






四.mongoDB的学习
1.可视化软件studio 3T的安装
在官网https://studio3t.com/ 下载并解压之后链接数据库
右键新建的连接,选择Add Database新建数据库
我们首先进行了尝试,将豆瓣电影的数据存入mongoDB中
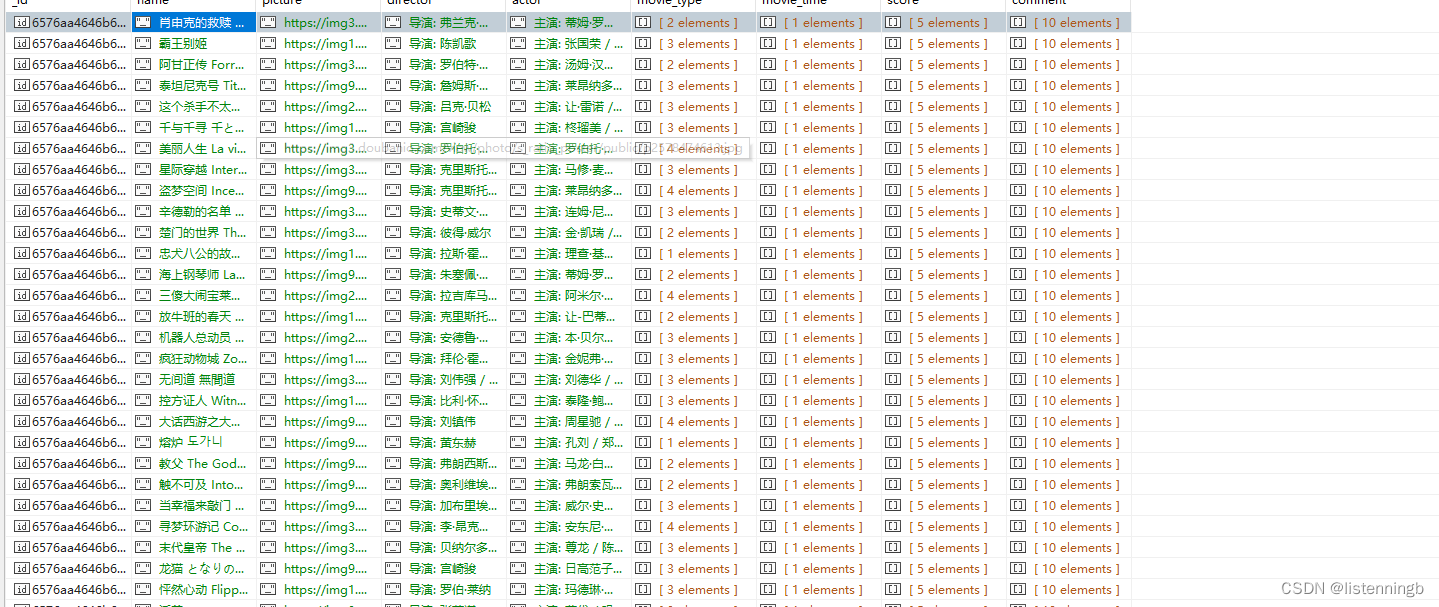
我们发现其体现了传统数据库不具有的灵活的结构,非常适合应用于模型进行分析。
2.mongoDB的CURD
增:插入文档
集合存在则直接插入数据,不存在则隐式创建集合并插入数据
json数据格式要求key得加"",但这里为了方便查看,对象的key统一不加"";查看集合数据时系统会自动给key加""
mongodb会自动给每条数据创建全球唯一的_id键(我们也可以自定义_id的值,只要给插入的json数据增加_id键即可覆盖,但是不推荐这样做)
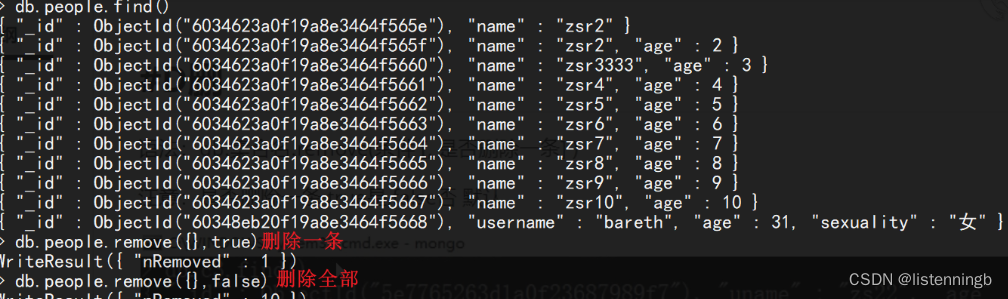
删:删除文档
db.集合名.remove(条件 [,是否删除一条])
# 是否删除一条
- false删除多条,即全部删除(默认)
- true删除一条
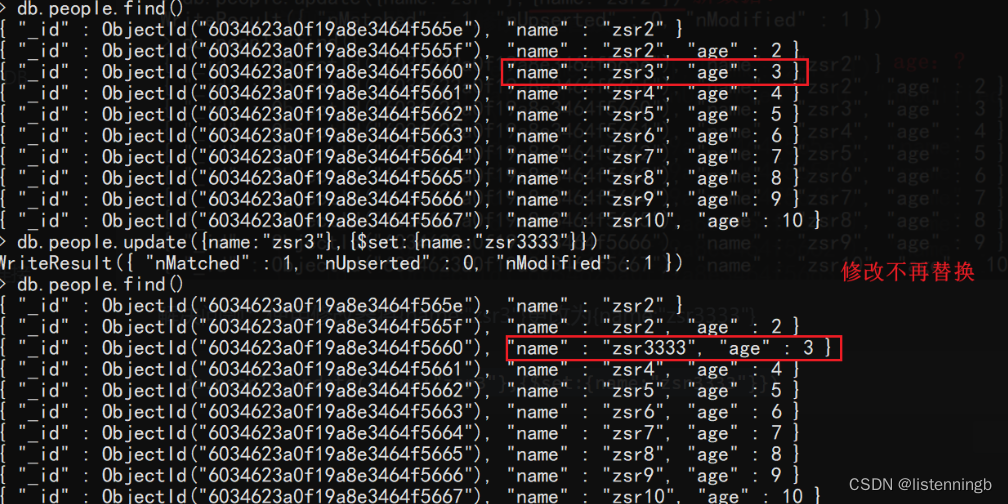
改:修改文档
db.集合名.update(条件, 新数据 [,是否新增, 是否修改多条])
# 新数据
- 默认是对原数据进行替换
- 若要进行修改,格式为 {修改器:{key:value}}
# 是否新增
- 条件匹配不到数据时是否插入: true插入,false不插入(默认)
# 是否修改多条
- 条件匹配成功的数据是否都修改: true都修改,false只修改一条(默认)
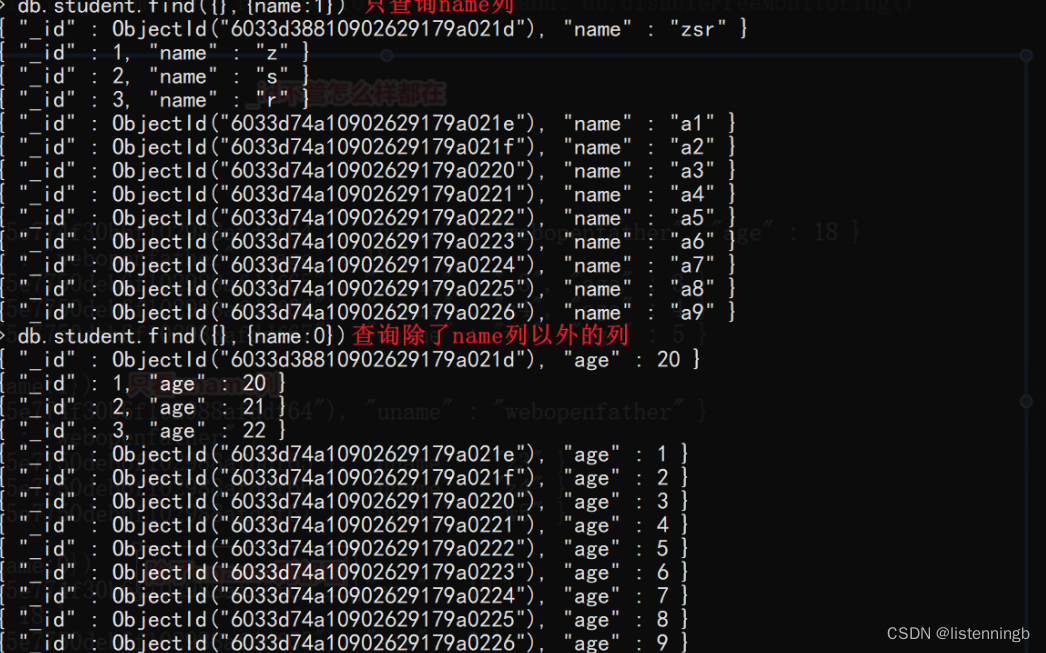
 查:查询文档
查:查询文档
db.集合名.find(条件 [,查询的列])
db.集合名.find(条件 [,查询的列]).pretty() #格式化查看
# 条件
- 查询所有数据 {}或不写
- 查询指定要求数据 {key:value}或{key:{运算符:value}}
# 查询的列(可选参数)
- 不写则查询全部列
- {key:1} 只显示key列
- {key:0} 除了key列都显示
- 注意:_id列都会存在
3.爬虫与mongoDB的结合
根据 使用 Python 进行 MongoDB - MongoDB 文档 给出的使用文档,我们对相应的驱动进行安装,并且我们选择对豆瓣电影进行爬取并分析
import lxml.html
import requests
import re
import time
import random
from pymongo import MongoClient
agent_list = [
"Mozilla/5.0 (Linux; U; Android 2.3.6; en-us; Nexus S Build/GRK39F) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Avant Browser/1.2.789rel1 (http://www.avantbrowser.com)",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5",
"Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/532.9 (KHTML, like Gecko) Chrome/5.0.310.0 Safari/532.9",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/534.7 (KHTML, like Gecko) Chrome/7.0.514.0 Safari/534.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/9.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/10.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.20 (KHTML, like Gecko) Chrome/11.0.672.2 Safari/534.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.27 (KHTML, like Gecko) Chrome/12.0.712.0 Safari/534.27",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24 Safari/535.1",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.120 Safari/535.2",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10"
]
def sleep():
time.sleep(random.uniform(0.3, 0.7))
def download(url):
headers = {
'User-Agent': random.choice(agent_list),
'Cookie': 'll="118220"; bid=cOLD625s7TU; _pk_id.100001.4cf6=c12a1f48017146db.1700708229.; _vwo_uuid_v2=DCF5E63C861AF74210CB935BA36FEEF1D|f2aaaa82b9ca56f7c7775ee1e3c15f55; __utmz=30149280.1702204165.8.5.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; Hm_lvt_16a14f3002af32bf3a75dfe352478639=1700708729,1700890617,1702872032; __utmc=30149280; __utmc=223695111; ap_v=0,6.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1716207005%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D; _pk_ses.100001.4cf6=1; __utma=30149280.966420872.1700708225.1716197037.1716207006.15; __utmt=1; __utmb=30149280.1.10.1716207006; dbcl2="280625416:3vLYDXA1xGo"; ck=IidE; __utma=223695111.2001295825.1700708229.1716197037.1716207040.14; __utmb=223695111.0.10.1716207040; __utmz=223695111.1716207040.14.5.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; push_noty_num=0; push_doumail_num=0'
}
try:
response = requests.get(url=url, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
return response.content.decode('utf-8')
except:
print("爬取失败" + url)
name = []
country = []
picture = []
director = []
actor = []
movie_type = []
movie_time = []
release_time = []
score = []
comment = []
cnt = 0
# f =open(r"C:\Users\48594\Desktop\新建文本文档.txt","w")
for k in range(1):
url_demo = download('https://movie.douban.com/top250?start={}&filter='.format(k * 25))
Links = re.findall('https://movie\\.douban\\.com/subject/[0-9]+/', url_demo)
movie_list = sorted(set(Links), key=Links.index)
for movie in movie_list:
cnt = cnt + 1
url_movie = download(movie)
# print(url_movie)
sleep()
selector = lxml.html.fromstring(url_movie)
for i in range(1):
try:
temp_name = selector.xpath('//div[@id="content"]/h1/span')[0].text_content()
temp_picture = "https://" + \
re.findall('<img src="https://(.*?)" title="点击看更多海报" alt=', url_movie, re.S)[0]
temp_director = selector.xpath('//*[@id="info"]/span[1]')[0].text_content()
temp_actor = selector.xpath('//*[@id="info"]/span[3]')[0].text_content()
temp_movie_type = selector.xpath('//*[@id="info"]/span[@property="v:genre"]/text()')
temp_movie_time = selector.xpath('//*[@id="info"]/span[@property="v:runtime"]/text()')
temp_score = selector.xpath('//span[@class="rating_per"]/text()')
temp_country = re.findall('<span class="pl">制片国家/地区:</span> (.*?)<br/>', url_movie)
temp_release = selector.xpath('//*[@id="info"]/span[@property="v:initialReleaseDate"]/text()')
# f.write(str(temp_name))
# f.write(str(temp_director))
# f.write(str(temp_movie_type))
# f.write(str(temp_movie_time))
# f.write(str(temp_score))
# f.write(str(temp_country))
# f.write("\n")
print(temp_release)
print(temp_name)
# print(temp_director)
# print(temp_actor)
# print(temp_movie_type)
# print(temp_movie_time)
# print(temp_score)
# print(temp_country)
# name.append(temp_name)
# picture.append(temp_picture)
# director.append(temp_director)
# actor.append(temp_actor)
# movie_type.append(temp_movie_type)
# movie_time.append(temp_movie_time)
# score.append(temp_score)
# country.append(temp_country)
break
except:
sleep()
print("子载可爱喵")
url_movie = download(movie)
selector = lxml.html.fromstring(url_movie)
print("++++++++++++Movie-" + str(cnt) + " basic information download finished++++++++++++")
comment_demo = []
for j in range(20):
if j == 0:
movie_comment = movie + 'comments?limit=20&status=P&sort=new_score'
else:
movie_comment = movie + 'comments?start=' + str(j * 20) + '&limit=20&status=P&sort=new_score'
for a in range(10):
try:
sleep()
url_comment = download(movie_comment)
selector_comment = lxml.html.fromstring(url_comment)
temp_comment = selector_comment.xpath('//div[@class="comment"]/p/span/text()')
sleep()
# for temp_comment_content in temp_comment:
# print(temp_comment_content)
comment_demo.append(temp_comment)
break
except:
if j == 0:
movie_comment = movie + 'comments?limit=20&status=P&sort=new_score'
else:
movie_comment = movie + 'comments?start=' + str(j * 20) + '&limit=20&status=P&sort=new_score'
comment.append(comment_demo)
print("-----------Movie-" + str(cnt) + " comment download finished-----------")
client = MongoClient('localhost', 27017)
db = client['WebData']
collection = db['Douban']
for i in range(1):
collection.insert_one(
{"name": name[i], "picture": picture[i], "director": director[i], "release_time": release_time[i],"actor": actor[i], "country": country[i], "movie_type": movie_type[i], "movie_time": movie_time[i],"score": score[i], "comment": comment[i]})
测试后可行。















 673
673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









