






1.在/x 目录下创建一个test1文件夹
hadoop fs -mkdir /testq
2.在test1文件夹里创建一个file.txt文件
hadoop fs -touchz /test1/file.txt
3.查看根目录下所有文件
hadoop fs -ls -R/
4.将Hadoop根下test1目录中的file,txt文件,移动到根下并重命名为file2.txt
hadoop fs -mv /test1/file.txt /file2.txt
5.将Hadoop根下file2.txt文件复制到test1目录下
hadoop fs -cp /file2.txt /test1
6.在Linux本地/data目录下的data.txt文件,上传到HDFS中的 /test1 目录下
hadoop fs -put .data.data.txt /test1
7.查看Hadoop中/test1目录下的data.txt文件
hadoop fs -cat /test1/data.txt
8.除此之外还可以使用tail方法
hadoop fs -tail /test1/data.txt
tail方法是将文件尾部1K字节的内容输出. 支持-f选项, 行为和Unix中一致
9.查看Hadoop中/test1目录下的data.txt文件大小
hadoop fs -du -s /test1/data/txt
10.text方法可以将源文件输出为文本格式, 允许的格式为zip和TextRecordInputStream.
hadoop fs -text /test1/data.txt
11.stat方法可以返回指定路径的统计信息, 有多个参数可选, 当使用-stat选项但不使用format的时候,纸打印文件创建日期,相当于%y
hadoop fs -stat /test1/data.txt
12.将Hadoop中/test1目录下的data.txt文件, 下载到Linux本地/apps目录中
hadoop fs -get /test1/data.txt /apps
13.使用chown方法,改变Hadoop中/test1目录中的data.txt文件拥有者为root, 使用-R将改变在目录结构下递归进行
hadoop fs -chown /test1/data.txt
14.使用chmod 方法, 赋予Hadoop中/test1目录中的data.txt文件777权限
hadoop -fs chmod 777 /test1/data.txt
15. 删除Hadoop根下的file2.txt文件
hadoop fs -rm /file2.txt
16.删除Hadoop 根下的test1目录
hadoop fs -rm -r /test1
17.当在Hadoop中设置了回收站功能时, 删除的文件会保留在回收站中,可以使用expunge方法清空回收站
hadoop fs -expunge
18.使用Shell命令执行Hadoop自带的WordCount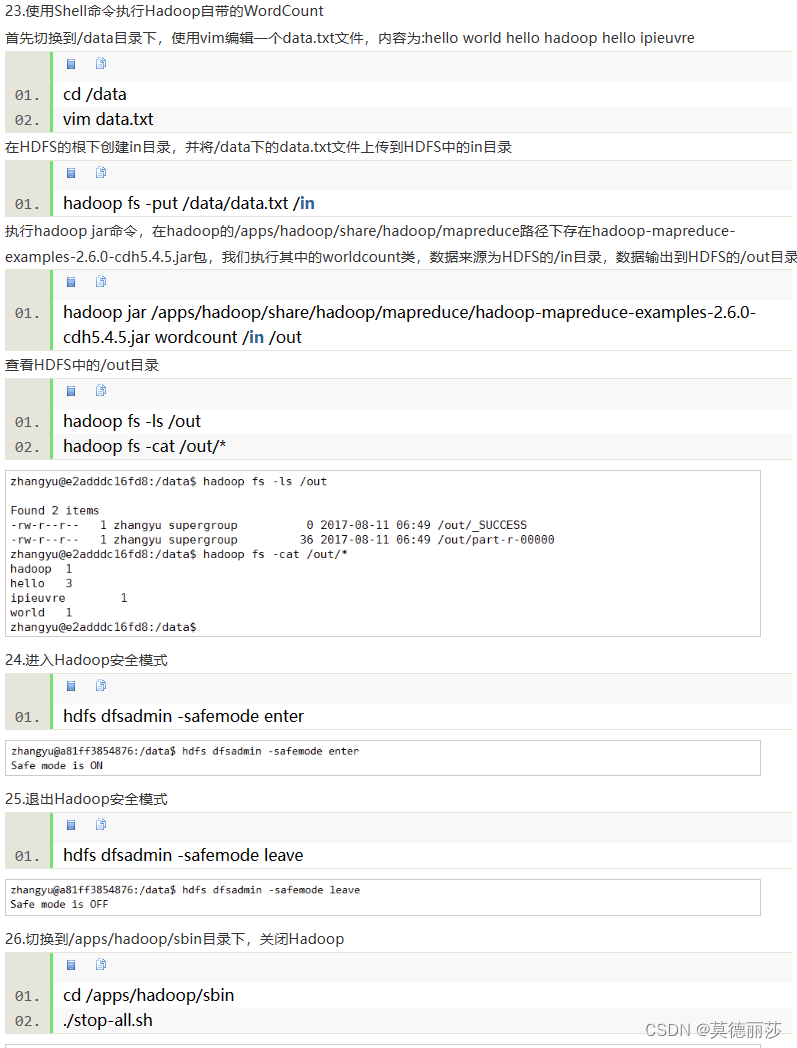















 1877
1877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









