







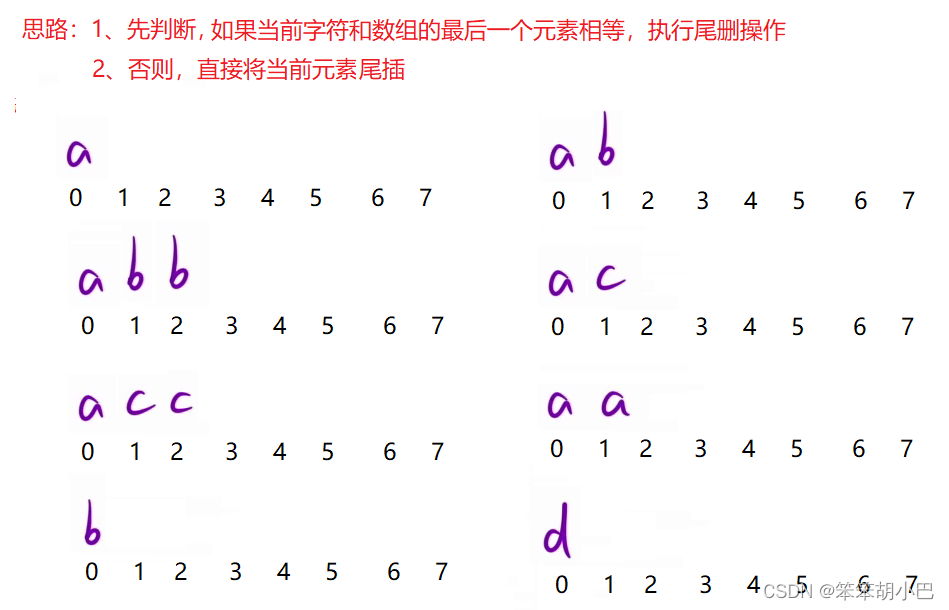
1.删除字符中的所有相邻重复项

这个题目很有乐趣,解决这道题目我们对这个字符串要纵向看它,此时如果相邻的字符相同,比如我们上面的[b]和[b],我们就可以把它消灭,然后这两个被消除的字符的上面字符[a]往下掉落,然后这个字符又有相邻相同的字符[a],我们又可以它消灭,很像我们玩过的开心消消乐游戏,只不过我们这里的是两个字符相同就满足消消乐,回归本题,既然要纵向看它,此时我们的数据结构就只有栈符合这个条件,当前元素是否被消除,需要知道上⼀个元素的信息,可以⽤栈来保存信息。直接上思路

但是,如果使⽤ stack 来保存的话,最后还需要把结果从栈中取出来,并且还要进行一次逆序,不如直接⽤数组模拟⼀个栈结构:在数组的尾部尾插尾删,实现栈的进栈和出栈。那么最后数组存留的内容,就是最后的结果。
class Solution {
public:
string removeDuplicates(string s) {
string ret;//使用string来模拟栈
for(int i = 0; i < s.size(); i++)
{
if(!ret.empty() && s[i] == ret.back())
{
ret.pop_back();//出栈
}
else
{
ret.push_back(s[i]);//入栈
}
}
return ret;
}
};2.比较含退格的字符串

由于退格的时候需要知道前⾯元素的信息,⽽且退格也符合后进先出的特性。因此我们可以使⽤栈结构来模拟退格的过程。其实这道题目和上一道题目的思路是一样的,我们可以把[#]当中和前一个字符相同来处理,利用栈这个数据结构来解决这个问题,但是没必要使用栈,我们依然可以使用一个数组来模拟这个栈,直接上思路:

class Solution {
public:
bool backspaceCompare(string s, string t)
{
return changeStr(s) == changeStr(t);
}
string changeStr(string& s)
{
string ret; // ⽤数组模拟栈结构
for(char ch : s)
{
if(!ret.empty() && ch == '#')
ret.pop_back();
else
ret.push_back(ch);
}
cout << ret << endl;
return ret;
}
};但是此时我们发现代码并没有通过,为什么呢?因为此时第一个字符就是'#'呢?此时数组不为空,我们把'#'也插入到数组中了,所以此时会有问题。

class Solution {
public:
bool backspaceCompare(string s, string t)
{
return changeStr(s) == changeStr(t);
}
string changeStr(string& s)
{
string ret; // ⽤数组模拟栈结构
for(char ch : s)
{
if(!ret.empty() && ch == '#')
ret.pop_back();
else if(ch != '#')//细节:字符不为'#'我们才插入
ret.push_back(ch);
}
cout << ret << endl;
return ret;
}
};3.基本计算器 II

首先,我们要仔细看题目给出的信息,总结一下:
- ⭐只有「加减乘除」四个运算;
- ⭐没有括号;
- ⭐并且每⼀个数都是⼤于等于 0 的;
这样可以⼤⼤的「减少」我们需要处理的情况。关于计算器一类的问题,我们都可以利用栈的思路来模拟计算过程来解决,直接上思路:

操作流程:
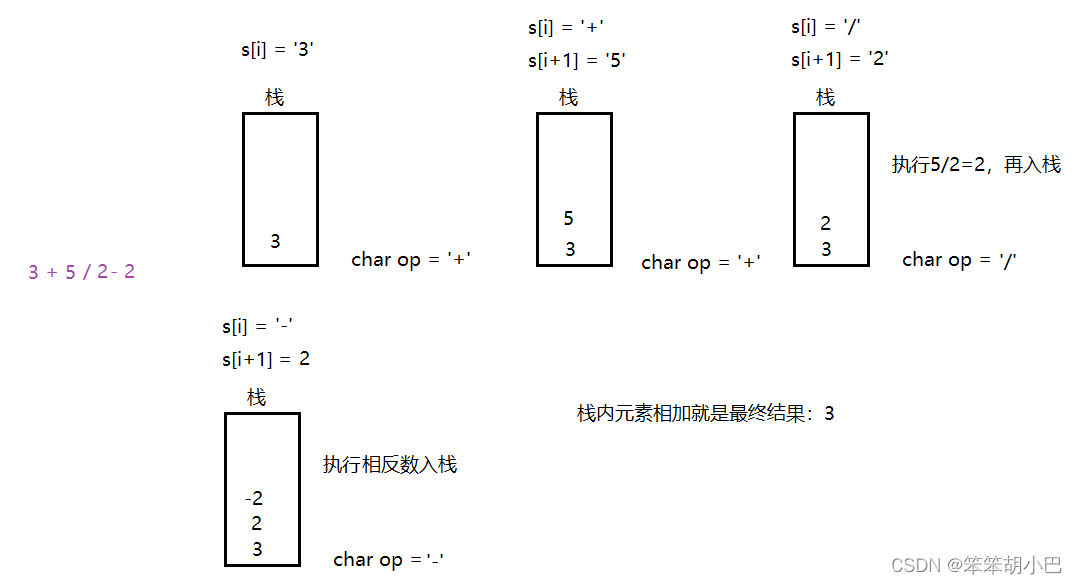
这道题目也不用真的使用栈操作,我们直接拿数组操作也是可以的。
class Solution
{
public:
int calculate(string s)
{
vector<int> st; // ⽤数组来模拟栈结构
int i = 0, n = s.size();
char op = '+';
while (i < n)
{
if (s[i] == ' ') i++;
else if (s[i] >= '0' && s[i] <= '9')
{
// 先把这个数字给提取出来
int tmp = 0;
while (i < n && s[i] >= '0' && s[i] <= '9')
tmp = tmp * 10 + (s[i++] - '0');
if (op == '+') st.push_back(tmp);
else if (op == '-') st.push_back(-tmp);
else if (op == '*') st.back() *= tmp;
else st.back() /= tmp;
}
else
{
op = s[i];
i++;
}
}
int ret = 0;
for (auto x : st) ret += x;
return ret;
}
};4.字符串解码

首先我们看到这个题目,我们并不知道怎么去做,所以我们就可以来模拟一下
string:3[ab2[cd]] -> 3[abcd cd] -> abcdcd abcdcd abcdcd当我们遍历到3时,此时不知道后边的情况,此时我们就继续往扫描,一直扫描到d的时候,还是不知道后边的情况,所以我们就继续扫描,当我们扫描到一个右括号时就可以解码了,这说明先扫描的不能操作,先要保存起来,当符合条件的时候,我们再将最近的元素操作,这不就是符合栈的先进先出的特点吗?所以我们需要先解码内部的,再解码外部。
上面例子中,在解码 cd 的时候,我们需要保存 3 ab 2 这些元素的信息,并且这些信息使⽤的顺序是从后往前,正好符合栈的结构,因此我们可以定义两个栈结构,⼀个⽤来保存解码前的重复次数 k (左括号前的数字),⼀个⽤来保存解码之前字符串的信息(左括号前的字符串信息)。
直接上思路:


come up!直接来上手代码。。。
class Solution {
public:
string decodeString(string s) {
stack<string> st_string;
stack<int> st_int;
// 细节:防止栈顶元素不存在,先加入一个空串
st_string.push("");
int i = 0, n = s.size();
while(i < n)
{
if(s[i] <= '9' && s[i] >= '0')
{
int tmp = 0;
// 此时可以不用判断i < n,因为数字后面一定有字符
while(s[i] <= '9' && s[i] >= '0')
{
tmp = tmp * 10 + (s[i] - '0');
i++; // 走到下一个位置
}
st_int.push(tmp);
}
else if(s[i] == '[')
{
// 取出后面的字符,需要跳过当前位置
i++;
string tmp;
// 此时可以不用判断i < n,因为'['后面一定有字符
while(s[i] <= 'z' && s[i] >= 'a')
{
tmp += s[i];
i++;
}
st_string.push(tmp);
}
else if(s[i] == ']')
{
// 分别取出两个栈的栈顶元素
string tmp = st_string.top();
st_string.pop();
int k = st_int.top();
st_int.pop();
while(k--)
{
st_string.top() += tmp;
}
i++;
}
else
{
string tmp;
// 此时可以判断i < n,因为字母后面可能没有字符
while(i < n && s[i] <= 'z' && s[i] >= 'a')
{
tmp += s[i];
i++;
}
st_string.top() += tmp;
}
}
return st_string.top();
}
};5.验证栈序列

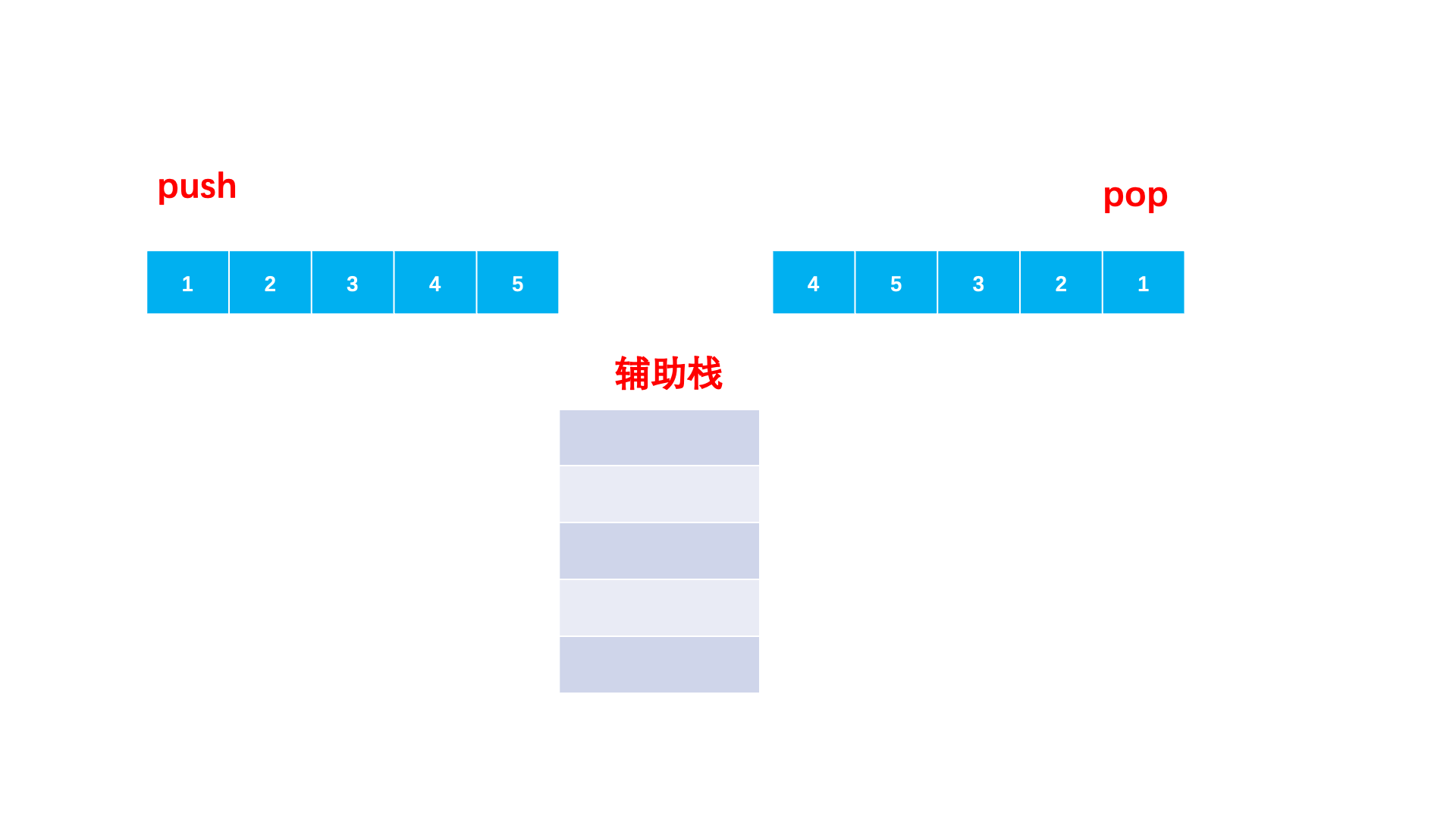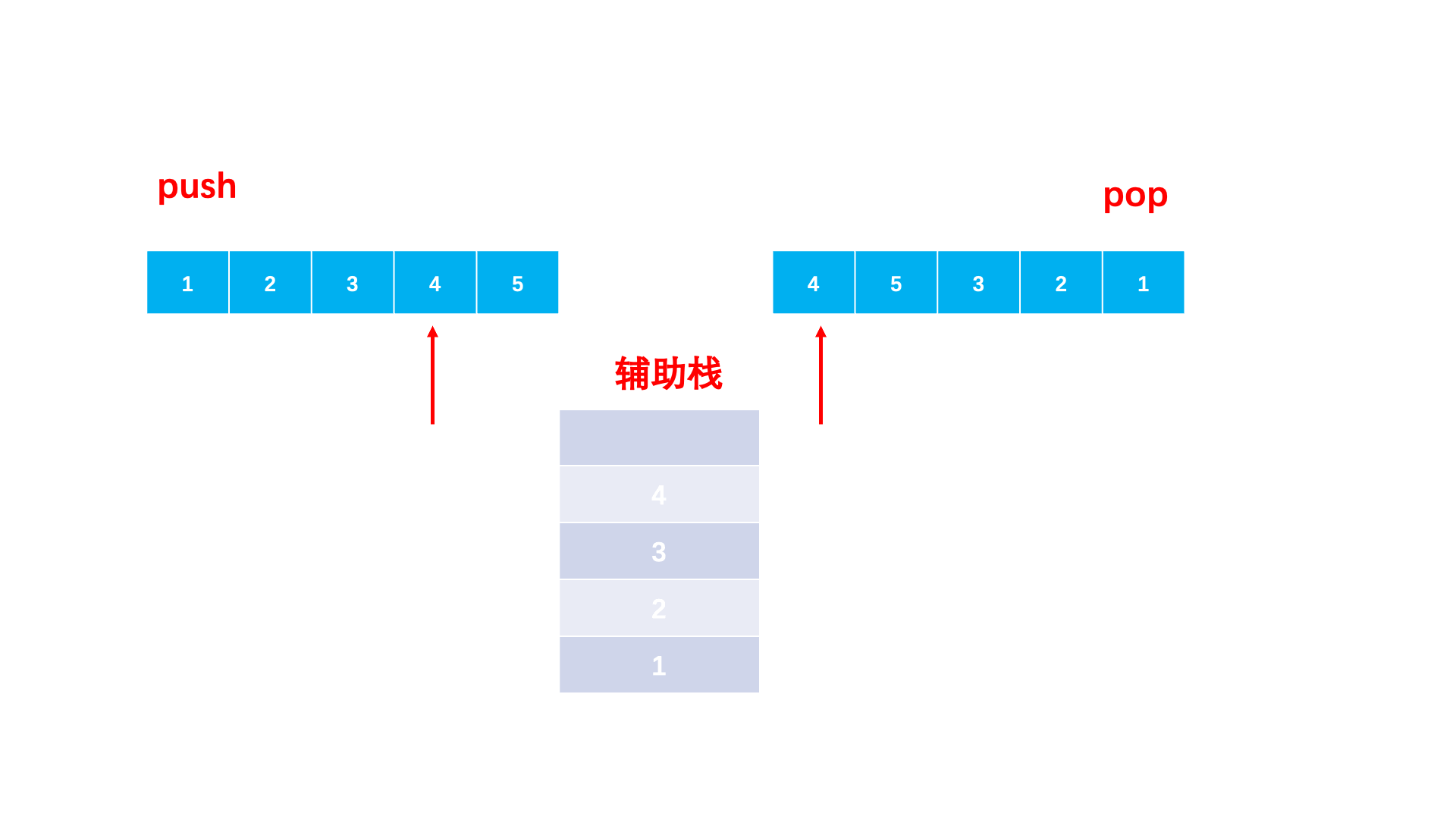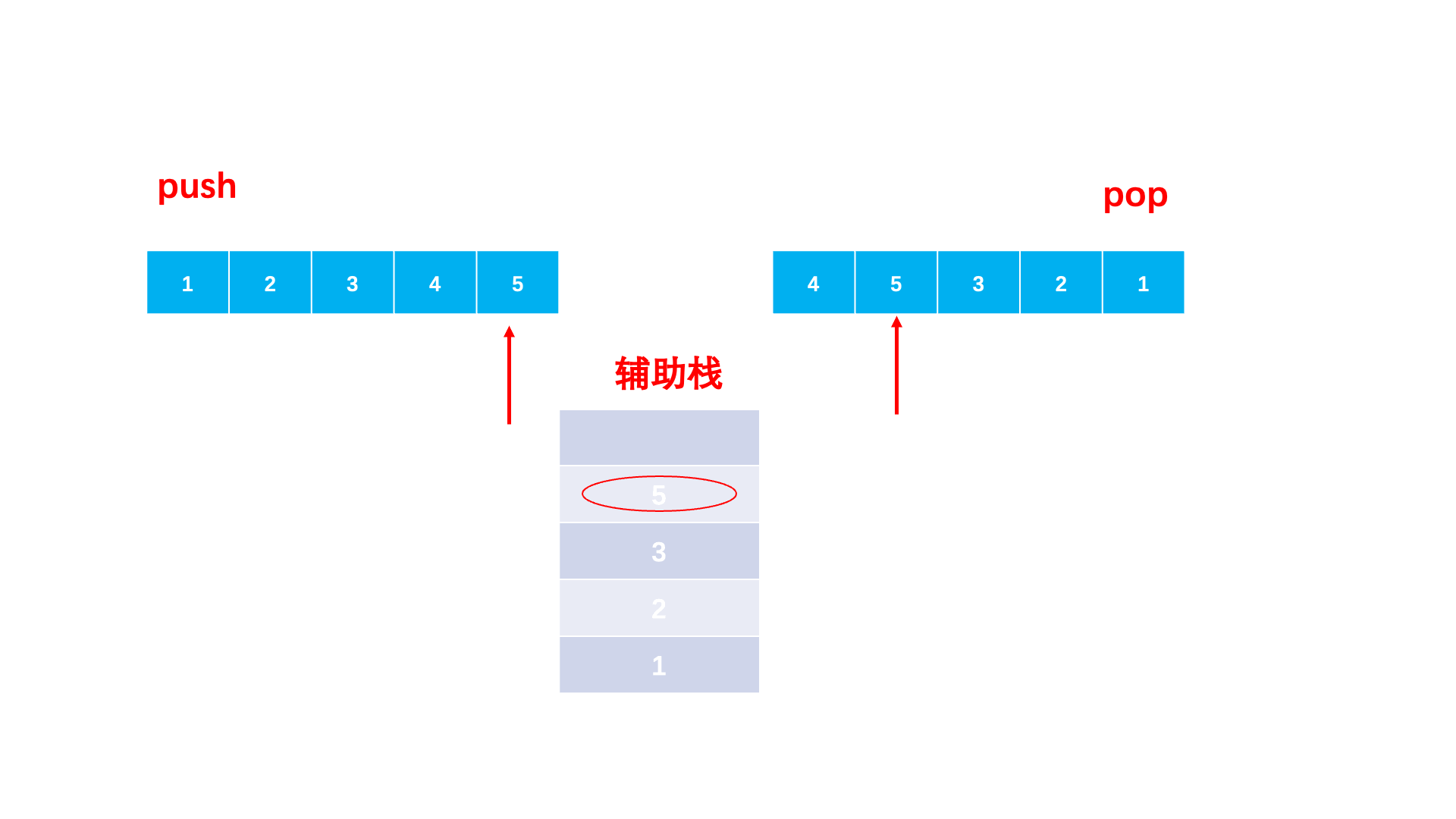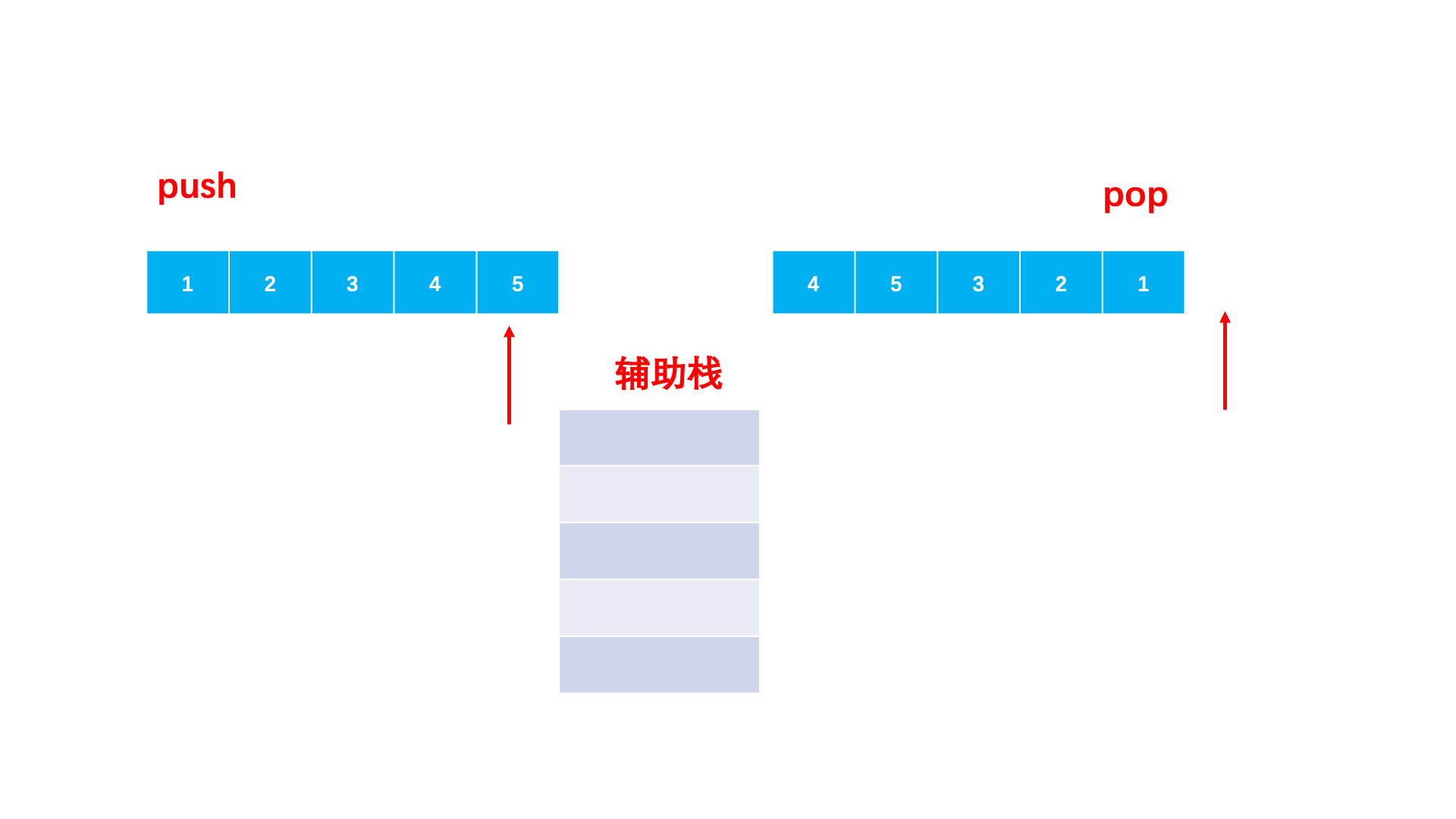
解题思路:题目要我们判断两个序列是否符合入栈出栈的次序,我们就可以用一个栈来模拟。对于入栈序列依次入栈。那什么时候出来呢?自然是遇到一个元素等于当前的出栈序列的元素,那我们就让它出栈。当所有元素模拟完毕之后,如果栈中还有元素,那 么就是⼀个⾮法的序列。否则,就是⼀个合法的序列。
💡强调一下:我们这里不是拿的入栈序列和出栈序列依次比较,而是构建一个辅助栈,让的入栈序列再次入栈,然后再比较的!!!因为我们是想判断出栈顺序是否匹配,且中途有元素出栈,所以需要入栈序列入栈来模拟出栈过程。
上思路:

图解:
class Solution{
public:
bool validateStackSequences(vector<int>& pushed, vector<int>& popped) {
stack<int> st;
int i = 0, n = popped.size();
for(auto x : pushed)
{
st.push(x);
while(!st.empty() && st.top() == popped[i])
{
st.pop();
i++;
}
}
return i == n;
}
};















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









