






一.数据分析
首先我们对爬虫获取的文本进行分析,我们主要是通过以下几个方面进行分析,首先是数据包含的三个主要字段,分别是instruction、input 和 output。其中instruction包含了描述性的指令信息,即我们在源文本处的标签,该标签允许我们精准的发现我们在进行模型训练时所必须的时间,地点,季节,月份等关键信息,而且其格式也比较统一,因此我们在对文本进行清洗时主要将精力集中在对output部分 ,即文章部分进行清洗。
,即文章部分进行清洗。
1.清洗目标
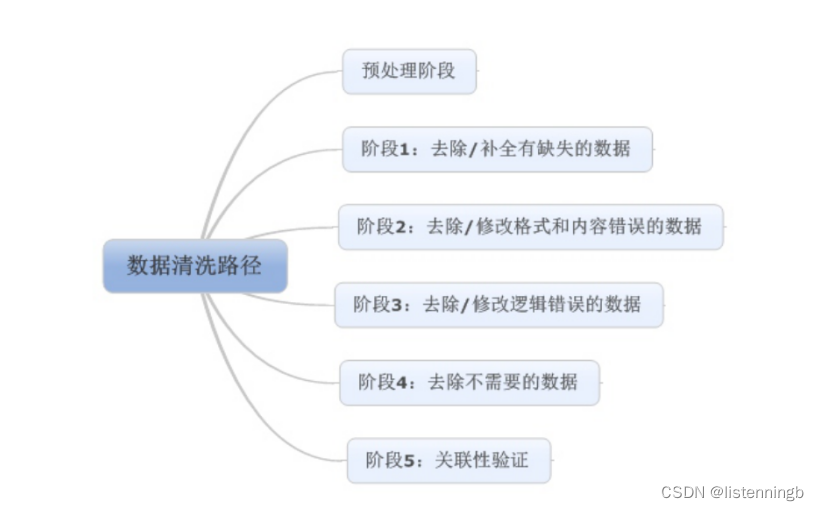
数据清洗洗掉的就是数据库中的“脏”数据。“脏数据”,即数据库中残缺、错误、重复的数据。数据清洗,旨在提高数据的质量、缩小数据统计过程中的误差值。我们通过观察output部分发现,文章中充斥着大量的换行符“/n”和表情符号,以及无意义的系统报错等内容,我们使用python作为处理工具对其进行清洗。将其转化为“”。因此我们首先使用工具去除程序中不需要的字段。


import json
import re
二.清洗过程
1.去除不需要的字段
首先我们导入数据处理所需的库,并进行数据清洗。
emoji_pattern = re.compile(
"["
"\U0001F600-\U0001F64F" # 表情符号
"\U0001F300-\U0001F5FF" # 符号和象形符号
"\U0001F680-\U0001F6FF" # 运输和地图符号
"\U0001F1E0-\U0001F1FF" # 国旗
"\U00002700-\U000027BF" # 其他符号
"\U0001F900-\U0001F9FF" # 补充符号和象形符号
"\U00002600-\U000026FF" # 各种符号
"\U0001F700-\U0001F77F" # 各种符号
"\U00002300-\U000023FF" # 各种符号
"]+", flags=re.UNICODE)这是我们通过分析获得的相关emoji的正则表达式格式,我们通过这个正则表达式匹配所有的常见的表情符号。
# 文件路径
file_path = r'C:\Users\48594\Desktop\深度学习\res\青岛.json'
output_path = r'C:\Users\48594\Desktop\深度学习\cleaned_青岛.json'我们从文章路径中打开相关的文件,并使用json库将读取到的json文件解析为Python字典,并对其进行清洗。
# 清理文本函数
def clean_text(text):
# 去除换行符
text = text.replace('\n', ' ')
# 去除表情符号
text = emoji_pattern.sub(r'', text)
return text接着我们使用定义好的工具去除其中的换行符‘\n’以及表情符号,之后将清洗好的数据保存到一个新的json文件中,之后便可以获得清洗后的数据。
2.数据去重与不必要评论
我们发现在文章中存在着一些评论,有些评论包含着一些有意义的语句,比如对该旅游路线的补充等,但是也有相当一部分存在着无意义或者对我们的项目无意义的语句,比如对人物的评价对拍摄技术的评价,这些对于我们来说是不必要的,因此我们在有能力的情况下可以对其进行适当的筛选与去除。
我们采用与上文相似的方法,首先将文章载入我们的data中再对其进行分析与操作,首先我们根据关键字“评论”将文章分为正文与评论两个部分,之后我们再通过分割将每一条评论独立起来
# 清洗 output 字段
output = data["output"]
# 去除评论信息和冗余部分
# 保留行程安排和简要描述的部分
cleaned_output = []
# 分割段落
paragraphs = output.split("评论")使用这种方法首先将正文与评论独立起来,防止在进行数据清洗操作时误将重要的正文删除导致出现文章无效的现象,之后我们检查每个段落,将文章中存在的关键字进行识别并分行,便于我们在操作时按照天数来进行旅游景点的推荐。
# 检查每个段落
for paragraph in paragraphs:
if "行程安排" in paragraph or "天" in paragraph:
cleaned_output.append(paragraph.strip())# 更新数据
cleaned_data = {
"instruction": cleaned_instruction,
"input": data["input"],
"output": cleaned_output_text
}之后再次更新数据,将清洗完成后的文件再次存入文件中,等待接下来的操作。















 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









