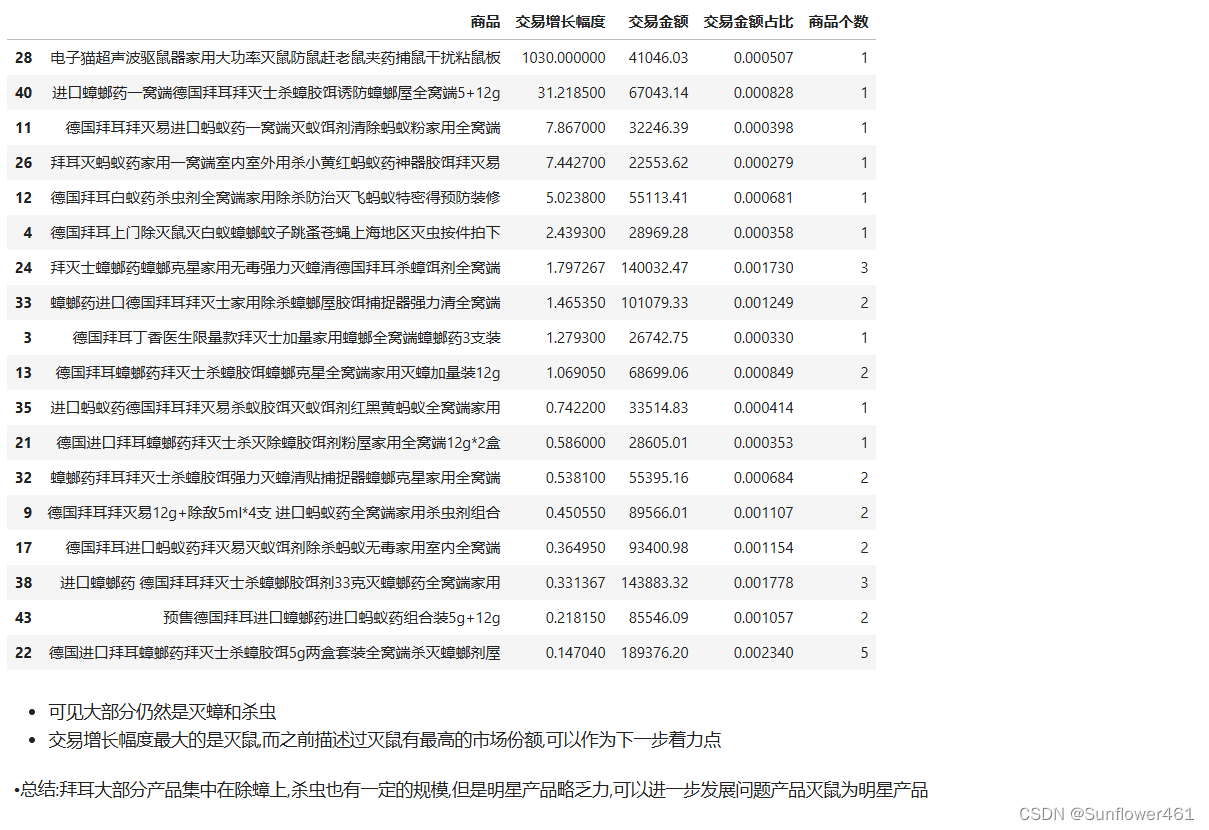
安速
df4an = pd.read_excel(filenames3[0])
df4an.head(2)#读数据df4an.info()
df4an['商品'].value_counts().count()汇总指标
an4 = byproduct(df4an)
an4.describe()#盖帽法处理
an41 = block2(an4)
an41.describe()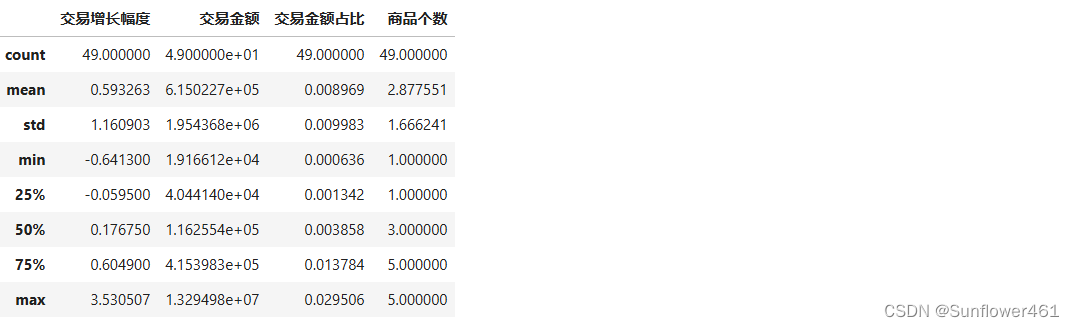
BCG图
plotBOG(an41)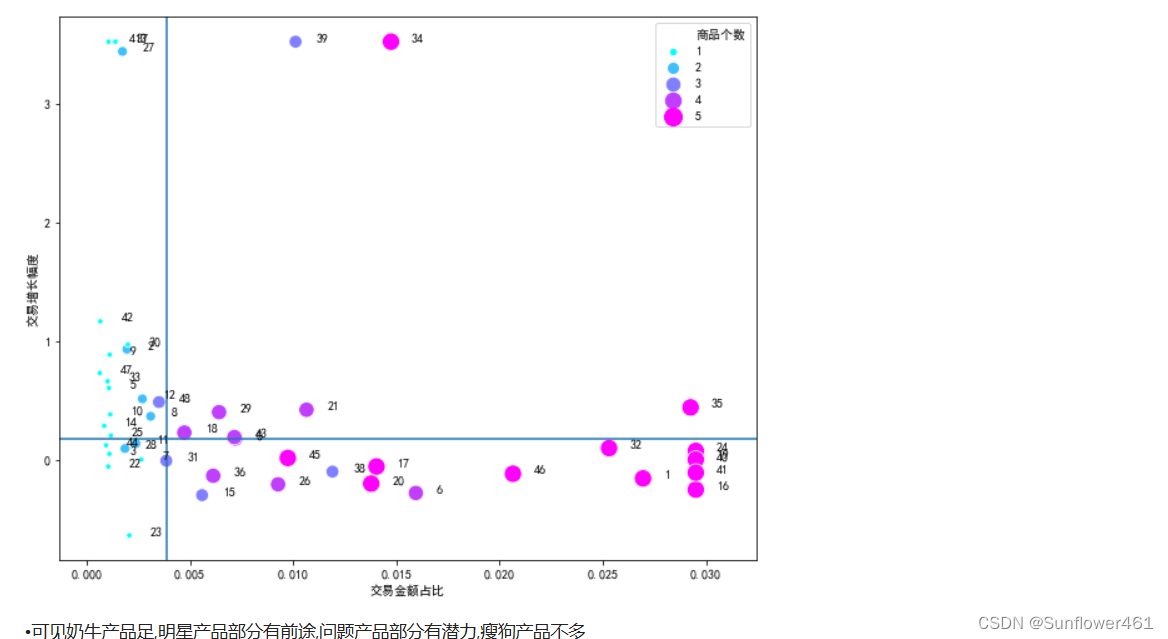
查看具体产品
anstar,ancow,anque = extractBOG(an4)
anstar1,ancow1,anque1 = extractBOG(an4,by='交易增长幅度')安速明星
anstar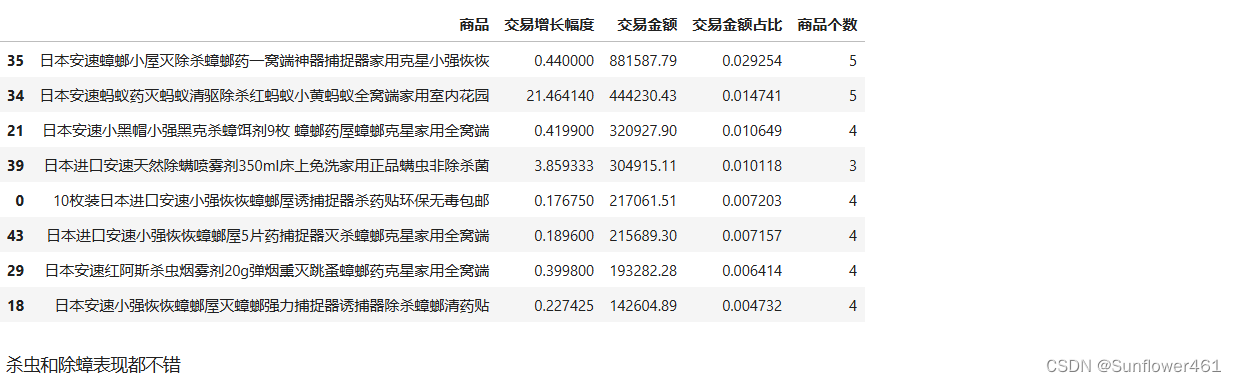
安速奶牛
ancow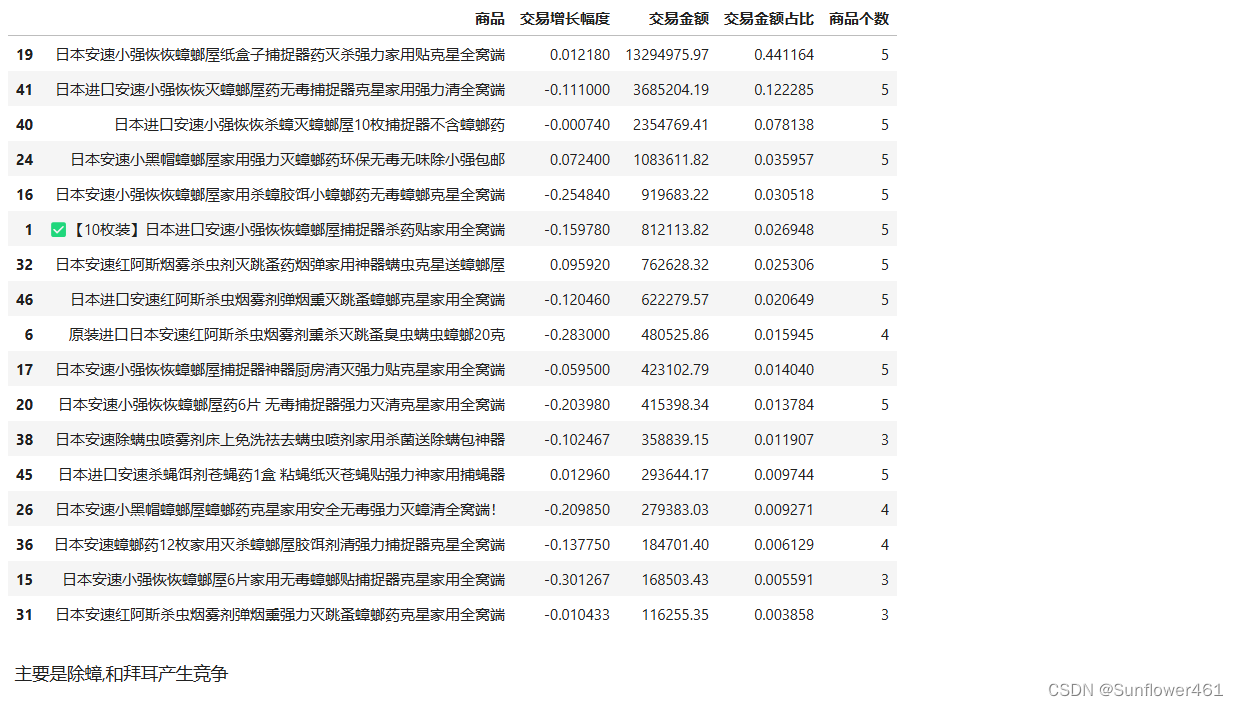
安速问题
anque1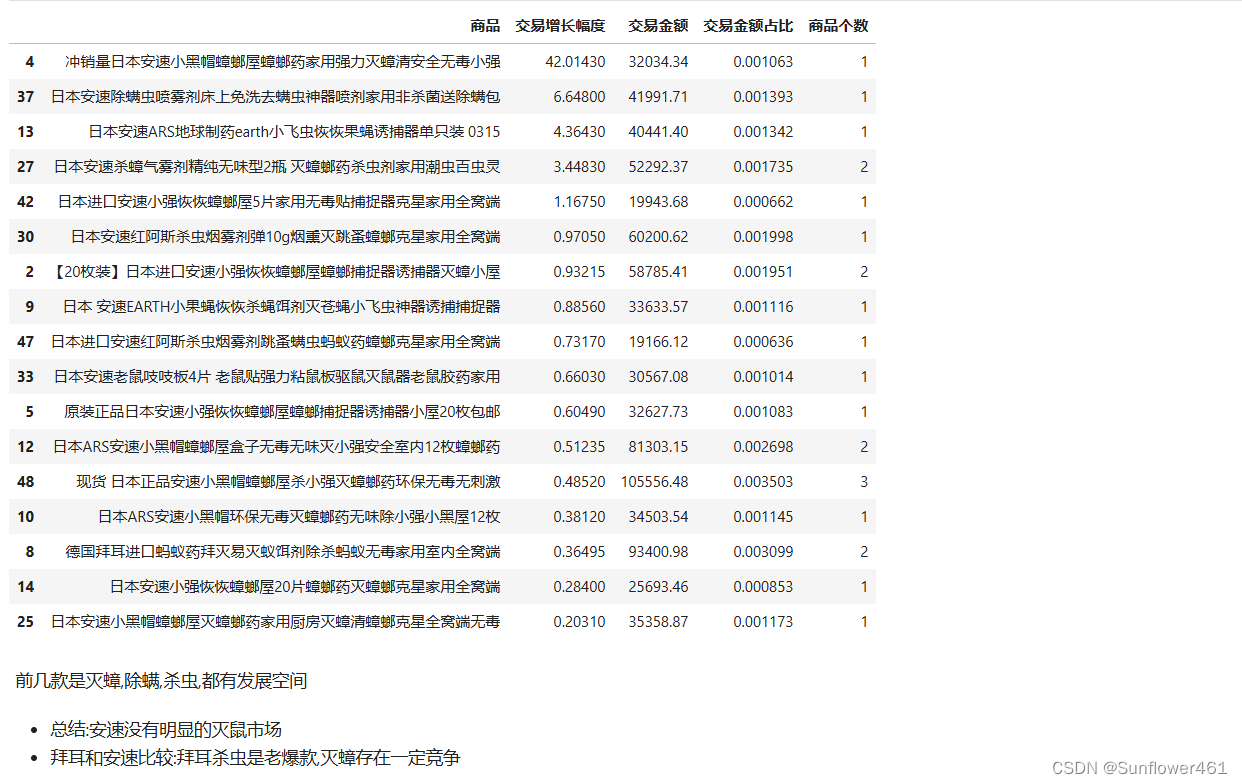
科凌虫控
#读数据
df4kl = pd.read_excel(filenames3[2])
df4kl.head(2)df4kl.info()
df4kl['商品'].value_counts().count()汇总指标
kl4 = byproduct(df4kl)
kl4.describe()#盖帽函数
kl41 = block2(kl4)
kl41.describe()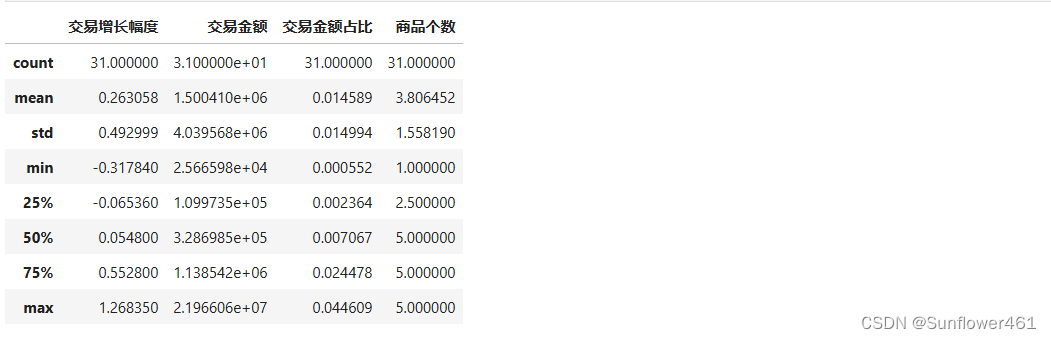 BCG-图
BCG-图
plotBOG(kl41)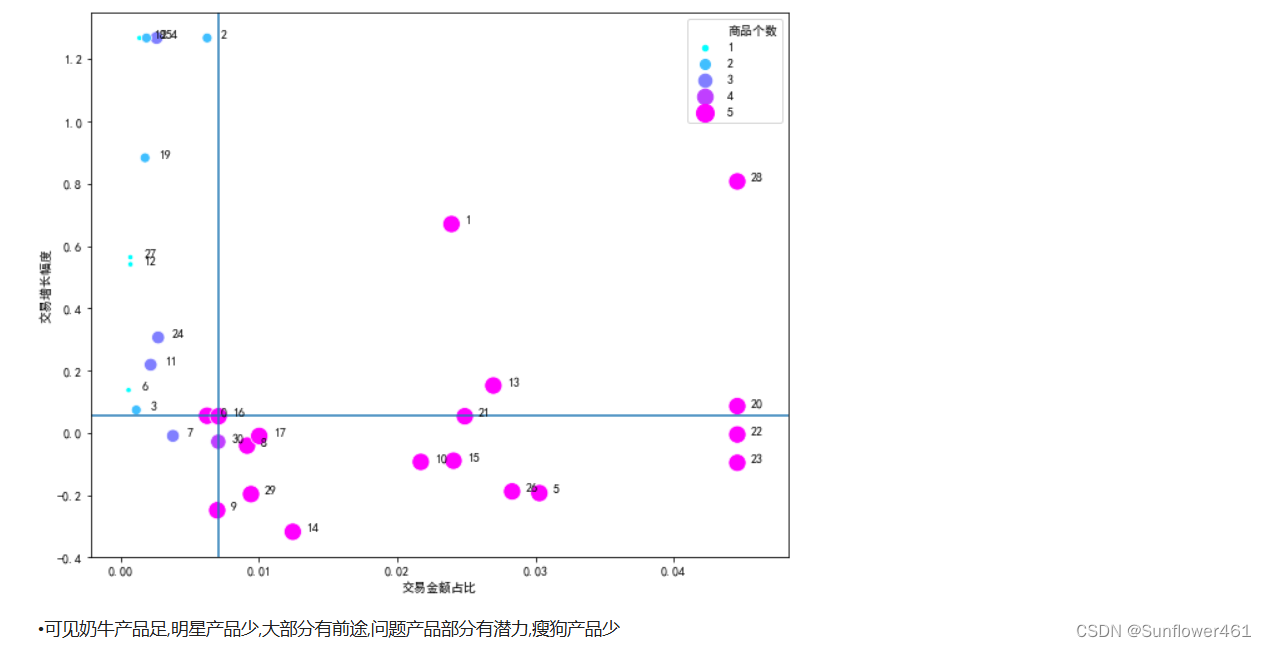
查看具体产品
klstar,klcow,klque = extractBOG(kl4)
klstar1,klcow1,klque1 = extractBOG(kl4,by='交易增长幅度')科凌虫控明星
klstar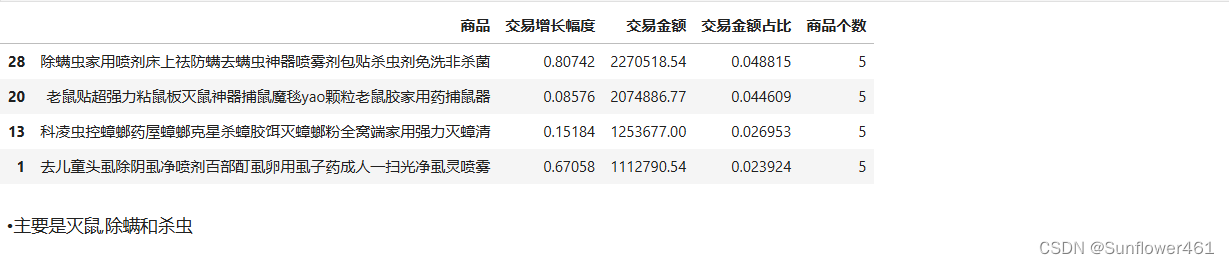
科凌虫控奶牛
klcow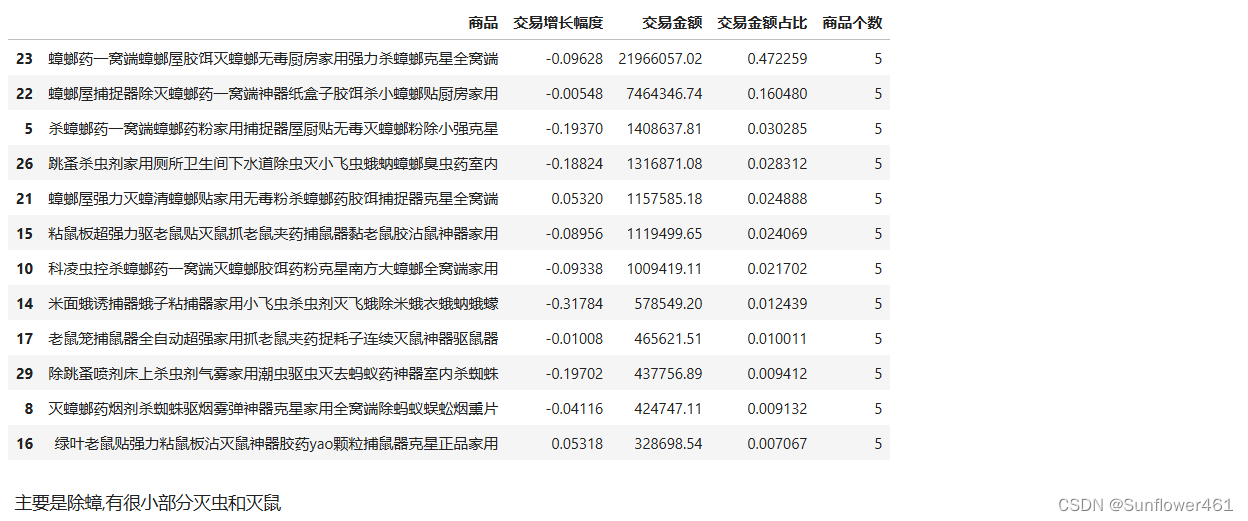
科凌虫控问题
klque1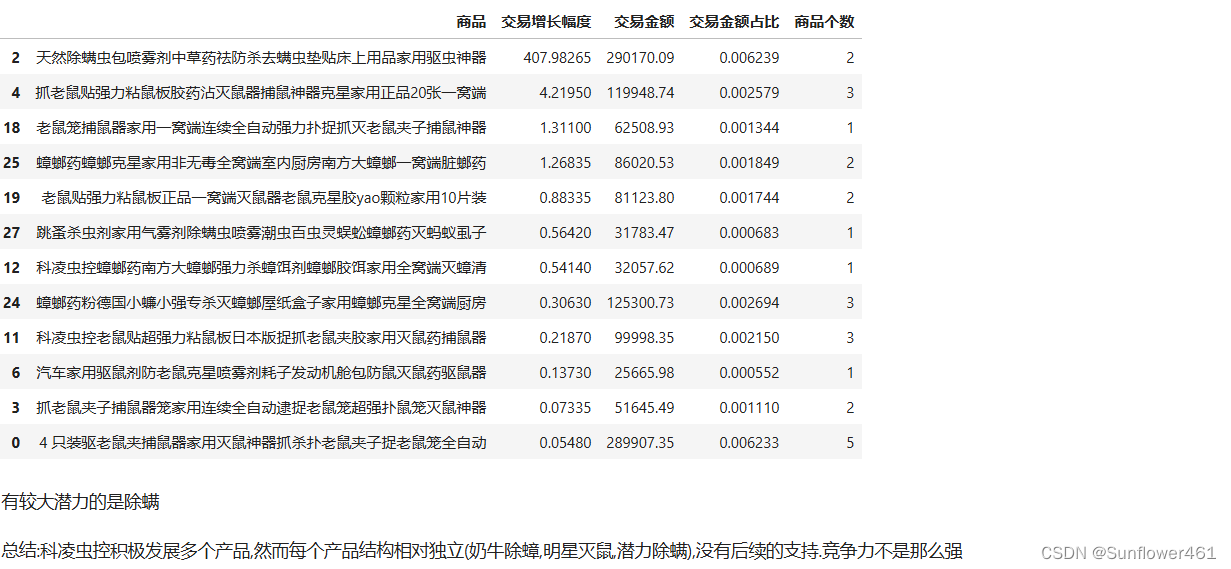
流量结构分析
#数据准备
os.chdir('..')
os.chdir('./流量渠道数据')
filenames4 = glob.glob('*.xlsx')
filenames4
# 自定义流量结构及说明函数
def flow(df):
'''
流量结构及说明函数
'''
df0 = df.copy()
top10 = df0.sort_values('交易指数',ascending=False
).reset_index(drop=True).iloc[:10,:]
top10['交易指数占比'] = top10['交易指数']/top10['交易指数'].sum()
top10.set_index('流量来源',inplace=True)
paid = ['付费流量','直通车','淘宝客','淘宝联盟'] #查得4个付费流量渠道
ind = np.any([top10.index == i for i in paid],axis=0)
explode = ind * 0.1
ax = top10['交易指数占比'].plot.pie(autopct='%.2f%%',
figsize=(5,5),explode=explode)
ax.set_ylabel('')
plt.show()
paidsum = top10['交易指数占比'][ind].sum()
salesum = top10['交易指数'].sum()
paidsale = salesum * paidsum
print(f'前10流量中:\
总交易指数:{salesum:.0f},付费流量占比:{paidsum*100:.2f}%,付费流量带来交易指数:{paidsale:.0f}')
return top10
拜尔
bai5top10 = flow(df5bai)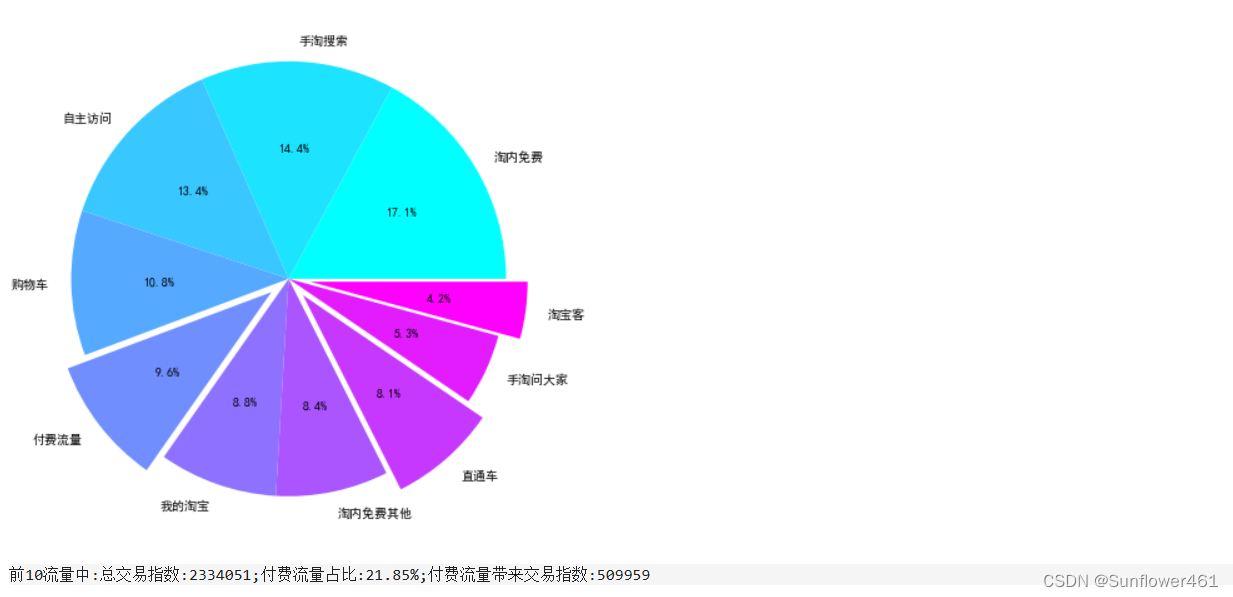
安速
an5top10 = flow(df5an)
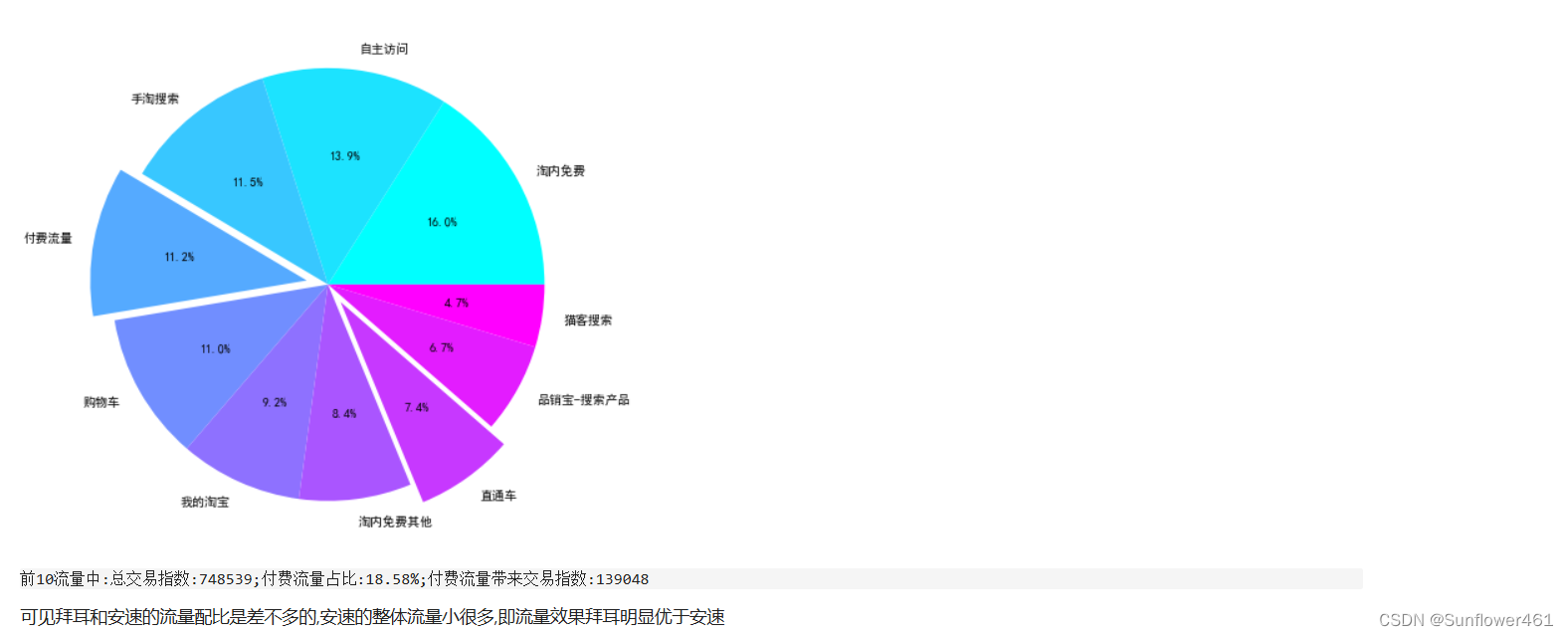
科凌虫控
kl5top10 = flow(df5kl)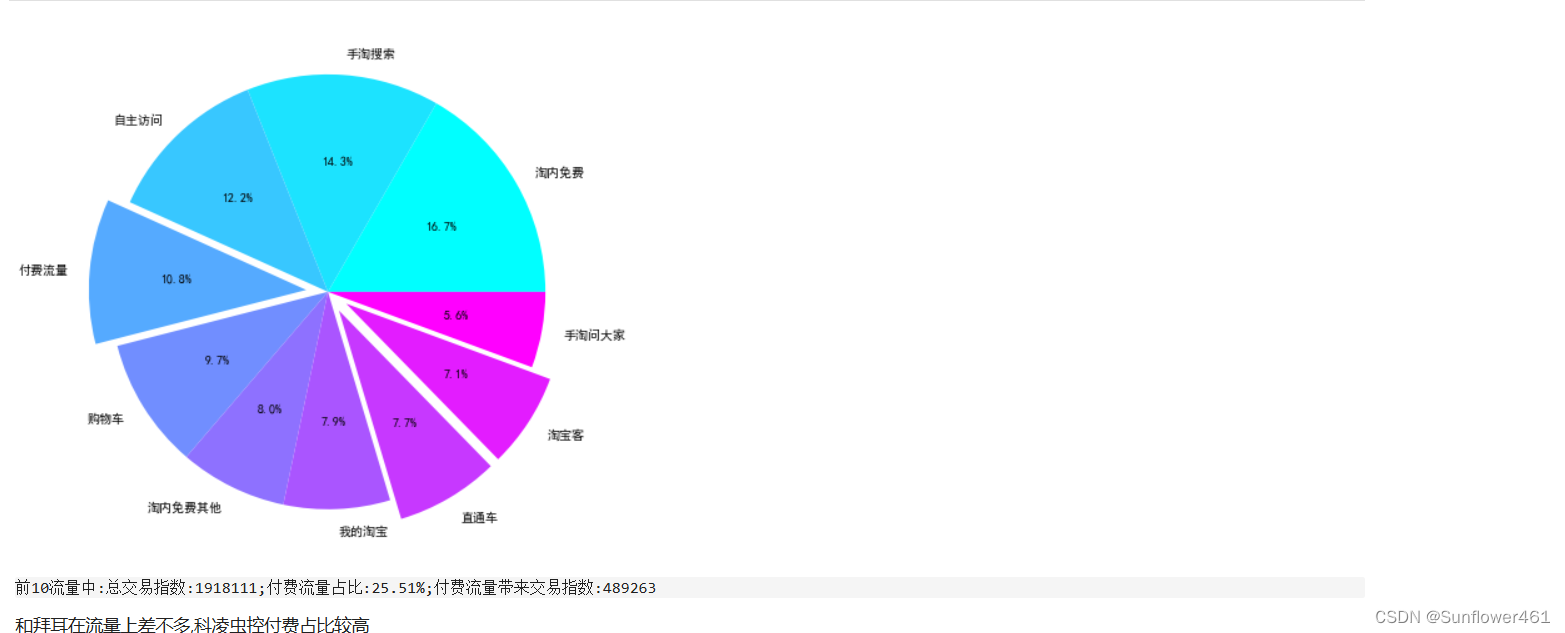
舆情分析
(1)去非中英文(英文应变小写)
(2)分词(jieba/stemming--自定义词典--搜狗词库)
(3)去停用词
(4)去低频词
#数据
os.chdir('..')
os.chdir('./评论舆情数据')
filenames5 = glob.glob('*.xlsx')
df6bai = pd.read_excel(filenames5[1])
df6bai.head()#抽评论列
bai6 = list(df6bai['评论'])
#去掉非英文字符
#\u4E00-\u9Fa5表示汉字unicode编码下的编码范围,多达20892个方块字,5*16*16*16=20480
bai61 = [re.sub(r'[^a-z\u4E00-\u9Fa5]+',' ',i,
flags=re.I) for i in bai6]
#文本处理的库:shorttext
bai61读取构建停用词列表
stopwords = list(pd.read_csv('data/百度停用词表.txt',
encoding='UTF-8',names=['stopwords'])['stopwords'])
stopwords.extend([' '])# 分词函数
def w_cut(df):
df_new = []
for i in df:
seg0 = pd.Series(jieba.lcut(i))
ind3 = pd.Series([len(j) for j in seg0])>1 #筛选出长度大于1的词
seg1 = seg0[ind3]
ind31 = ~seg1.isin(pd.Series(stopwords)) #去停用词并去重
seg2 = list(seg1[ind31].unique())
if len(seg2)>0: #去空列表
df_new.append(seg2)
return df_new
绘制词云图
# 绘制词云图函数
def word_cloud(df):
mask = imageio.imread(r"D:\CDA课件\10月30日 项目1:电商文本挖掘\data\leaf.jpg")
font = r'C:\Windows\Fonts\simkai.ttf'
wc = WordCloud(background_color='white',mask=mask,font_path=font).generate(df)
plt.figure(figsize=(6,8))
plt.imshow(wc)
plt.axis('off')
plt.show()

写出词云图
wc.to_file('E:/learn file/data/拜耳舆情词云.png')基于TF-IDF 算法的关键词抽取
jieba.analyse.extract_tags(bai64,20,True)















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









